

درختها کاربردِ فراوانی در علومِ کامپیوتر و مهندسی نرمافزار دارند. از ساختمان داده و طراحیِ الگوریتم تا سیستمهای عامل و سیستمهای توزیع شده، همه به نوعی و در قسمتهای مختلف از درختهای تصمیم استفاده کردهاند. در دادهکاوی و طبقهبندی نیز این درختها جایگاهِ ویژهای دارند و بسیاری از الگوریتمهای طبقهبندی بر پایهی این درختها ساخته شدهاند. به آنها درختهای تصمیم میگویند زیرا میتوانند یک تصمیمِ خاص (مثلاً اینکه به یک شخص وام بدهیم یا نه) را بر اساسِ اطلاعاتِ گذشته اتخاذ کنند. اجازه بدهید مانند دروس قبلی، با یک مثال بحث را آغاز کنیم.
فرض کنید شما مدیر یک دانشکده هستید و میخواهید یک طبقه بند (classifier) بسازید تا با کمک این طبقهبند مشخص کنید کدام یک از دانشجوهای این دانشکده میتوانند در آزمون دکتری، قبول شوند (در واقع میخواهید یک پیشبینی انجام دهید). این پیشبینی میتواند باعثِ این شود که شما از این به بعد دانشجویان با پتاسیلِ بالا را پیدا کرده و روی آنها سرمایهگذاری کنید. مثلاً به آنها وامهایی دهید تا بتوانند مقالات بهتری را در نشریات معتبرتر صادر کنند. در واقع میخواهید یک مدلِ طبقهبندی ایجاد کنید تا بتواند توسط دادههای گذشته، یک مدل ساخته و از این به بعد، هر بار که یک دانشجوی جدید را به مدلِ یادگرفته شده دادیم، این مدل بتواند بفهمد که این دانشجو با چه احتمالی میتواند در آزمونِ دکتری قبول شود. همان طور که از دروس گذشته به یاد دارید، باید یک