

با درختهای تصمیم در درس گذشته آشنا شدید. الگوریتم ID3 یکی از الگوریتمهای پایه برای ساختِ درختهای تصمیم است. همانطور که در درس گذشته گفتیم، در یک درخت تصمیم، مهم است که کدام یک از ویژگیها (یا همان ابعاد) را در سطوح بالاتری از درخت انتخاب کنیم تا به طبقهبندی کمک کند.
به درس قبل برگردیم و دوباره مجموعه داده و درخت تصمیمی که کشیدیم را نگاهی بیندازیم:
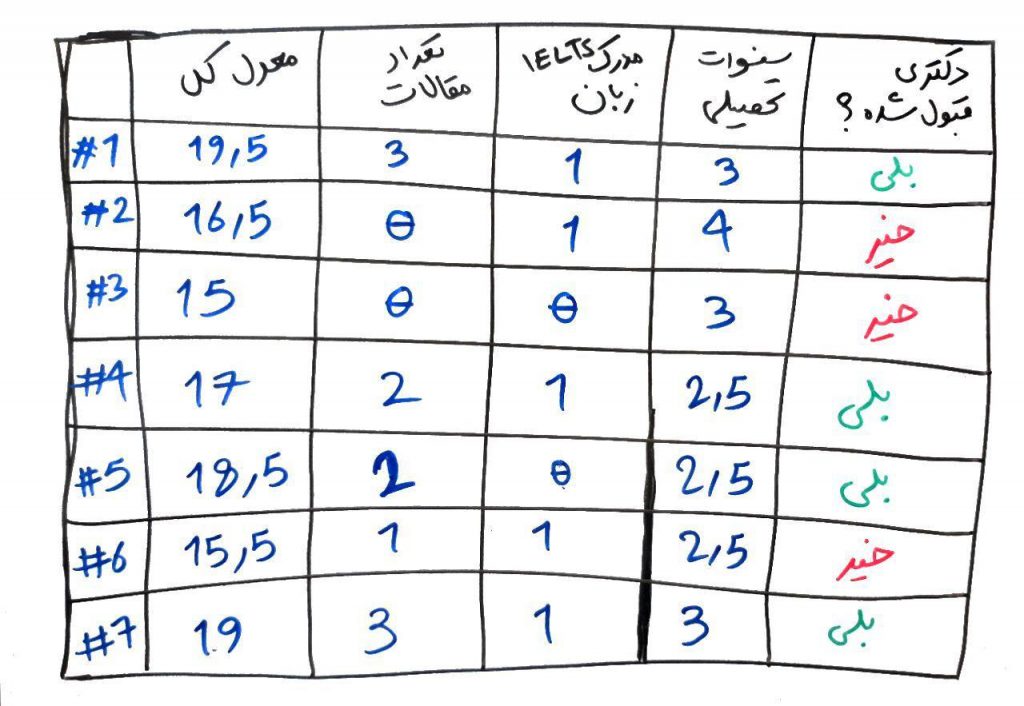
که درخت پیشنهادی ما برای این مجموعه داده به این صورت بود:
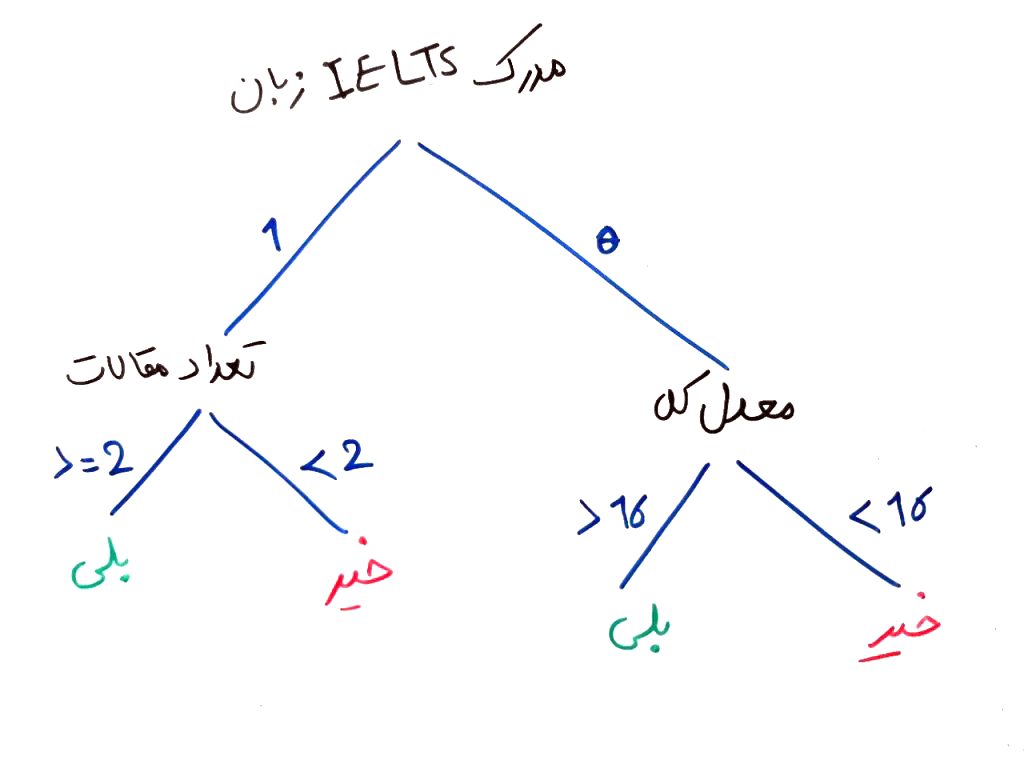
