

در دروس گذشته یادگرفتیم که چگونه با استفاده از ماتریس اغتشاش (Confusion Matrix) و معیارهایی مانند دقت (Accuracy)، صحت (Precision) و معیار F1، کیفیت یک الگوریتمِ طبقهبندی را مشخص کنیم. در این درس به یکی دیگر از این معیارها به نام امتیاز کاپا (Kappa Score) که به معیار Cohen’s Kappa نیز معروف است میپردازیم. خواهیم دید که این معیار یک معیار مناسب، برای ارزیابی کیفیت الگوریتمهای طبقهبندی چند کلاسه است.
از درسِ ماتریس اغتشاش، به یاد دارید که قبل از شروع محاسبهی معیارهای ارزیابی، بایستی این ماتریس را طراحی کنیم. در این درس نیز نیاز به طراحی همچین ماتریسی داریم ولی با این تفاوت که در معیار کاپا، به راحتی میتوانیم چندین کلاسِ مختلف را در یک ماتریس داشته باشیم (بر خلاف ماتریس اغتشاشِ ساده که فقط دو کلاس را پوشش میداد). با استفاده از این ماتریس، معیار کاپا، الگوریتم طبقهبندی ما را با یک الگوریتمِ طبقهبندی تصادفی مقایسه میکند و به ما میگویند که الگوریتمِ طقه بندی ما، چقدر از یک الگوریتم تصادفی، بهتر عمل کرده است.
فرض کنید سیستمی هوشمند برای تشخیص و پیشبینیِ یک نوع بیماری نوشتهاید. این سیستم با توجه به ویژگیهای (ابعاد) مسئله و دادههای مجموعهی آموزشی، یادگیری را انجام میدهد به صورتی که با مشاهدهی