

مانند مثال قبل در درس دادهکاوی چیست؟، فرض کنید مدیریتِ یک بانک را برعهده دارید که ۱۰۰ هزار مشتری دارد و میخواهید به یک سری از مشتریانِ خود وام دهید. طبیعتاً به افرادی وام را خواهید داد که شانسِ برگرداندن وام توسط آنها بیشتر باشد. هر کدام از این افراد نیز، دارای خصوصیات مختلفی هستند (ویژگیهای آنها). برای مثال، آیا این شخص خانه دارد یا نه؟ این شخص دارای اتومبیل شخصی هست یا خیر؟ حقوق دریافتیِ این شخص چقدر است؟ و… .
حال فرض کنید این بانک دارای یک سابقهی ۱۰ هزار تایی از مشتریانی است که وام گرفتهاند که یا توانستهاند برگردانند یا خیر. این افراد به دو دسته (۲ کلاس) تقسیم شده اند، یا توانسته اند وام خود را بازگردانند (کلاسِ ۱) یا خیر (کلاسِ ۲). همان طور که گفتیم این افراد خصوصیات یا ویژگیهای مختلفی داشتهاند. پس نگاهی به جدول زیر بیندازید:
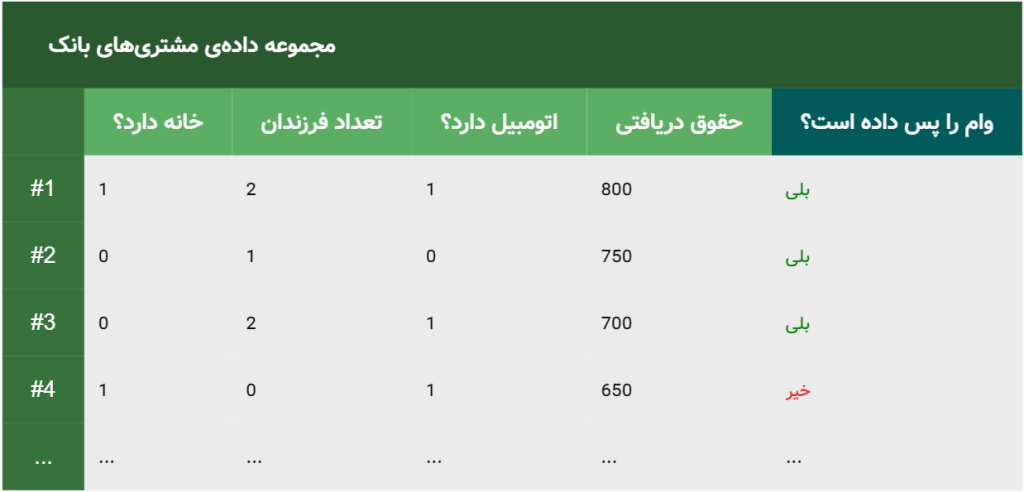
تفسیر این جدول که نوعی ماتریس نیز هست، ساده است. همانطور که مشاهده میکنید، شخصِ شمارهی ۱، دارای منزل است، تعداد ۲فرزند دارد، حقوق ماهیانه معادل ۸۰۰ هزار تومان دارد و یک اتومبیل از خود دارد. در ستون آخر (ستون برچسب یا lable) مشاهده میکنید که این شخص توانسته وام خود را برگرداند. شخص شماره ۲ و ۳ هم به همین ترتیب است یعنی توانستهاند وامِ خود را برگردانند. ولی شخصِ شمارهی ۴، با ویژگیهایی که دارد، نتوانسته وام دریافتیِ خود را بازگرداند. این سه مورد از ۱۰ هزار مشتریِ مختلفی است که در پایگاه دادهی بانک ذخیره شدهاند.
همانطور که مشاهده میکنید، در جدولِ بالا (که در دادهکاوی به ماتریس معروف است)، هر سطر نمایشگرِ یک فرد خاص است. به این فرد خاص، یک رکورد یا یک نمونه یا یک sample یا یک tuple گفته میشود. و هر ستون نمایشگرِ یک ویژگی یا همان feature است. به ویژگیها در دادهکاوی اصطلاحاً بٌعد (dimension) نیز گفته میشود. مثلاً دادههای موجود در تصویرِ بالا، ۴بعدی است چون ۴ ویژگی (ستون) دارد. توجه کنید که ستونِ آخر، ستونِ برچسبها یا همان lableهای ماست که مشخص میکند یک نمونهی خاص، در هر سطر به کدام دسته (class) تعلق دارد. در این مثال ما ۲ دسته یا ۲ طبقه (class) داریم. کسانی که وام خود را پس دادهاند، و کسانی که وام خود را پس نداده.اند.
به طور کلی به مسئلههایی که ستون طبقه یا class را داشته باشند، مسائل طبقهبندی یا classification گفته میشود. این دست از مسائل به یاگیریِ با ناظر (supervised learning) نیز معروف هستند، چون در واقع یک ناظر وجود دارد که ستون آخر را برای ما برچسبزنی کند (مثلاً در اینجا مدیر بانک، تعدادی مشخصی از مشتریان را برای ما برچسب زده است).
