

در چند درس گذشته به توزیعهای آماری و فاصلهی آماری اشاره کردیم. در این درس میخواهیم یکی از معیارهای فاصلهی آماری به نام واگرایی کولبک-لیبلر که به صورت مخفف واگراییِ KL نیز خوانده میشود بپردازیم و ببینم که چگونه میتوان با استفاده از این معیار، فاصلهی بین دو مجموعهی داده را به صورت آماری محاسبه کرد.
فرض کنید در دانشگاهی هستیم و یک استاد مدعو برای درس مبانی کامپیوتر به دانشگاه میآید. میخواهیم ببینیم که آیا نمراتی که این این استادِ مدعو به دانشجویان میدهد با استادِ اصلی این درس که هیئت علمی دانشگاه بوده و در ترمهای گذشته درس مبانی کامپیوتر را تدریس میکرده، تفاوتی دارد یا خیر. برای این کار دو مجموعهی داده از نمرات درس مبانی کامپیوتر در دو گروه دانشجویان جمعآوری میکنیم. گروه اول دانشجویانِ استاد اصلی درس (A) و گروه دوم دانشجویان استاد مدعو (B) در درس مبانی کامپیوتر هستند و توزیع نمرات هر گروه در شکل زیر مشخص شده است:
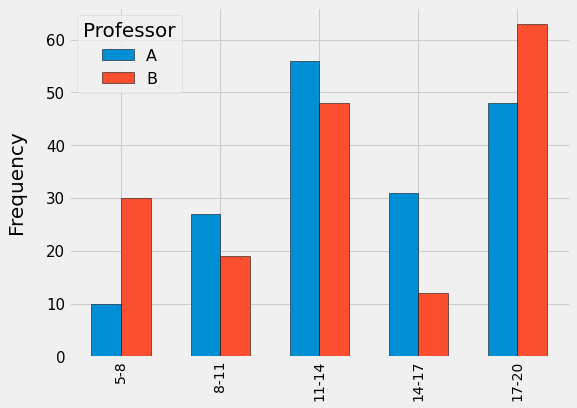
در شکل بالا، توزیع نمرات گروه A (استاد اصلی) با رنگ آبی و توزیع نمرات گروه B (استاد مدعو) با رنگ قرمز مشخص شده است. برای درک بهتر، نمودار هیستوگرام را جدا جدا برای هر بازه رسم کردهایم. توجه داشته باشید که برای مقایسهی دو توزیع بایستی بازهی تقسیمشده برای دو گروه شبیه به هم باشد. برای مثال در شکل بالا نمرات از بازهی ۵ تا ۲۰ قرار داشتهاند که ما این بازه را به ۵ قسمت تقسیم کردهایم. مثلاً تعداد ۱۰ دانشجو در گروه A، نمرهای در بازهی ۵ تا ۸ گرفتهاند و در گروه B برای همین بازه (۵ تا ۸)، تعداد ۳۰ دانشجو موجود بودهاند.
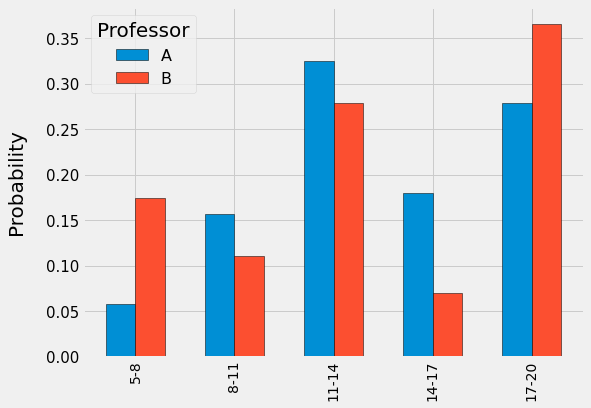
اگر نمرات بخواهیم دو گروه A و B را با استفاده از واگرایی KL با یکدیگر مقایسه کنیم، ابتدا بهتر است آنها را به حالت احتمالی تبدیل کنیم. یعنی به جای تعداد تکرار (frequency) در محور عمودی، احتمال هر کدام از قسمتها قرار بگیرد. برای این کار کافیست تعدادِ تکرار هر قسمت در هر گروه را تقسیم بر جمع کل همان گروه کنیم تا شکلِ بالا به شکل زیر تبدیل شود:
حال بایستی با استفاده از فرمولِ واگراییِ KL، دو توزیع را به صورت نظیر به نظیر در هر قسمت با یکدیگر مقایسه کنیم. فرمول واگرایی KL به صورت زیر است:
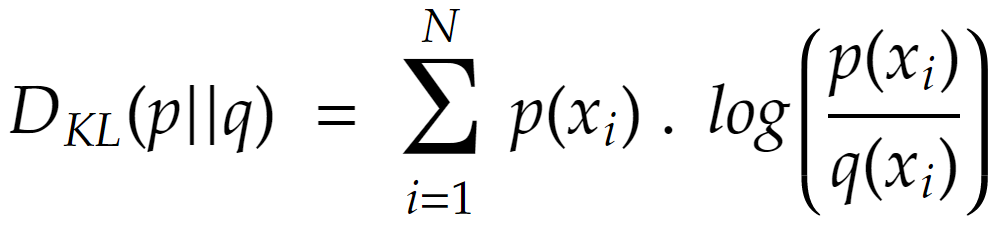