آیا این درخت را نمیتوان به صورت های دیگری کشید؟ مثلاً فرض کنید از روی مجموعه دادهها، میتوان به درخت زیر نیز دست پیدا کرد:
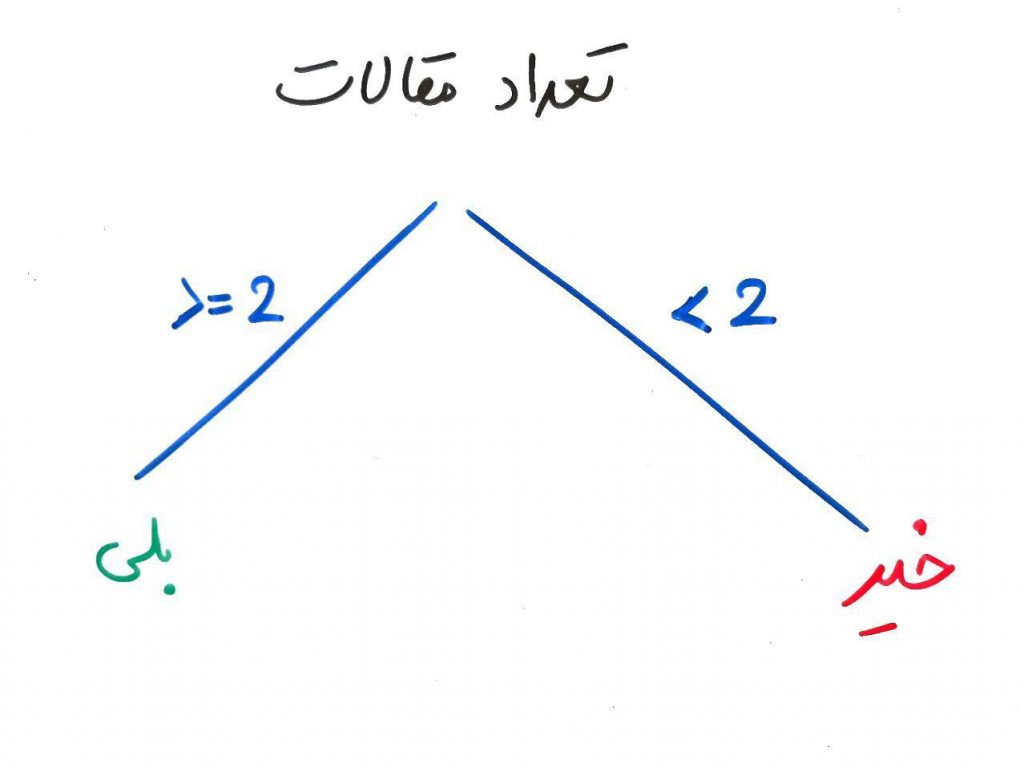
همان طور که میبینید، این درخت به سادگی و فقط با انتخابِ درستِ یک ویژگی (بُعد) که همان تعداد مقالاتِ ارائهشده بود، میتواند فقط یک سطح داشته باشد (به جای دو سطح) و خیلی سادهتر تصمیم بگیرد. اما چگونه این ویژگیِ بهینه را انتخاب کنیم؟ اینجاست که بایستی با واژههایی به نام Entropy و Gain آشنا شویم.
