

همانطور که تا اینجا در دوره طبقهبندی دادهها مشاهده کردید، ما به دنبال الگوریتمی هستیم با استفاده از دادههای آموزشی، یادگیری را انجام دهد، و بتواند دادههای جدید را حتیالمکان به درستی پیشبینی یا همان طبقهبندی نماید. مشکل هنگامی پدیدار میشود که الگوریتم معمولاً نمیتواند دقتِ ۱۰۰درصدی داشته باشد. یعنی معمولاً کمی خطا در پیشبینیِ خود دارد.
فرض کنید مجموعهی دادهای مانند زیر را در اختیار داریم و با استفاده از یک الگوریتمِ طبقهبندی (مانند جنگل تصادفی) یک مُدل (model) بر روی این مجموعهی آموزشی ساختهایم:
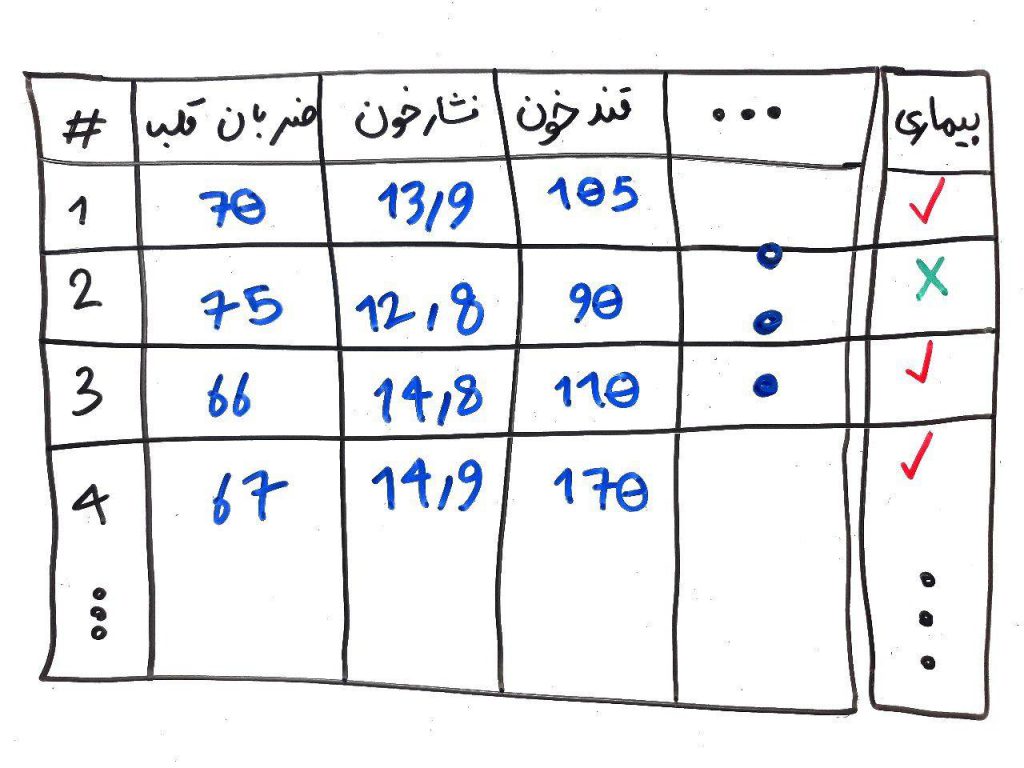
از الگوریتم میخواهیم تا با توجه به این مجموعهی داده و دانشی که پزشک در اختیار او قرار داده است، یاد بگیرد که یک شخص، با توجه به ویژگیهایش (ابعاد مسئله) بیمار هست یا خیر. اگر درس مجموعهی آموزشی/مجموعهی آزمون را خوانده باشید میدانید که نبایستی تمامیِ داده را در اختیار الگوریتم گذاشت. معمولاً قسمتی از مجموعهی داده را به الگوریتم میدهیم تا الگوریتم یادگیری را انجام دهد و پس از آن، قسمت دیگر را برای آزمودنِ الگوریتم، به کار میبریم تا بتوانیم دقت الگوریتم را محاسبه کنیم. مانند دانشآموزی که بعد از خواندن دروس و نمونه سوالات، در جلسه امتحان بایستی به سوالاتی که جواب آنها در دست معلم است، پاسخ دهد و معلم، پاسخهای داده شده توسط دانشآموز را با پاسخهای درستِ موجود مقایسه میکند تا نمرهی دانشجو محاسبه شود.
