

بسیاری از مسائل حوزهی طبقهبندی (Classification) فقط دو کلاس (دو نوع برچسب) دارند. به این مسائل، طبقهبندی دودویی میگویند. برای مثال، مانند درس گذشته، فرض کنید میخواهیم سیستمی بسازیم که بتواند تفاوت ایمیلهای اسپم و عادی را بر اساس یک سری ویژگی (بُعد)، تشخیص دهد. این کار توسط الگوریتمهای طبقهبندی به سادگی قابل انجام است. اما هنگامی که تعداد این طبقهها (انواع برچسبها) بالا و بالاتر میرود، کار برای الگوریتم سخت شده نیاز به الگوریتمهای پیچیدهتری هست.
اگر درس «ویژگی و بُعد» را خوانده باشید، میدانید که ما میتوانیم دادهها را به فضای چند بُعدی جبر خطی نگاشت کنیم. حال فرض کنید میخواهیم ایمیلهای اسپم و عادی را با استفاده از فقط دو ویژگی از هم تفکیک کنیم. یکی از این دو ویژگی، تعداد کاراکترهای موجود در ایمیل است و دیگری تعداد لینکهای موجود در ایمیل. تصویر زیر، نگاشت شدهی دادهای است بر روی محور مختصات:
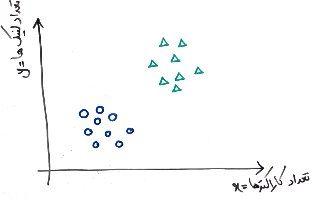
در این مسئلهی فرضی، ما دو ویژگی داریم (x – تعداد کاراکترهای ایمیل و y – تعداد لینکهای موجود در ایمیل) و نمونههای ما در این فضای دو بُعدی قرار دارند. نمونههای سبز رنگ مثلثی، ایمیلهای عادی هستند و نمونههای آبی رنگ دایرهای، ایمیلهای اسپم. همانطور که از دروس قبلی دوره طبقهبندی به یاد دارید، میتوانیم با استفاده از الگوریتمی مانند SVM، خطی را رسم کنیم که میتواند تمایز بین ایمیلهای اسپم و عادی را مشخص نماید.
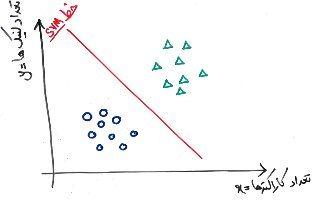
حال فرض کنید، تعداد طبقهها (انواع برچسبها) بیشتر شود. برای مثال میخواهیم هر ایمیل را به طبقههایی مانند عادی/اسپم/تبلیغات طبقهبندی کنیم. در این مسئله تعداد طبقهها برابر ۳ هست و تصویر زیر، نگاشت شدهی این دادهها بر روی محور مختصات مثال قبلی است:

فرض کنید نمونههای قرمز که با علامت ضربدر مشخص شدهاند، ایمیلهایی هستند که مربوط به طبقهی «تبلیغات» است. نمونههای سبز مثلثی و نمونههای آبی دایرهای هم مانند قبل به ترتیب، ایمیلهای عادی و اسپم هستند. همانطور که مشاهده میکنید، دیگر نمیتوان با یک خط ساده، تمایزِ طبقهها را کشف کرد. برای اینکار بایستی از تکنیکهای دیگری مانند تکنیک kernel، یا الگوریتمهای طبقهبندی غیر خطی استفاده کرد. اما یک راه حل دیگر هم موجود است که در بسیاری از شرایط، دقت خوب و حتی بهتر از برخی از الگوریتمهای پیشرفتهی طبقهبندی تولید میکند. این راه حل «یک در مقابل همه یا One vs. All» نام دارد. البته به این راه حل «یک در مقابل بقیه یا One vs. Rest» نیز میگویند.