نمیخواهیم اینجا از فرمولهای ریاضیِ Entropy و Gain استفاده کنیم. اجازه بدهید به صورت ساده و انتزاعی ببینیم این دو مفهوم چه هستند. Entropy در واقع نشان دهندهی کم بودن اطلاعات است. یعنی در مجموعهی دادهی شما، بر اساسِ یک ویژگی (یک بُعد) چقدر میتوانید تشخیص دهید که کلاسِ نهایی چیست. مثلاً ویژگیِ مدرک IELTS را در مجموعهی دادهی بالا در نظر بگیرید. همان طور که میبینید ۵ نفر دارای مدرک زبان IELTS هستند که از این تعداد ۳ نفر توانستهاند دکتری بگیرند و ۲ نفر نتوانستهاند دکتری بگیرند. یعنی یک حالتِ تصادفی در بین برچسبها داریم. همچنین ۲ نفر مدرک زبان IELTS ندارند که یکی از آنها توانسته مدرک دکتری بگیرد ولی دیگری نتوانسته این کار را انجام دهد (مانند شیر یا خط که یک حالت کاملاً تصادفی دارد). این نشان میدهد که ویژگیِ مدرک IELTS احتمالاً نمیتواند گزینه گسسته سازِ خوبی برای طبقهبندی باشد. یعنی این ویژگی اطلاعاتِ زیادی به ما نمیدهد. در واقع این ویژگی دارای مجموع Entropy بالا است و در نتیجه اطلاعات کمتری دارد.
برای درک Entropy میخواهم یک مثال دیگر را هم بیاورم. فرض کنید، کسی به شما میگوید که محل زندگیاش استانِ اصفهان است. خب این یعنی اطلاعات زیادی به شما نداده است. ولی شخص دیگری میگوید که محل زندگیاش در استانِ اصفهان و شهرِ اصفهان است. شخص دوم در واقع Entropy کمتری دارد، یعنی فضا را محدودتر کرده و اطلاعات بیشتری به شما داده است. زیرا حالا شما میدانید از میان شهرهای استان اصفهان، این شخص در شهرِ اصفهان (یک محدودهی مشخصتر) قرار دارد.
Gain که در واقع همان Information Gain است، از Entropy در هر مقدار از ویژگیها کمک گرفته و به میزانِ اطلاعاتی که میتوان از یک ویژگی (بُعد) به دست آورد، گفته می شود. یعنی یک ویژگیِ خاص چقدر میتواند اطلاعاتِ بیشتری به ما بدهد. همان طور که در مثال بالا دیدیم، ویژگیِ تعداد مقالاتِ ارائه شده (که یک مرز بالاتر یا مساوی ۲، و کوچکتر از ۲ داشته باشد) اطلاعاتِ بیشتری نسبت به ویژگی مدرک IELTS به ما میدهد. در واقع اگر ویژگیِ تعدادِ مقالات را به عنوان ریشهی درخت انتخاب کنیم، احتمالاً درختِ بهتری خواهیم داشت و زودتر به نتیجه خواهیم رسید.
الگوریتم ID3 وظیفه پیدا کردنِ ویژگیهایی دارای اطلاعات زیادتر (Gain بیشتر) را دارد و آنها را در سطوحِ بالاتری از درخت قرار میدهد. هر بار که یک ویژگی در سطحی از درخت انتخاب شد، زیر درختهای آن نیز دقیقا به همان صورت (ویژگیهایی با اطلاعات بالا) انتخاب میشوند و در سطوح و گرههای بعدی قرار میگیرند. البته وقتی یک گره از درخت انتخاب شد، برای ساختِ زیر درختهای دیگر، مجموعه دادهها بر اساس مقدارِ گرهی انتخاب شده در شاخههای بالاتر، کوچکتر میشوند و هر چه در درخت پایینتر میرویم (به برگها نزدیکتر میشویم)، مجموعه دادهها برای محاسبهی مقدار اطلاعات کمتر میشوند. یک نمونه از ساخت درخت را میتوانید در این مثال از دانشگاه فلوریدا مشاهده کنید.