مجموعه داده (dataset) از دانشجویانِ گذشته که در آزمونِ دکتری قبول شدند یا نشدند ایجاد کنیم تا بتوانیم آن را به الگوریتمِ دادهکاوی بدهیم و این الگوریتم یاد بگیرد. فرض کنید مجموعه داده را به این صورت میسازیم:
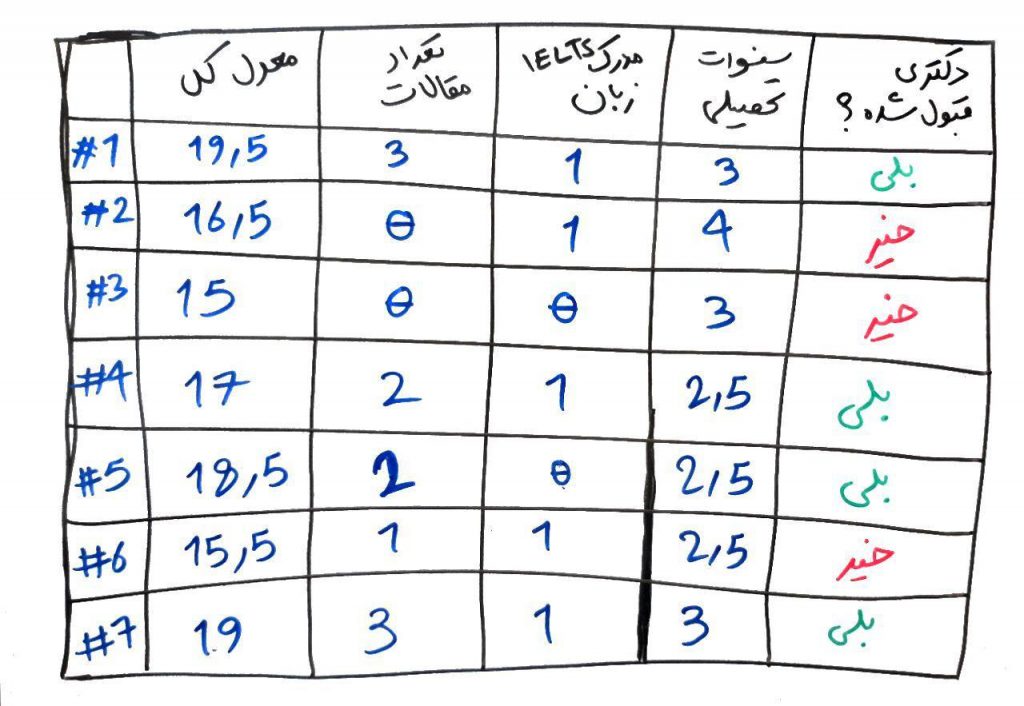
همان طور که میبیند در اینجا دانشجویان قبلیِ ما که مورد بررسی قرار گرفتهاند، ۷دانشجو هستند که هر کدام ۴ ویژگی دارند. ۱. معدل کل (عدد) ۲. تعداد مقالات (عدد) ۳. مدرک IELTS زبان دارند (۰ یا ۱)؟ ۴. سنوات تحصیلی (عدد). و همچنین یک ستونِ برچسب که اگر دانشجو در در مقطع دکتری قبول شده بود، بلی و اگر قبول نشده بود، خیر است. در واقع این دادهها مربوط به دادههای مختلفِ دانشجوهای قبلی هستند که قبلاً در آزمون دکتری شرکت کردهاند.
جدول بالا نوعی دادههای آموزشی است که الگوریتم میتواند از روی آن یاد بگیرد. مثلاً موردِ شمارهی ۱# را نگاه کنید. این دانشجو معدل ۱۹/۵ دارد، تعداد ۳ مقاله ارائه کرده است و مدرک زبان IELTS دارد، همچنین سنوات تحصیلی او ۳ سال بوده است. این دانشجو در مقطع دکتری قبول شده است.
درخت های تصمیم با توجه به دادهها مبادرت به ایجادِ یک ساختارِ درختی میکنند که مانندِ قانونهای IF و ELSE عمل کرده و در نهایت به برچسبهای دلخواهِ ما که از دادههای آموزشی یاد گرفته شدند، میرسند. فرض کنیدمیخواهیم دادههای بالا را به صورت یک درخت بسازیم. شکلِ زیر در واقع یک نمونه درخت تصمیم از روی دادههای بالا است:
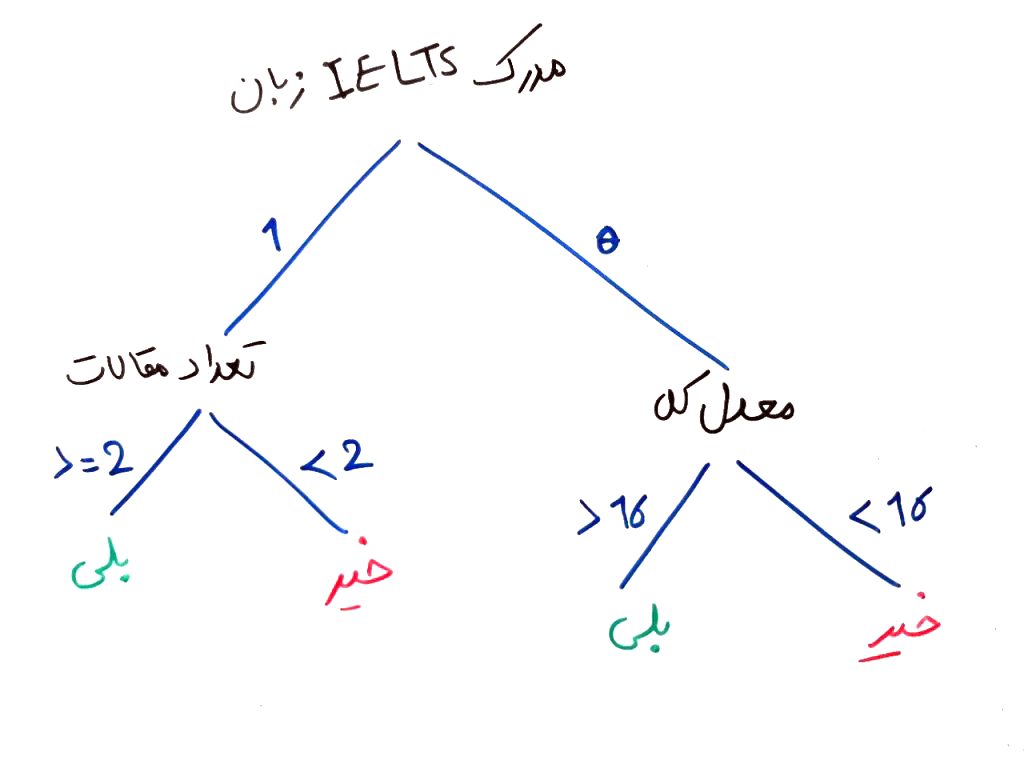
تفسیر شکلِ بالا بسیار ساده است، این شکل میتواند در یک زبان برنامهنویسی به وسیلهی دستورات IF و Else پیادهسازی شود. ریشه این درخت (سطح اول)، این است که آیا شخص مدرک IELTS زبان دارد یا خیر؟ اگر مدرک IELTS داشته باشد به زیر درختِ سمت چپ میرویم و اگر مدرک IELTS زبان نداشته باشد به زیر درختِ سمت راست میرویم. فرض کنید به زیر درخت سمت چپ رفتهایم، حال باید بررسی کنیم که آیا شخص تعداد مقالاتی که ارائه کرده است بیشتر یا مساوی ۲ بوده یا خیر؟ اگر بیشتر یا مساوی ۲ بوده، این شخص احتمالاً میتواند در آزمون دکتری قبول شود. در واقع درخت تصمیم به این نتیجه رسیده است که اگر یک شخص، مدرکِ IELTS زبان داشته باشد و تعداد مقالاتش بیشتر یا مساوی ۲ باشد، این شخص میتواند در آزمون دکتری قبول شود. برای مثالِ دیگر، اگر شخصی، مدرک IELTS زبان داشته باشد (سطح اول درخت) و تعداد کمتر از ۲ مقاله ارائه کرده باشد (سطح دوم در زیر درخت چپ)، الگوریتم تشخیص میدهد که این شخص نمیتواند آزمون دکتری قبول شود. پس وظیفه اصلی یک درخت تصمیم که الگوریتمهای آن را در درس های بعدی خواهیم دید، ساخت این درخت به صورت پویا (بدون کد نویسیِ صریح) است به گونهای که خودِ درخت بتواند از روی دادههای آموزشیِ موجود، شاخهها و برگهای خود را پیدا کند. همان طور که میبینید، برگهای این درخت، همان برچسبهای دادههای آموزشی هستند (مثلاً اینجا دکتری قبول شده است یا خیر).