در نگاه اول، ممکن است فکر کنید که دو حالت بیشتر وجود ندارد، یا الگوریتم درست تشخیص داده است یا الگوریتم اشتباه تشخیص داده است. برای مثال از بین ۱۰۰ نفر که در مجموعهی آزمون هستند، الگوریتم ممکن است ۱۴ نفر را اشتباه تشخیص دهد و ۸۶ نفر را درست تشخیص دهد. ولی مسئله به این سادگی نیست. برای فهم این پیچیدگی، به ماتریس زیر نگاه کنید:
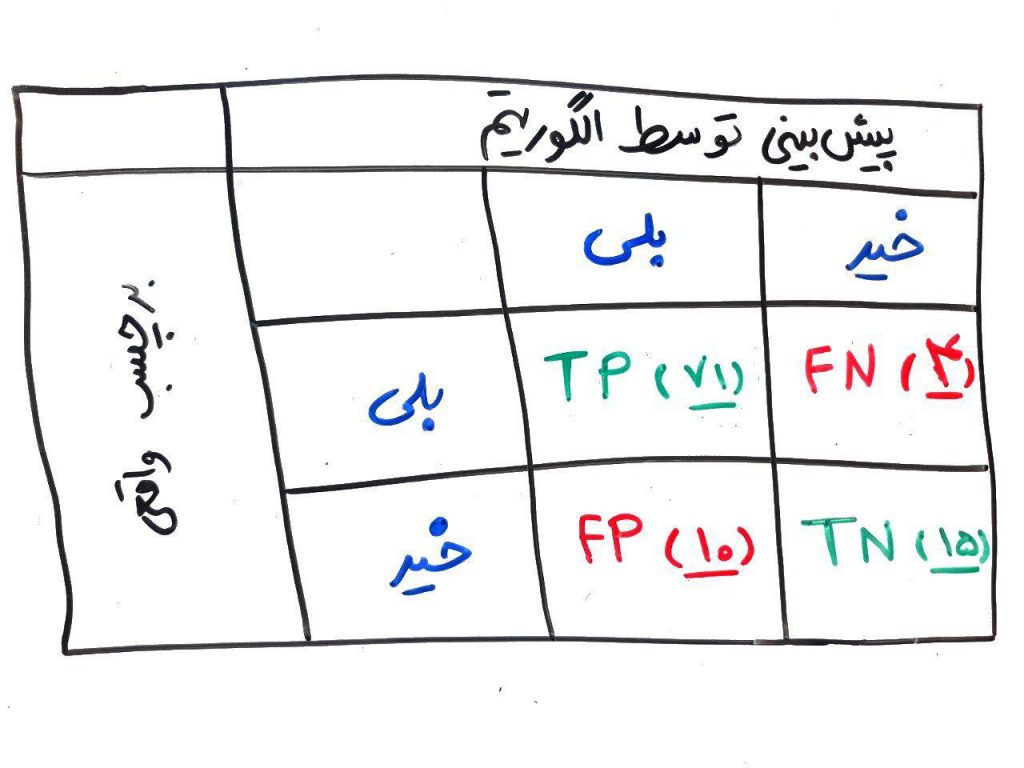
برای درک شکل بالا فرض کنید الگوریتم طبقهبندی، بعد از یادگیری و ساخت مُدل، مورد آزمون قرار گرفته است. در این آزمون ما ۱۰۰ شخص را به الگوریتم میدهیم تا الگوریتم این اشخاص را بر اساس ویژگیهایشان طبقهبندی کند (که بیمار هستند یا خیر). توجه کنید که ما برچسب واقعی را برای هر بیمار میدانیم و میخواهیم کیفیت الگوریتم را بررسی کنیم. در شکل بالا سطرها، برچسبهای واقعیِ ما هستند و ستونها، پیشبینیهای الگوریتم را تشکیل میدهند. بر این اساس چهار حالت زیر را داریم:
۱. حالتی که برخی اشخاص بیمار باشند و الگوریتم هم به درستی بیماری را تشخیص داده باشد که به آن True Positive یا همان TP میگویند
۲. حالتی که برخی اشخاص بیمار باشند ولی الگوریتم به اشتباه بگویند که این افراد بیمار نیستند. که به آن False Negative یا همان FN میگویند
۳. حالتی که برخی اشخاص بیمار نباشند ولی الگوریتم به اشتباه بگوید که این افراد بیمار هستند. در این حالت False Positive یا همان FP رخ میدهد
۴. و در نهایت حالتی که افراد بیمار نباشند و الگوریتم نیز بگوید که این افراد بیمار نیستند. به این حالت هم True Negative یا همان TN میگویند