در این روش بایستی به تعداد طبقهها (انواع برچسبها)، مُدلِ طبقهبندی ساخت، و اعضای هر یک از کلاسها را در مقابل بقیه قرار داد. با این کار میتوان یک مسئلهی طبقهبندی چند کلاسه (Multi Class) را به چندین مسئلهی طبقهبندی دودویی (Binary) تبدیل کرد. کاری مانند شکل زیر:
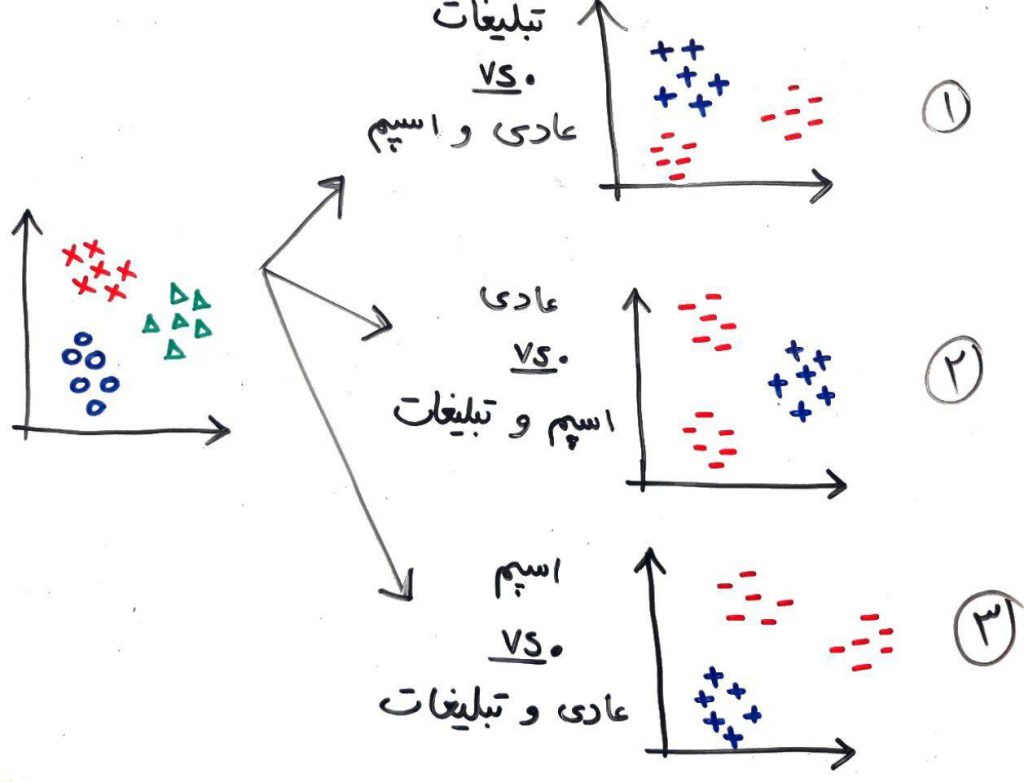
در اینجا سه کلاس برای ایمیلها داریم (عادی/اسپم/شبکههای اجتماعی). پس نیاز به سه مجموعهی داده به صورتی داریم که در هر یک، نمونههای یکی از کلاسها در مقابل نمونههای بقیهی کلاسها قرار بگیرد (در مثال بالا، کلاس مورد نظر با علامت مثبت (+) و کلاسهای بقیه که در مقابل آن قرار میگیرند با علامت منفی (-) نمایش داده شده اند). حال برای هر کدام از این مجموعه دادهها بایستی یک الگوریتم طبقهبندی دودویی طراحی کنیم:
۱. طبقه بند دودویی «کلاس ایمیل تبلیغاتی در مقابل کلاسهای عادی و اسپم»
۲. طبقه بند دودویی «کلاس ایمیل عادی در مقابل کلاسهای اسپم و تبلیغاتی»
۳. طبقه بند دودویی «کلاس ایمیل اسپم در مقابل کلاسهای عادی و تبلیغاتی»
این سه طبقه بندِ دودویی بر روی دادهها، یادگیری را انجام میدهند و بعد از یادگیری، یک نمونهی جدید برای پیشبینیِ کلاس، به تمامیِ این ۳ الگوریتم که یادگرفته شدهاند، داده میشود و هر کدام احتمال عضویت این نمونه را به یکی از دو کلاس خود، برمیگردانند. برای مثال فرض کنید ما سه الگوریتمِ رگرسیون لجستیک (Logistic Regression) را بر روی دادههای بالا با استفاده از مدل «یک در مقابل همه (One vs. All)» اعمال کردهایم و این سه الگوریتم یادگیری را انجام دادهاند. حال یک نمونهی جدید به این سه الگوریتم داده میشود و نتایج به صورت زیر است:
