

فرض کنید صاحبِ یک نانوایی هستید. برای تهیهی نان، نیاز به آرد دارید. آرد نیز خود از گندم به دست میآید. یعنی گندم بایستی از شکلِ اولیهی خود خارج شده و به آرد تبدیل شود (با فرآیندهای مختلفی که بر روی گندم انجام میشود) تا مادهی اولیهی تولیدِ نان، آماده شود. در فرآیندهای دادهکاوی مانند طبقهبندی و خوشهبندی، نیاز داریم تا دادهها برای الگوریتمْ آماده شوند. زیرا معمولاً نمیتوان دادهها را به صورت خامْ به الگوریتمهای دادهکاوی و یادگیری ماشین تزریق کرد.
از آنجایی که دادهها معمولاً از منابعی تهیه میشوند که این منابع بدونِ توجه به فرآیندهای دادهکاوی، دادهها را تولید یا نگهداری کردهاند، نیاز است تا دادهها، با توجه به شرایط و مسئله، به دادههای مناسب جهتِ تزریق به الگوریتمهای دادهکاوی تبدیل شوند.
برای آمادهسازیِ دادهها، نیاز است تا آنها را از شکل و حالتِ اولیه، خارج کرده و به شکلی که برای الگوریتم مناسب باشد تبدیل کنیم. همچنین دادههای موجود معمولاً دارای زواید مختلفی هستند که ممکن است الگوریتم را دچار خطا کنند. همان مثالِ نانوایی را به یاد بیاورید. فرض کنید در میانِ گندمها، خورده سنگ هم وجود داشته باشد! طبیعتاً وجودِ خورده سنگ کیفیت آرد و به تبعِ آن، کیفیت نان را کاهش میدهد، پس نیاز است تا خورده سنگها از میانِ گندمها پاک شوند. در دادهکاوی هم نیاز داریم تا دادههای اضافی که به مسئله و الگوریتم کمکی نمیکنند را حذف کنیم.
اگر درسِ فرآیند کریسپ (CRISP) در داده کاوی را خوانده باشید، احتمالا متوجه شدهاید که در فرآیند کریسپ، پیش از مدلسازی توسط الگوریتمهای یادگیری ماشین، نیاز به آمادهسازی دادههاست که یکی از مراحل آن همین پیشپردازش دادهها و استفاده از تکنیکهایی جهت آمادهسازی (prepare) آنها قبل از تزریق به الگوریتمهای داده کاوی و یادگیری ماشین در مرحلهی بعدی (یعنی مدلسازی) بود.
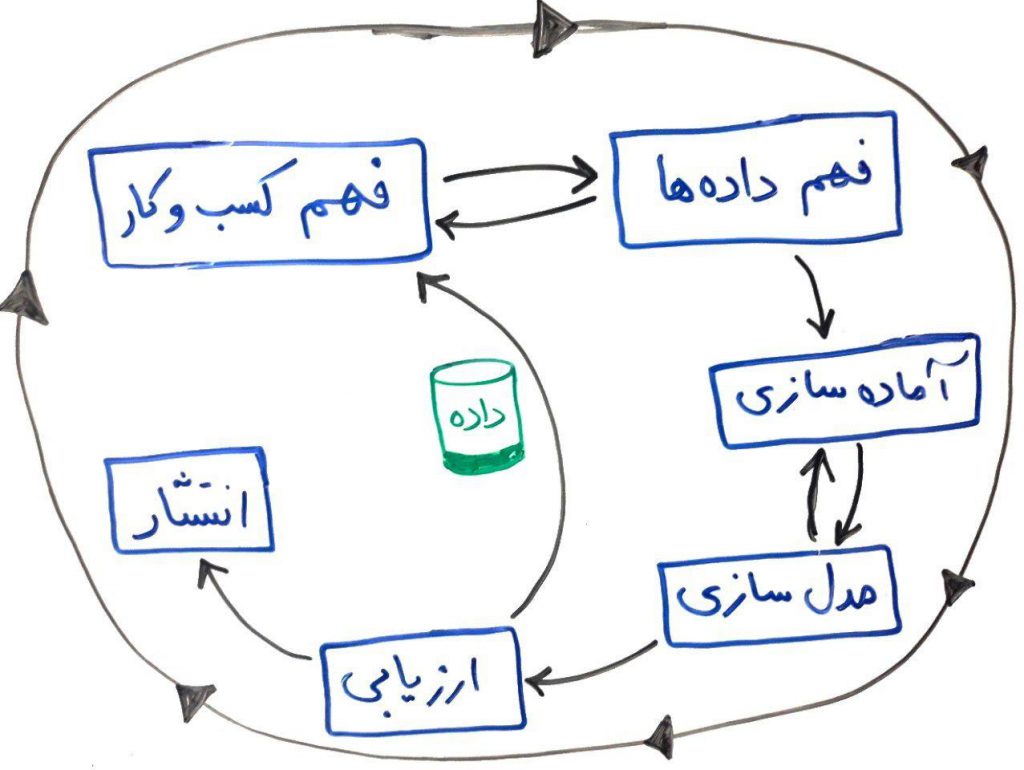
برای عملیاتِ پیش پردازش، روشها و راهکارهای مختلفی طراحی شده است که در ادامهی این دوره به آنها خواهیم پرداخت. همانطور که از نامِ این روشها پیداست، عملیات پیشپردازش یا همان preprocessing معمولاً قبل از عملیات اصلیِ الگوریتمهای دادهکاوی انجام میگیرند و باعث تسهیل و کمک به الگوریتمها میشوند.

- ۱ » پیش پردازش دادهها (Data Preprocessing) چیست؟
- ۲ » بررسی یکپارچگی دادهها (Data Integrity)
- ۳ » نرمال کردن دادهها (Data Normalization) و انواع آن
- ۴ » تبدیل دادهها (Data Transformation) به فُرمت قالب فهم برای الگوریتم دادهکاوی
- ۵ » دادههای گمشده (Missing Values) و راهکارهای مقابله با آنها
- ۶ » تشخیص دادههای پرت و دارای نویز (Noise) و راهکار مقابله با آنها
- ۷ » انتخاب ویژگی (Feature Section) و کاهش ابعاد
- ۸ » انتخاب نمونه (Instance Selection) در پیش پردازش دادهها
سلام و خسته نباشین
خیلی عالی توضیح دادین .
خیلی عالی توضیح دادین
سلام ممنون از توضیح ساده و روانتون، عالی بود
دمتون گرم عالی بود . یاد آقای قرائتی افتادم اونم خیلی روان میگه
خیلی عالی نمره تون بیسته