الگوریتمهای یادگیری ماشین و دادهکاوی که عملِ طبقهبندی را انجام میدهند (مانند SVM، Random Forest، Naive Bayes و…) میتوانند این جدول یا همان ماتریس را به عنوانِ ورودی قبول کنند و از این ماتریس و ویژگیهای آن، الگوی موجود در هر طبقه یا class را یاد بگیرند. سپس اگر یک نمونهی جدید (مثلاً یک مشتریِ جدید) – که طبقهی آن را نمیدانیم – به الگوریتمی که یادگرفته است داده شود، این الگوریتم میتواند این نمونهی جدید را به طبقههای احتمالاً درست (که قبلا دیده است) طبقهبندی یا classification کند. مثلاً یک مشتریِ جدید با ۴ ویژگی، به الگوریتم داده میشود، و الگوریتم میتواند با توجه به داده هایی که یادگرفته است پیشبینی کند که این مشتریِ جدید میتواند وام خود را پس دهد یا خیر؟

- ۱ » دادهکاوی (Data mining) چیست؟
- ۲ » یادگیری ماشین (Machine Learning) چیست؟
- ۳ » تفاوت هوش مصنوعی، یادگیری ماشین، دادهکاوی، یادگیری عمیق و علم داده
- ۴ » طبقهبندی (Classification) چیست؟
- ۵ » خوشهبندی (Clustering) چیست؟
- ۶ » تفاوت طبقهبندی (Classification) و خوشهبندی (Clustering)
- ۷ » منظور از دادههای آموزشی (Training Sets) در طبقهبندی چیست؟
- ۸ » سیستم توصیه گر (Recommendation System) چیست؟
- ۹ » کاربرد دادهکاوی و یادگیری ماشین در پردازش متن (Text Processing)
- ۱۰ » معرفی چند نرم افزار کاربردی برای عملیات دادهکاوی
- ۱۱ » ویژگی (Feature) یا همان بُعد (Dimension) در دادهکاوی چیست؟
- ۱۲ » بررسی چند الگوریتم یادگیری ماشین (Machine Learning)
- ۱۳ » یادگیری دستهای (Batch Learning) و یادگیری برخط (Online Learning)
- ۱۴ » یادگیری فعال (Active Learning) در یادگیری ماشین
- ۱۵ » انتخاب ویژگی (Feature Selection) چیست؟
- ۱۶ » تفاوت داده ساختاریافته (Structured) با غیرساختاریافته (Unstructured) چیست؟
- ۱۷ » منظور از متغیر وابسته (Dependent) و مستقل (Independent)
- ۱۸ » مجموعه دادههایی با ابعاد زیاد (High Dimensional)
- ۱۹ » مجموعه دادهی نامتوازن (Imbalance) چیست؟
- ۲۰ » فرآیند کریسپ (CRISP) جهت انجام پروژههای دادهکاوی
- ۲۱ » رانش یا گذار در دادهها (Data Drift)
عااااااالی بود .توضیحاتتون خیلی خوبه
شما عالی خوندین سرکار خانم
عالی بود
خیلی ازتون ممنونم. معلومه این متن رو کسی نوشته که عمیقا داده کاوی و یادگیری ماشین رو بلده. همین باعث میشه هر فردی با هر تخصص غیر مرتبطی کاملا این مباحث رو بفهمه.
عالی بود ممنون
بسیا عالی بود با این من درس داده کاوی رو پاس کردم اما این توضیحات بیشتر مفید بود.به امید موفقیت های بیشتر برای شما
بسیار عالی موفق باشید همیشه
بسیار عالی .موفق باشید
بسیار عالی .موفق باشید
خیلی خوب و روان توضیح داده شده بود.
ممنون
واقعا ممنون . خیلی آموزشاتون عالیه . لطفا باز هم ادامه بدین.
عااااااالی بود . ممنونم
واقعاً ممنون. بسیار کوتاه و بسیار مفید. به طوری که باعث شد با صرف کمترین انرژی و در حداقل زمان این موضوع رو تا حد بسیار زیادی درک کنم و متعاقباً در فهم مسائل بعدی من رو کمک کنه.
از شما به خاطر بیان واضح و کاربردیتون سپاسگزارم
با سلام بسیار عالی. خیلی روان توضیح داده اید و من واقعا ممنونم از شما.
سلام ممنون از توضیحات عالی تون🙏
جز اولین منابع پر و عالی فارسی بودین…
خیلی عالی بود… موضوع پایان نامم یادگیری ماشین عه در حالیکه رشتم هیچ ارتباطی به برق و کامپیوتر نداره! و باید همه چیو از پایه یاد بگیرم…
ممنون واقعا
خیلی هم عالی
با سلام .
واقعا مطالبتون عالی بود و استفاده کردم . موفق باشید
سایت شما واقعا عالی ساده و کاربردی است تشکر از زحمات شما
سلام
توضیحاتتون عالیه
اونجایی که نوشتین:
“به طور کلی به مسئله هایی که ستون آخر(ستون طبقه یا Class) را داشته باشند، مسائل طبقهبندی یا Classification گفته می شود. ”
مگه Regression هم این خاصیت رو نداره؟ مثلا پیشبینی آب و هوا ستون آخر دمای هوا هست.
مرسی
بله
Regression هم یک نوعی از یادگیری با ناظر هست که به جای Class، در ستون آخر، یک عدد پیوسته قرار میگیرد
بنظرم خیلی عالی بود
خیلی ممنون خیلی خوب توضیح داده بودید