همانطور که مشاهده میکنید فقط در حالتهای True Negative و True Positive صحت برقرار است و در دو حالت دیگر خطا رخ داده است. توجه کنید که در هر کدام از این خانهها، تعداد نمونههایی که در آن حالت رخ داده است قرار میگیرد. مثلاً در مثال بالا، تعداد ۷۱ نفر بیمار بودهاند که الگوریتم آنها را درست بیمار تشخیص داده است (TP=71) و یا تعداد ۴ نفر بیمار بودهاند که الگوریتم به اشتباه آنها را سالم تشخیص داده (FN=4). همچنین تعداد ۱۰ نفر بیمار نبودهاند که الگوریتم به اشتباه آنها را بیمار تشخیص داده است (FP=10) و در نهایت تعداد ۱۵ نفر بیمار نبودهاند که الگوریتم هم به درستی آنها را سالم تشخیص داده است (TN=15)
این جدول که به آن ماتریس اغتشاش یا همان Confusion Matrix میگویند، مبنای بسیاری از معیارهای اندازهگیری کیفیت یک الگوریتم طبقهبندی است. یکی از این معیارها، معیار دقت (Accuracy) است که به صورت زیر محاسبه میشود:

در این معیار، صورت کسر، مجموع تعداد عناصری است که درست تشخیص داده شدهاند و مخرج کسر هم جمع تمامی رخدادها در تمامی حالات است. همانطور که ملاحضه میکنید، اگر ماتریس اغتشاش به صورت شکل بالاتر باشد، برای ۱۰۰ شخص بیمار، اعداد در داخل پرانتز هستند و در نهایت با محاسبهی معیار دقت، Accuracy برابر با ۰.۸۶ میشود.
در مثال بالا، ما فقط دو کلاس داشتیم (بیمار بودن/سالم بودن). اگر تعداد کلاسها (برچسبها) بیشتر از دو بود (در اصطلاح چند کلاسه – Multi Class) بود، بایستی برای هر کدام از کلاسها (برچسبها) یک ماتریس اغتشاش طراحی کرد و معیار دقت (Accuracy) را برای هر کدام از این کلاسها محاسبه کنیم، سپس میانگین تمامیِ این دقتها، دقت کل را تشکیل میدهد.
معیار دقت (Accuracy) یک معیار ساده و سرراست برای محاسبهی کیفیت یک الگوریتم است. این معیار ضعفهایی نیز دارد که در دروس آینده و با معرفی معیارهای دیگر، این ضعفها پوشش داده خواهند شد.