حال فرض کنید این درخت توسط یکی از الگوریتمهای درختهای تصمیم (decision trees) ساخته شده است. در واقع عملیاتِ یادگیری در درختِ تصمیم، همان ساخت عناصر و برگهای یک درخت است. شما به عنوان رئیسِ دانشکده میخواهید یک دانشجو با مشخصات زیر را بررسی کنید که با توجه به دادههای موجود و درختِ یادگرفته شده، میتواند دکتری قبول شود یا خیر. این کار را به مدل درخت تصمیم که از دادههای گذشته یاد گرفته است، واگذار میکنیم:
این دانشجوی جدید معدل ۱۵.۵ دارد، تعداد ۵ مقاله ارائه کرده است ولی مدرک IELTS زبان ندارد. همچنین ۳ سال سنوات تحصیلی دارد. میخواهیم بدانیم آیا این شخص در آزمون دکتری قبول میشود یا خیر؟
اگر بخواهیم با توجه به درخت ساخته شده در شکل بالا، این دانشجو را ارزیابی کنیم مانند شکل زیر مسیر را ادامه میدهیم تا به یکی از برگها برسیم (مسیر حاشور خورده قرمز):
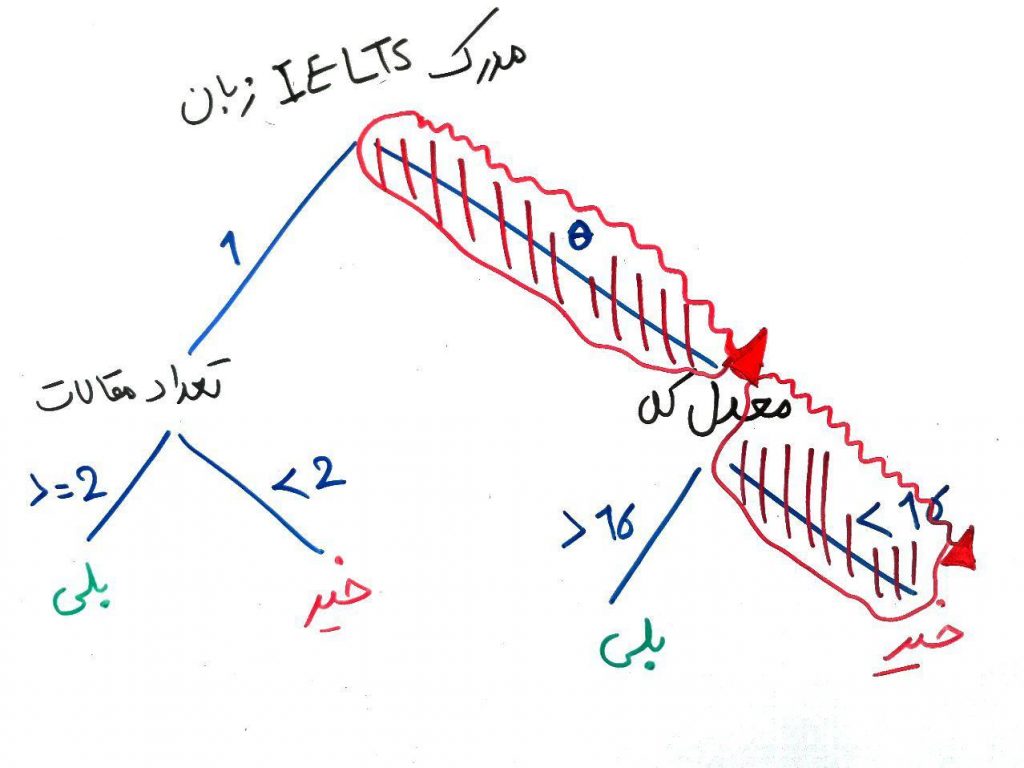
درخت تصمیمِ ساخته شده به ما میگوید که این دانشجو احتمالاً نمیتواند در آزمون دکتری قبول شود. این طبقهبندی با استفاده از درختی که توسط دادههای گذشته ساخته بود، انجام شد.
این یک مثال ساده برای فهمِ نحوهی کارکردِ یک درخت تصمیم بود. در دنیای واقعی، ابعاد (یعنی همان ویژگی ها) و تعداد نمونهها – در اینجا تعداد دانشجویان در مجموعه دادهی آموزشی – معمولاً خیلی بیشتر از اینها است و کارِ ساختِ درختِ تصمیم بر عهدهی الگوریتم و کامپیوتر است. در دروس بعدی به نحوه ساخت و چینش شاخهها و برگها در الگوریتمهای مختلفِ درخت تصمیم خواهیم پرداخت.