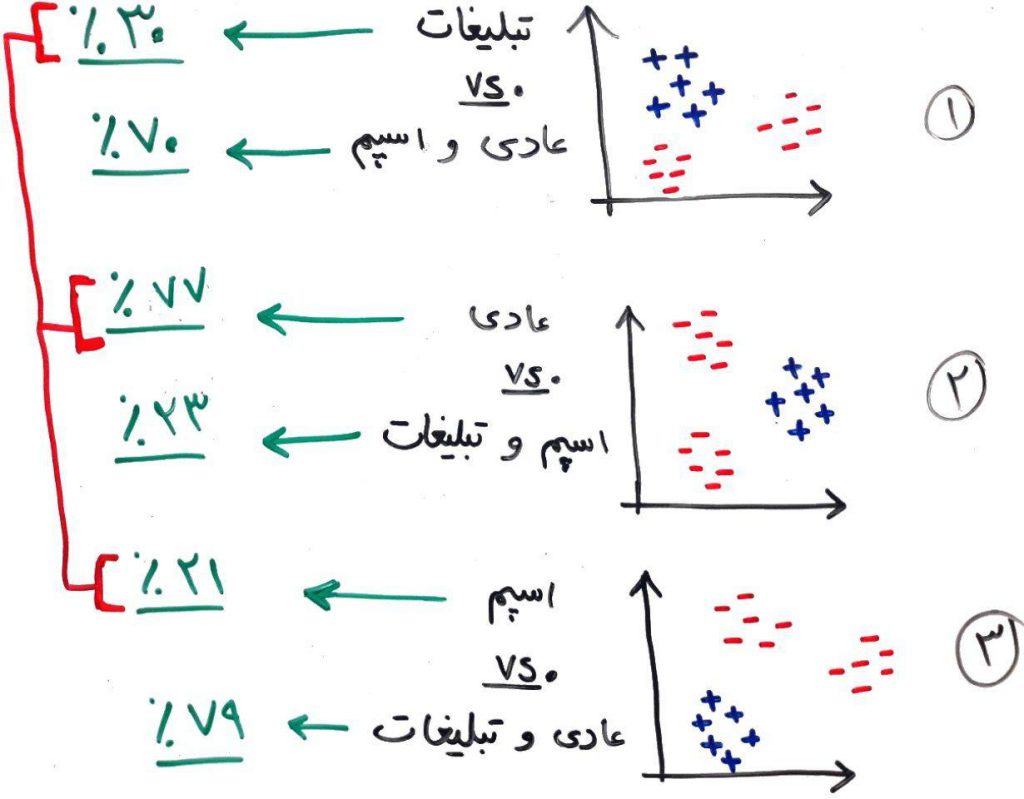
همانطور که میبینید احتمالِ عادی بودن، بیشتر از بقیهی احتمالها شد، پس این نمونه، یک نمونه ایمیل عادی است. توجه کنید که برای مقایسه بایستی فقط طبقههای مثبت شده را با هم مقایسه کرد تا به یک نتیجهی نهایی رسید.

- ۱ » الگوریتم K نزدیک ترین همسایه (KNN)
- ۲ » درخت های تصمیم جهت طبقهبندی (Decision Trees)
- ۳ » الگوریتم درخت تصمیم ID3 و ساختار Entropy و Gain
- ۴ » آشنایی با مفهوم Overfitting و Underfitting در طبقهبندی
- ۵ » آشنایی با مفهوم Bias و Variance در طبقهبندی
- ۶ » الگوریتم طبقهبندی درخت تصمیم C4.5
- ۷ » الگوریتم طبقه بند درخت تصمیم CART
- ۸ » طبقه بند ترکیبی (Ensemble Classifier) و مبحث Bagging و Boosting
- ۹ » الگوریتم جنگل تصادفی (Random Forest)
- ۱۰ » رگرسیون لجستیک (Logistic Regression)
- ۱۱ » مسائل طبقهبندی دودویی (binary)، چند کلاسه (Multi Class)، چند برچسبه (Multi Label) و تفاوت آنها
- ۱۲ » روش «یک در مقابل همه (One vs. All)» برای طبقهبندی دادههای چند کلاسه
- ۱۳ » روش «یک در مقابل یک (One vs. One)» در طبقهبندی
- ۱۴ » مدلهای احتمالی در مقابل مدلهای قطعی در طبقهبندی دادهها
- ۱۵ » ماتریس اغتشاش (Confusion Matrix) و معیار دقت (Accuracy)
- ۱۶ » معیار صحت (Precision)، پوشش (Recall) و معیار F
- ۱۷ » معیار کاپا (Kappa) برای ارزیابی طبقهبندیهای چندکلاسه
مختصر و مفید و کاربردی بود. ممنون
متشکرم مهندس
البته این مثاله و در مثال مناقشه نیست
اما
ایمیل با کارکتر بیشتر و لینک بیشتر >>> می شود اسپم؟
فکر کنم برعکس مشخص کردین یا من برعکس فکر می کنم