- ۱ » الگوریتم K نزدیک ترین همسایه (KNN)
- ۲ » درخت های تصمیم جهت طبقهبندی (Decision Trees)
- ۳ » الگوریتم درخت تصمیم ID3 و ساختار Entropy و Gain
- ۴ » آشنایی با مفهوم Overfitting و Underfitting در طبقهبندی
- ۵ » آشنایی با مفهوم Bias و Variance در طبقهبندی
- ۶ » الگوریتم طبقهبندی درخت تصمیم C4.5
- ۷ » الگوریتم طبقه بند درخت تصمیم CART
- ۸ » طبقه بند ترکیبی (Ensemble Classifier) و مبحث Bagging و Boosting
- ۹ » الگوریتم جنگل تصادفی (Random Forest)
- ۱۰ » رگرسیون لجستیک (Logistic Regression)
- ۱۱ » مسائل طبقهبندی دودویی (binary)، چند کلاسه (Multi Class)، چند برچسبه (Multi Label) و تفاوت آنها
- ۱۲ » روش «یک در مقابل همه (One vs. All)» برای طبقهبندی دادههای چند کلاسه
- ۱۳ » روش «یک در مقابل یک (One vs. One)» در طبقهبندی
- ۱۴ » مدلهای احتمالی در مقابل مدلهای قطعی در طبقهبندی دادهها
- ۱۵ » ماتریس اغتشاش (Confusion Matrix) و معیار دقت (Accuracy)
- ۱۶ » معیار صحت (Precision)، پوشش (Recall) و معیار F
- ۱۷ » معیار کاپا (Kappa) برای ارزیابی طبقهبندیهای چندکلاسه
عالی و روان توضیح دادید ..ممنونم
سلام عرض ادب.آقای مهندس بعد از انجام کار یک الگوریتم از معیار دقت استفاده میکنیم تا دقت اون الگوریتم محاسبه بشه؟؟
یعنی حتما الگوریتم باید مشخص شده باشه و محاسبات لازم رو که انجام داد روی خروجی نتیجه الگوریتم میایم از این فرمول استفاده می کنیم؟؟؟؟
سلام بله دقیقا همین هست که میگید
سلام
مرسی از توضیحاتتون
می خوام بدونم ما یکسری نمونه داریم که برای ارزیابی نگه می داریم؟ و بر اساس اونها ماتریس تشکیل می شود؟
یعنی در مثال بالا ما ۱۰۰ تا نمونه داشتیم و بر روی اونها ارزیابی انجام دادیم؟
آیا می شود با همون نمونه های آموزشی بعد از پیاده سازی جهت ارزیابی استفاده نمود؟
سلام حبیب جان
خیر، معمولاً باید دادههای آزمایشی از دادههای آموزشی جدا باشد و الگوریتم اصلا اونها را تا هنگام تست ندیده باشد
خیلی ممنون از توضیحات خوبتون
خیلی کمک کرد به من
با سلام. اینکه ما از کراس ولیدیشن استفاده کنیم آیا باز هم نمیشه از نمونه های ترین در تست استفاده کرد؟
مثلا اگه ما ۱۰۰۰فرد سالم و ۱۰۰۰ فرد بیمار داشته باشیم و شبکه را هربار ۹۰درصد برای تست و ۱۰ درصد برای ترین در نظر بگیریم و این کار ده بار انجام بدیم تا تمام داده تست شود این کار آیا اشتباه است؟
و سوال دیگر اینکه اگه این کار انجام دهیم در اخر ماتریس اغتشاش آیا جمع اعداد باید همون ده درصد داده باشد یا کل داده باشد یعنی جمع سطر اول باید ۱۰۰ نفر که بیمار هستند و سطر دوم هم ۱۰۰ نفر سالم باشند؟
عالی بود مهندس گرامی