- ۱ » الگوریتم K نزدیک ترین همسایه (KNN)
- ۲ » درخت های تصمیم جهت طبقهبندی (Decision Trees)
- ۳ » الگوریتم درخت تصمیم ID3 و ساختار Entropy و Gain
- ۴ » آشنایی با مفهوم Overfitting و Underfitting در طبقهبندی
- ۵ » آشنایی با مفهوم Bias و Variance در طبقهبندی
- ۶ » الگوریتم طبقهبندی درخت تصمیم C4.5
- ۷ » الگوریتم طبقه بند درخت تصمیم CART
- ۸ » طبقه بند ترکیبی (Ensemble Classifier) و مبحث Bagging و Boosting
- ۹ » الگوریتم جنگل تصادفی (Random Forest)
- ۱۰ » رگرسیون لجستیک (Logistic Regression)
- ۱۱ » مسائل طبقهبندی دودویی (binary)، چند کلاسه (Multi Class)، چند برچسبه (Multi Label) و تفاوت آنها
- ۱۲ » روش «یک در مقابل همه (One vs. All)» برای طبقهبندی دادههای چند کلاسه
- ۱۳ » روش «یک در مقابل یک (One vs. One)» در طبقهبندی
- ۱۴ » مدلهای احتمالی در مقابل مدلهای قطعی در طبقهبندی دادهها
- ۱۵ » ماتریس اغتشاش (Confusion Matrix) و معیار دقت (Accuracy)
- ۱۶ » معیار صحت (Precision)، پوشش (Recall) و معیار F
- ۱۷ » معیار کاپا (Kappa) برای ارزیابی طبقهبندیهای چندکلاسه
سلام واقعا ممنونم ،من براي کار پايان نامم بايد بلد ميشدم توضيحات الگوريتم درخت تصميم و جنگل تصادفي رو که شما واقعا عالي توضيح دادين خيلي متشکرم
ممنونم عالی توضیح دادین….خدا خیرتون بده
عرض سلام و ادب و احترام
استاد عزیز سوالم اینه که الگوریتم درخت تصمیم چجوری دچار overfit میشه ؟ و راه کار حل این مشکل چیه؟
ممنون از وب سایت خوبتون
سلام میثاق جان
معمولا درخت تصمیم به خاطر عمق زیاد و یا سادگی در طراحی دچار overfit میشه که با تکنیکهایی مانند هرس کردن (tree pruning) و یا استفاده از الگوریتمهای جایگزین مانند جنگل تصادفی (random forest) میشه مشکلش رو حل کرد
در پاراگراف یکی مانده به آخر:
“درخت تصمیمِ ساخته شده به ما میگوید که این دانشجو احتمالاً نمیتواند در آزمون دکتری قبول شود”
کلمه احتمالاً به نظر اشتباه می آید چونکه نتیجه نهایی درخت تصمیم بله یا خیر هست و احتمالی در کار نیست.
سلام میشه این سوال رو پاسخ بدید
اگر به شما گفته شود که نتیجه دسته بندی درخت شما برای مثالهای فوق اشتباه است روشی برای تصحیح درخت بیان کنید که بدون نیاز به ساخت مجدد درخت قادر به دسته بندی صحیح نمونه های آموزشی و مثالهای فوق باشد.
ممنون از مقاله مفیدتون . خوشحال میشم مقاله درخت تصمیم به آدرس زیر رو هم مطالعه بفرمایید:
https://behtime.ir/main/درخت-تصمیم
با سلام و خسته نباشید. واقعاً زحمت زیادی متحمل شده اید و کمال تشکر رو از شما دارم
یک سوال داشتم که عرض می کنم:
در مثال آخری که مثال قبولی در امتحان دکتری با ۴ بعد آمده است وقتی که از طریق درخت تصمیم جلو می رویم با توجه به اینکه IElTS ندارد در شاخه ای قرار می گیرد که به جای سوال در مورد تعداد مقالات مانند شاخه سمت چپی, از معدل سوال نموده است سوال اینجاست که نباید در درخت تصمیم روند جلو رفتن از شاخه ها و ایستگاههای سنجش ابعاد مشابه باشند. به عبارتی روش کار و به نتیجه رسیدن نباید یکسان باشد؟
سلام
بسیار عالی و قشنگ توضیح دادین یعنی لذت بردم از این تدریس قشنگتون
ان شالله خیر دنیا و آخرت نصیبتون بشه و سلامت و برقرار باشید