در فرمول بالا مشخص است که اگر بخواهیم میزان اختلاف بین توزیع p با q را به دست بیاوریم بایستی برای هر کدام از قسمتهای توزیع p، احتمالِ هر قسمت p را مطابق فرمولِ بالا با احتمال متناظر توزیع q محاسبه کنیم. برای مثال در نمونهی بالا برای قسمت اول، فرمول به صورت زیر محاسبه میشود:
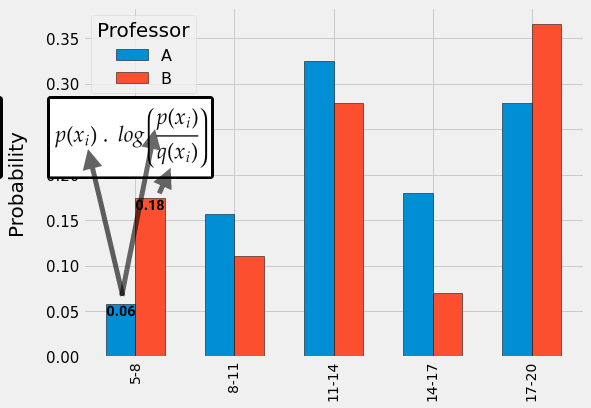
در شکل بالا مشاهده میکنید که برای یک قسمت از پنج قسمت به جای احتمال p و q میتوانیم مقادیر مناسب را قرار دهیم. در اینجا p گروه A (نمرا استاد اصلی) است و q گروه B (نمرات استاد مدعو). همین کار را برای تمامیِ قسمتها انجام داده و سپس نتیجه را با یکدیگر جمع میکنیم. خروجی نهایی، همان معیار واگراییِ KL خواهد شد.
هر چقدر عددِ به دست آمده در معیارِ واگرایِ KL بزرگتر باشد به این معنی است که توزیع q کمتر به توزیع p شباهت دارد. مثلاً در این مثال میتوانیم بگوییم که اگر KL بین نمرات استاد مدعو و استاد اصلی درس بیشتر از یک عدد خاص (مثلا ۰/۲۰) شد، نمرات بایستی توسط یک استادِ سوم مورد بازبینی قرار بگیرد.
توجه کنید که به معیارِ واگرایی KL، نمیتوانیم معیار فاصله (distance) بگوییم. چون واگرایی p از q با واگرایی q از p برابر نیست. به همین دلیل است که به جای واژهی فاصله در فرمول از واژهی واگرایی (divergence) استفاده میشود.
البته کاربردهای واگرایی KL بسیار زیاد بوده و در تولید الگوریتمهای یادگیری ماشین و یادگیری عمیق نیز استفادههایی از این معیار میشود. در دروس آینده به کاربردهای دیگر این معیار میپردازیم.

- ۱ » تحلیل اکتشافی دادهها (Exploratory Data Analysis) چیست؟
- ۲ » انواع مختلف دادهها در دادهکاوی کدامند؟
- ۳ » منظور از دادههای مستطیلی (Rectangular Data) چیست؟
- ۴ » داده پرت (Outlier) در دادهکاوی چیست؟
- ۵ » تخمین مکان دادهها (Estimation Of Location) چیست و انواع مختلف آن کدامند؟
- ۶ » تخمین تنوع و پراکندگی (Estimation Of Variability) و انواع مختلف آن
- ۷ » چارک (Quartile) و IQR در دادهها و کاربردهای آن
- ۸ » چولگی (Skewness) در دادهها
- ۹ » کشیدگی یا برجستگی (kurtosis) در دادهها
- ۱۰ » چگونه با EDA در دادهها اکتشاف کنیم؟
- ۱۱ » نمونهگیری آماری و محاسبهی حداقل تعداد نمونه (Min Sample Size)
- ۱۲ » توزیعهای آماری (Statistical Distributions)
- ۱۳ » فاصلهی آماری (Statistical Distance) و کاربردهای آن
- ۱۴ » واگرایی کولبک-لیبلر (Kullback-Leibler Divergence) و کاربرد آن در فاصلهی آماری
- ۱۵ » فاصلهی جنسون-شنون (Jenson-Shannon) برای مقایسهی توزیعهای آماری