ویژگیهای هر بیمار، میتواند نوع بیماری را تشخیص دهد. نوع بیماری در سه کلاس، طبقهبندی شده است: آنفولانزا/کرونا/حساسیت. یعنی الگوریتمِ طبقهبندی بعد از فاز یادگیری، با مشاهدهی ویژگیهای هر بیمار، قادر خواهد بود بیماریِ او را تشخیص دهد و یکی از کلاسهای موجود را برای این بیمار، برچسبزنی کند. حال تصور کنید این الگوریتم در فاز آزمایش به نتیجهای مانندِ ماتریس اغتشاش زیر برسد:
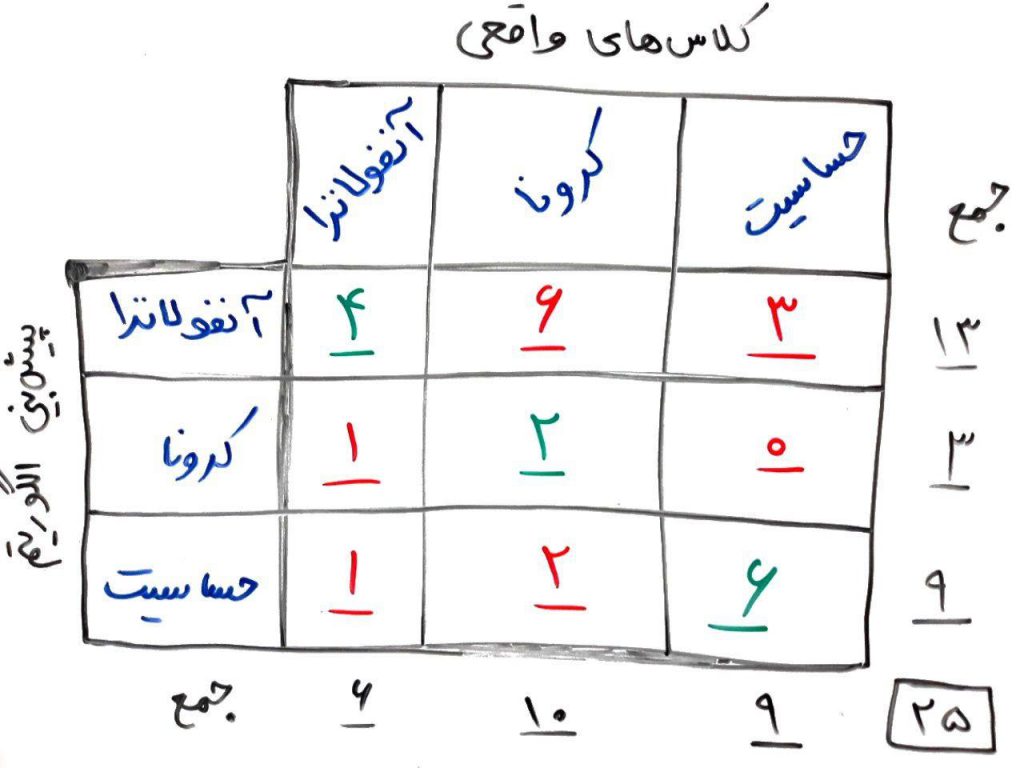
همانطور که مشاهده میکنید تعداد ۲۵ بیمار (که برچسب آنها را میدانستیم) توسط الگوریتمی که از دادههای قبلی یاد گرفته است نیز برچسب زده شدهاند. ستونها برچسبهای واقعی و سطرها برچسبهایی هستند که الگوریتم زده است. (در ماتریس اغتشاش فرقی ندارد که ستون را برچسبهای واقعی بگیریم یا سطر را – فرمول ثابت میمانند). برای مثال از این ۲۵ نفر، تعداد ۴ نفر واقعاً آنفولانزا داشتند و الگوریتم نیز به درستی این ۴ نفر را بیمار آنفولانزا تشخیص داده است. یا برای مثال تعداد ۶ نفر کرونا داشتهاند ولی الگوریتم به اشتباه آنها را بیمار آنفولانزا تشخیص داده است. پس تفسیر جدول بالا دقیقاً مانند همان ماتریس اغتشاش ساده است.
حالا به معیار کاپا میرسیم. فرمول کلی معیار کاپا به صورت زیر است:
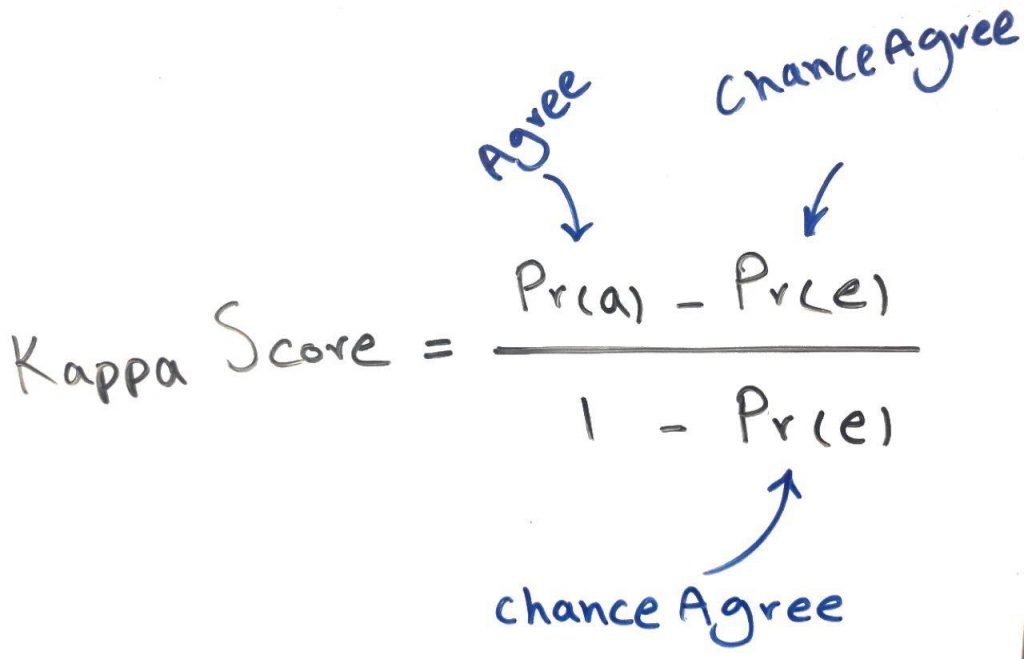
