

این دو مفهوم از مفاهیمِ اساسی است که در بحثِ طبقهبندیِ دادهها مورد بحث قرار میگیرند. هدف از درسِ جاری این است که با مفهوم Overfitting و Underfitting آشنا شده تا بتوانیم الگوریتمهایی ارائه کنیم تا از این دو پدیده در امان باشند.
اجازه بدهید با یک مثال شروع کنیم. فرض کنید شما برای یک امتحانِ آخرِ ترم در حال درس خواندن هستید. استاد هم به شما ۱۰۰ عدد نمونه سوال داده است تا با استفاده از آنها بتوانید خود را برای امتحان آماده کنید. اگر شما طوری مطالعه کنید که فقط این ۱۰۰ نمونه سوال را کامل بلد باشید و هر سوالِ دیگری که کمی از این ۱۰۰ سوال فاصله داشته باشد، اشتباه جواب دهید، یعنی ذهنِ شما بر روی سوالاتِ آموزشی که استاد برای یادگیری داده است Overfit یا بیشبرازش شده است. حال اگر تمامی سوالات را به صورت مفهومی بلد باشید ولی هیچ کدام از سوالات را به صورتِ دقیق بلد نباشید، حتی اگر دقیقاً همان سوالها هم در جلسه امتحان به شما داده شود، باز هم نمیتوانید به درستی و با دقت پاسخ آن ها را بدهید، البته شاید بتوانید یک پاسخ نصفه و نیمه از سوالات بنویسید. اینجا ذهن شما Underfit شده است. این در حالی است که سوالات دیگری که نزدیک به این سوالات هستند را هم شاید بتوانید نصفه و نیمه پاسخ دهید (ولی دقیق نمیتوانید).
در دنیای الگوریتمها Overfit شدن به معنای این است که الگوریتم فقط دادههایی که در مجموعه آموزشی (train set) یاد گرفته است را میتواند به درستی پیشبینی کند ولی اگر دادهای کمی از مجموعهی آموزشی فاصله داشته باشد، الگوریتمی که Overfit شده باشد، نمیتواند به درستی پاسخی برای این دادههای جدید پیدا کند و آنها را با اشتباهِ زیادی طبقهبندی می کند.
Underfit شدن نیز زمانی رخ می دهد که الگوریتم یک مدلِ خیلی کلی از مجموعه آموزشی به دست میآورد. یعنی حتی اگر خودِ دادههای مجموعهی آموزشی را نیز به این الگوریتم بدهیم، این الگوریتم خطایی قابل توجه خواهد داشت.
فرض کنید نقطهها در شکل زیر نمونه سوالاتی هستند که استاد برای آمادگی در امتحان همراه با پاسخِ آنها به ما داده است. سوال در محور افقی داده میشود و پاسخ در محور عمودی است. به این معنی که به شما X داده میشود و شما باید از روی عددِ این X، عددِ Y (عدد روی محور عمودی) را تشخیص دهید. مثلاً اگر مختصاتِ عدد نخست سمت چپدر تصویر زیر [۶, ۱] باشد، به این معنی است که اگر عدد ۱ را به این الگوریتم بدهیم، الگوریتم عدد ۶ را برگرداند. پس با این حساب اگر به الگوریتم عدد ۱.۱ را دادیم، این الگوریتم (که یادگیری را قبلاً از روی دادهها انجام داده است) احتمالاً باید عددی نزدیک به ۶ را برگرداند. این ها در واقع همان مجموعه آموزشی ما هستند:
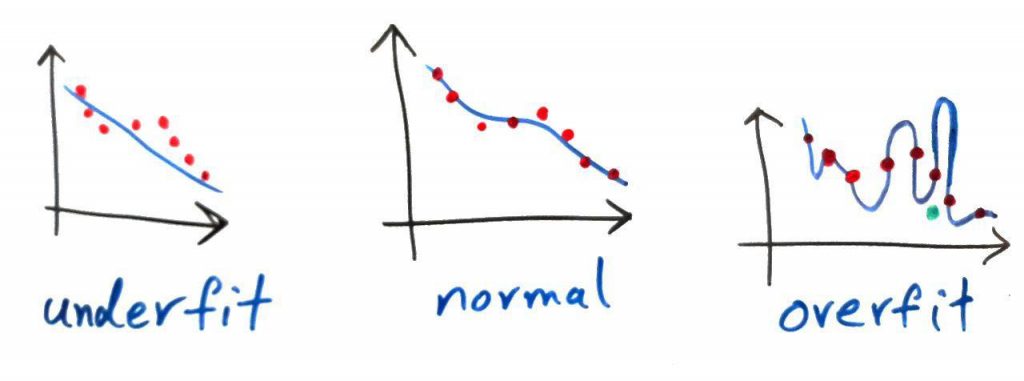
خط آبیِ موجود، در واقع یادگیریِ مدل طبقهبندی است (به صورت دقیقتر در اینجا رگرسیون داریم). همانطور که میبینید در سمت چپ، خطی که الگوریتمِ طبقهبندیْ یادگرفته است از تمامی دادهها به مقدار قابل توجهی فاصله دارد. یعنی در این شکل (سمت چپ) underfitting رخ داده است. این در حالی است که در شکل سمت راست، overfitting رخ داده. توجه کنید که در شکلِ سمت راست، اگر یک نقطه جدید (مثلا یک سوال جدید در امتحان) داده شود (نقطه سبز رنگ داده شده) الگوریتم خطای بسیار زیادی دارد. یعنی مقدار Yی که برمیگرداند بسیار با مقدار واقعی فاصله دارد – چون الگوریتم خیلی نتوانسته است که یادگیری را عمومی سازی کند و نسبت به مقادیر جدید خطای بالایی نشان میدهد. شکل وسط نیز یک خط معقول و درست برای یک طبقه بند را نشان می دهد که overfit یا underfit نشده است.