البته نکتهای که باید در نظر داشت این است که مدلِ اولیه ID3 برای ویژگیهای پیوسته تولید نشده بود. برای مثال درخت ID3 اولیه نمیتوانند بفهمد که تعداد مقالات ۳ بزرگتر از ۲ است یا نه و نتیجتاً نمیتواند درختی مانند درخت بالا (که بزرگتر از ۲ و یا کوچکتر از ۲ را تشخیص داد) بسازد. این درخت فقط میتواند مقادیر گسسته را مشاهده کند، یعنی مقادیری که به صورت عددی نیستند (در مثال دانشگاه فلوریدا مشخص است). مثلاً اینکه شخصی مدرک IELTS دارد یا نه یک حالت گسسته است (داشتن یا نداشتن بالاتر از آن یکی نیست) و یا اینکه این شخص مَرد است یا زن. برای غلبه بر این مشکل و یک سری مشکلات دیگر الگوریتمهای پیشرفتهتری مانند C4.5 و CART به وجود آمدند که در دروس بعدی به آنها خواهیم پرداخت.

- ۱ » الگوریتم K نزدیک ترین همسایه (KNN)
- ۲ » درخت های تصمیم جهت طبقهبندی (Decision Trees)
- ۳ » الگوریتم درخت تصمیم ID3 و ساختار Entropy و Gain
- ۴ » آشنایی با مفهوم Overfitting و Underfitting در طبقهبندی
- ۵ » آشنایی با مفهوم Bias و Variance در طبقهبندی
- ۶ » الگوریتم طبقهبندی درخت تصمیم C4.5
- ۷ » الگوریتم طبقه بند درخت تصمیم CART
- ۸ » طبقه بند ترکیبی (Ensemble Classifier) و مبحث Bagging و Boosting
- ۹ » الگوریتم جنگل تصادفی (Random Forest)
- ۱۰ » رگرسیون لجستیک (Logistic Regression)
- ۱۱ » مسائل طبقهبندی دودویی (binary)، چند کلاسه (Multi Class)، چند برچسبه (Multi Label) و تفاوت آنها
- ۱۲ » روش «یک در مقابل همه (One vs. All)» برای طبقهبندی دادههای چند کلاسه
- ۱۳ » روش «یک در مقابل یک (One vs. One)» در طبقهبندی
- ۱۴ » مدلهای احتمالی در مقابل مدلهای قطعی در طبقهبندی دادهها
- ۱۵ » ماتریس اغتشاش (Confusion Matrix) و معیار دقت (Accuracy)
- ۱۶ » معیار صحت (Precision)، پوشش (Recall) و معیار F
- ۱۷ » معیار کاپا (Kappa) برای ارزیابی طبقهبندیهای چندکلاسه
خیلی خوب توضیح داده بودید، واقعا ممنون
مفاهیم اولیه را با توضیح عالیتون متوجه شدم ، کاش فرمول های انتروپی هم با همین بیان زیبا گفته بودین
با عرض سلام و خدا قوت و تشکر فراوان از این سخاوت شما در نشر علم و دانش
بسیار عالی و روان توضیح دادید
با سلام..بسیار عالی و مفید ..ای کاش این قیاس بین انتروپی و جینی تا دسته بندی با خطای اندازه گیری بصورت شکل ادامه پیدا می کرد..
خیلی عالی بود، تشکر
بسیار ممنون
ممنونم.توضیحتون مختصر و مفید بود
:سلام من دانشجو ارشد هستم یک مقاله دارید با موضوع زیر باشد برا پروپزال وپایان نامه می خواهم ممنون
ارائه روشی برای ارتقاء سطح تحصیلی با استفاده از الگوریتم درخت تصمیم id3 بهینه شده و منطق فازی
سلام
نه متاسفانه، جستجو کنید تو Scholar
توضیحات شما محشره
سلام ممنون از مطلب مفیدتون .
لطفا لینک مثال دانشگاه فلوریدا را رنگی کنید تا افراد دیگه راحت تر تشخیص بدهند.. همچنین حس میکنم گوگل خوشش نمیاد از لینک همرنگ محتوا و به ضرر سایت خوبتونه .
با سلام ممنون از توضیحات خوبتون.اگر در صورت سوال داده بشه که ساده ترین درخت تصمیم رو با توجه به داده های آموزشی رسم کنید باید از روش اول شما استفاده کرد یا از id3
با سلام واقعا عالی توضیح داده اید ممنون
خوب بود.
باریکلا انجا که از معنای اماری رفتی به انتزاعی خیلی ایده خوبی بود
سلام
وقت بخیر
برای این متغییر ها تعداد بیشتری داده دارید مثلا ۱۰۰ تا
میخواهم درخت را برای ۱۰۰ داده با ۴ متغییر در دو کلاس رسم کنم