در فرمول بالا دو متغیر داریم. یکی Agree و دیگری ChanceAgree. در اینجا Agree به معنای توافقِ درست است و برای ماتریس اغتشاش مثال ما به صورت زیر محاسبه میشود:
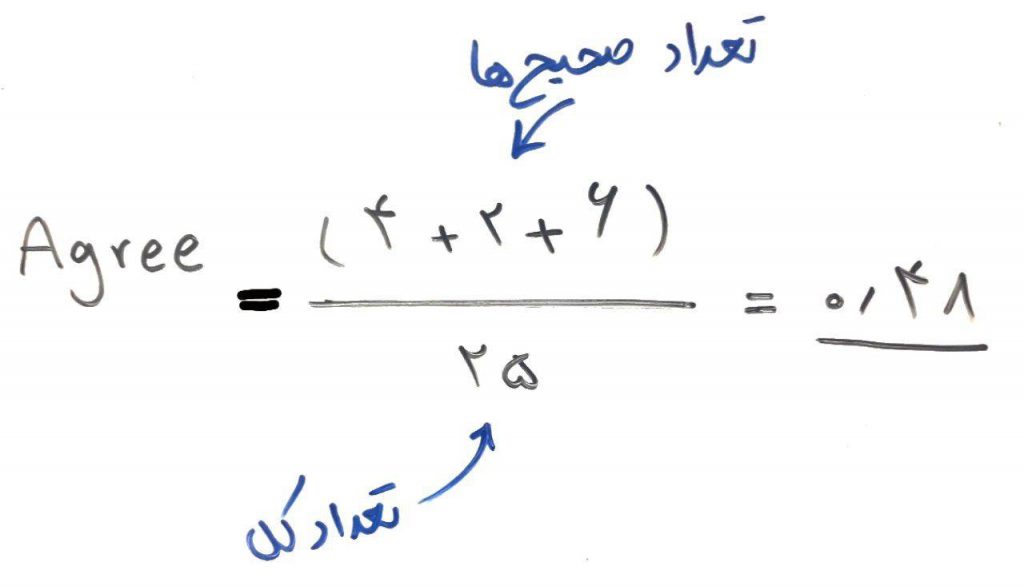
همانطور که مشاهده میکنید اگر درصد توافق ۱ باشد، معیار کاپا هم ۱ میشود. ولی اگر درصد توافق کمتر از ۱ باشد بایستی به متغیر ChangeAgree (یا شانس توافق) نگاه کنیم. این متغیر درصد شانسی بودن توافق را نشان میدهد و برای هر کدام از کلاسها بایستی جداگانه محاسبه شود. برای مثال برای کلاس آنفولانزا به صورت زیر محاسبه میشود:

در واقع محاسبات بالا نشان میدهد که الگوریتمِ مبتنی بر شانس (با توجه به تعداد نمونهها در کلاسِ آنفولانزا و بقیهی کلاسها)، با چه احتمالی میتوانسته کلاس آنفولانزا را درست تشخیص داده باشد.
همینکار را برای کلاسِ کرونا نیز انجام میدهیم:

و برای کلاس حساسیت نیز:

حال جمعِ تمامیِ این شانسهای توافق، متغیر ChanceAgree را تشکیل میدهد:

پس حالا که Agree و ChanceAgree را داریم، به راحتی میتوانیم معیار کاپا را برای ماتریس بالا محاسبه کنیم:
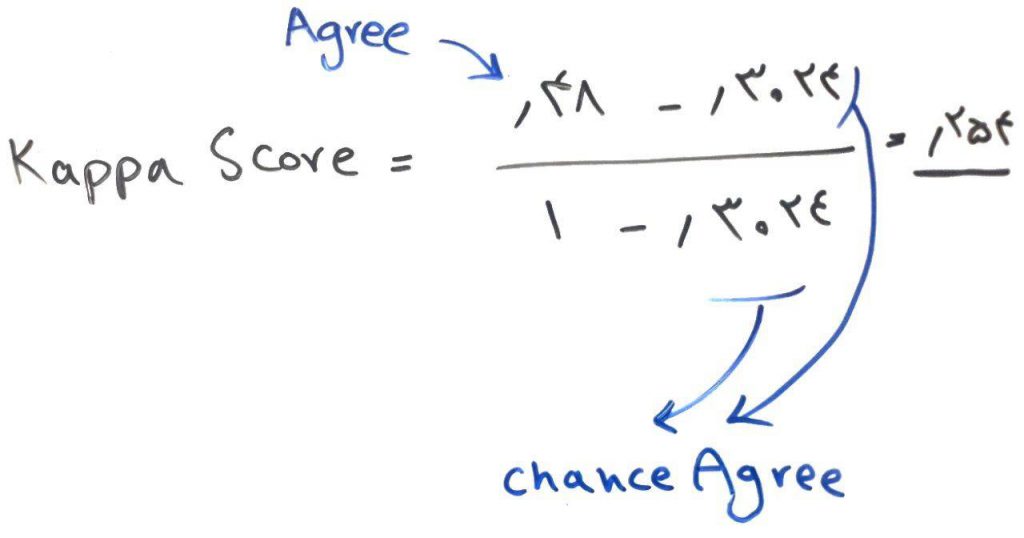
مشاهده میکنید که امتیاز کاپا برای این مسئلهی ما با توجه به ماتریس اغتشاش بالا، برای ۰/۲۵۴ شده است.