این دو خطای معروف در حوزه طبقهبندی هستند که الگوریتم های مختلف طبقهبندی باید از آن ها اجتناب کنند.

- ۱ » الگوریتم K نزدیک ترین همسایه (KNN)
- ۲ » درخت های تصمیم جهت طبقهبندی (Decision Trees)
- ۳ » الگوریتم درخت تصمیم ID3 و ساختار Entropy و Gain
- ۴ » آشنایی با مفهوم Overfitting و Underfitting در طبقهبندی
- ۵ » آشنایی با مفهوم Bias و Variance در طبقهبندی
- ۶ » الگوریتم طبقهبندی درخت تصمیم C4.5
- ۷ » الگوریتم طبقه بند درخت تصمیم CART
- ۸ » طبقه بند ترکیبی (Ensemble Classifier) و مبحث Bagging و Boosting
- ۹ » الگوریتم جنگل تصادفی (Random Forest)
- ۱۰ » رگرسیون لجستیک (Logistic Regression)
- ۱۱ » مسائل طبقهبندی دودویی (binary)، چند کلاسه (Multi Class)، چند برچسبه (Multi Label) و تفاوت آنها
- ۱۲ » روش «یک در مقابل همه (One vs. All)» برای طبقهبندی دادههای چند کلاسه
- ۱۳ » روش «یک در مقابل یک (One vs. One)» در طبقهبندی
- ۱۴ » مدلهای احتمالی در مقابل مدلهای قطعی در طبقهبندی دادهها
- ۱۵ » ماتریس اغتشاش (Confusion Matrix) و معیار دقت (Accuracy)
- ۱۶ » معیار صحت (Precision)، پوشش (Recall) و معیار F
- ۱۷ » معیار کاپا (Kappa) برای ارزیابی طبقهبندیهای چندکلاسه
با سلام
با تشکر از مطالب ساده ولی پرمحتوای حضرتعالی
لطفا اگر ممکن هست درباره “درخت تصمیم فازی” هم مطلب بزارید.
با تشکر
سلام چند وقتیه که با این سایت آشنا شدم واقعا آموزشاتون عالیه خود استاد وقتی درس می ده اصلا نمی فهمم که چی میگه
سلام ممنونم از اطلاعات خوبتون
یک سوال چرا وقتی که از تابع log استفاده می کنیم وزنه کمتر به سمت overfit پیش می روند
سلام
چرا زمانی که تابع لگاریتمی استفاده می کنیم وزن ها کمتر به سمتoverfit پیش می روند
سلام
پاسخ بستگی به این دارد که در چه الگوریتمی این کار انجام میشود
لزوما تابعی مانند log نمیتواند تضمین overfit نشدن را داشته باشد
سلام . با عرض خسته نباشید .لطفا راجع به فرار از overfitting توضیح بدید . ممنون
سلام . محتوای این پیج بسیار عالی بود و به من کمک کرد . ممنونم
سلام. من میخواستم از شما تشکر کنم. واقعا آموزش ها تون حرف نداره. امیدوارم همینطور موفق ادامه بدید.
موفق و پیروز باشی
خدا پدرومادرتو حفظ کنه چه موجود مفید و بزرگواری تحویل جامعه دادن
کاملا کاربردی و ساده
سلام در حال ترجمه ی متن هستم. خاستم ببینم کلمات underfit و overfit ترجمه خاصی دارن یا همینجور بیان میشن؟ ممنون.
سلام
شاید بتوان کلمات بیشبرازش و کمبرازش را برایشان به کار برد
تشکر واقعاا
با سلام و عرض ادب…
ببخشید استاد عزیز چرا وقتی که در یک مجموعه داده تعداد الگوها خیلی کمتر از تعداد ویژگی ها باشد تمایل به Overfitting زیاد میشود؟ ممنون میشم جواب بدهید
ممنون .خدا خیرتون بده .خیلی ساده و عالی گفتید
ممنون از مثالی که گفتین خیلی خوب بود.
چقدر عالی توضیح دادید ممنونمم
سلام اقای کاویانی عبادات ماه رمضان ۱۴۰۰ مقبول درگاه حق مطالب overfit ,underfit بسیار عالی وخوب بیان کردید سپاسگزارم خداوند سلامت وبرکت به شماعنایت کنه ممنون
واقعا مختصر و مفید دست شما درد نکنه
چقدر عالی توضیح داده بودید. بسیار سپاسگذارم
اگر دقت یا صحت داده های Test از داده های Train بهتر باشه، میشه کم برازش؟
نه لزوماً
احتمال رخداد چنین اتفاقی خیلی کم هست و بیشتر به خاطر شانس رخ میده