تفسیر معیار کاپا، نیز به صورت زیر است:
| کمتر از ۰ | عملکرد خیلی بد |
| بین ۰ تا ۰/۲۰ | عملکرد ضعیف |
| بین ۰/۲۱ تا ۰/۴۰ | عملکرد متوسط رو به پایین (الگوریتم مثال ما) |
| بین ۰/۴۱ تا ۰/۶۰ | عمکرد متوسط |
| بین ۰/۶۱ تا ۰/۸۰ | عملکرد خوب |
| بین ۰/۸۱ تا ۱ | عملکرد عالی |
همانطور که دیدید، معیار کاپا (Kappa) به سادگی میتواند عملکرد الگوریتمهای چند کلاسه را ارزیابی کند. این معیار قادر است که تعداد نمونهها را در یک مجموعهی دادهی نامتوازن نیز در نظر بگیرد و کیفیت الگوریتم را با توجه به تعداد نمونهها بیان کند. پس برای مسائلی با طبقههای مختلف و همچنین مسائلی که دادههای نامتوازن دارند، میتوانید از این معیار استفاده کنید.

- ۱ » الگوریتم K نزدیک ترین همسایه (KNN)
- ۲ » درخت های تصمیم جهت طبقهبندی (Decision Trees)
- ۳ » الگوریتم درخت تصمیم ID3 و ساختار Entropy و Gain
- ۴ » آشنایی با مفهوم Overfitting و Underfitting در طبقهبندی
- ۵ » آشنایی با مفهوم Bias و Variance در طبقهبندی
- ۶ » الگوریتم طبقهبندی درخت تصمیم C4.5
- ۷ » الگوریتم طبقه بند درخت تصمیم CART
- ۸ » طبقه بند ترکیبی (Ensemble Classifier) و مبحث Bagging و Boosting
- ۹ » الگوریتم جنگل تصادفی (Random Forest)
- ۱۰ » رگرسیون لجستیک (Logistic Regression)
- ۱۱ » مسائل طبقهبندی دودویی (binary)، چند کلاسه (Multi Class)، چند برچسبه (Multi Label) و تفاوت آنها
- ۱۲ » روش «یک در مقابل همه (One vs. All)» برای طبقهبندی دادههای چند کلاسه
- ۱۳ » روش «یک در مقابل یک (One vs. One)» در طبقهبندی
- ۱۴ » مدلهای احتمالی در مقابل مدلهای قطعی در طبقهبندی دادهها
- ۱۵ » ماتریس اغتشاش (Confusion Matrix) و معیار دقت (Accuracy)
- ۱۶ » معیار صحت (Precision)، پوشش (Recall) و معیار F
- ۱۷ » معیار کاپا (Kappa) برای ارزیابی طبقهبندیهای چندکلاسه
بسیار عالی بود.
دست شما درد نکنه
ممنون از اینکه با مثال توضیح دادید.
سلام
من می خواهم ارزیابی صحت در مورد ارزیابی اراضی انجام دهم با شاخص کاپا
لطفا چند تا مثال ارزیابی اراضی مثل مورد بالا برام اگه مقدوره ارسال بفرمایید
متشکر
سپاس
سلام، من رو موضوع بیوفیلیک کار میکنم و ۶ شاخصه دارم، که هر کدوم زیر شاخصه های مرتبط با خودش رو داره و در کل ۵۴ زیرشاخصه دارم. می خوام از ۴ نفر ، میزان حضور این مولفه ها رو طبق طیف لیکرت بپرسم. و در نهایت میزان توافق ۴ نفر رو بسنجم. میتونم با کاپا اینکار رو انجام بدم یا معیار کاپا فقط برای پرسیدن از ۲ نفر امکانش هست؟