

آنهایی که با پایگاه دادههای رابطهای مانند SQL کار کردهاند بسیار خوب مفهوم جدول را میدانند و میدانند که یک جدول در واقع یک مستطیل از دادهها است که سطر و ستون دارد. حتی اگر با SQL هم کار نکرده باشید با Excel که آشنا هستید. جدول گستردهای از صفحات که دارای سطر و ستون است. در دادهکاوی معمولا سعی میشود که دادهها به صورت مستطیلی یا همان Rectangular شکل بگیرد تا بتوانند عملیات بندی مانند طبقهبندی یا خوشهبندی را بر روی آنها انجام دهند. در مثال درسهای طبقهبندی و خوشهبندی دو نوع دادهی مستطیلی دیدیم که هر کدام سطر و ستون خاص خود را داشتند.
سطرها در دادههای مستطیل همان نمونهها (Samples) ما هستند. برای مثال یک مجموعه داده دانشجویان را در نظر بگیرید که کدام ویژگیهای مشخصی دارند. مثلا سن، معدل، قد، جنسیت و… . به شکل زیر نگاه کنید:
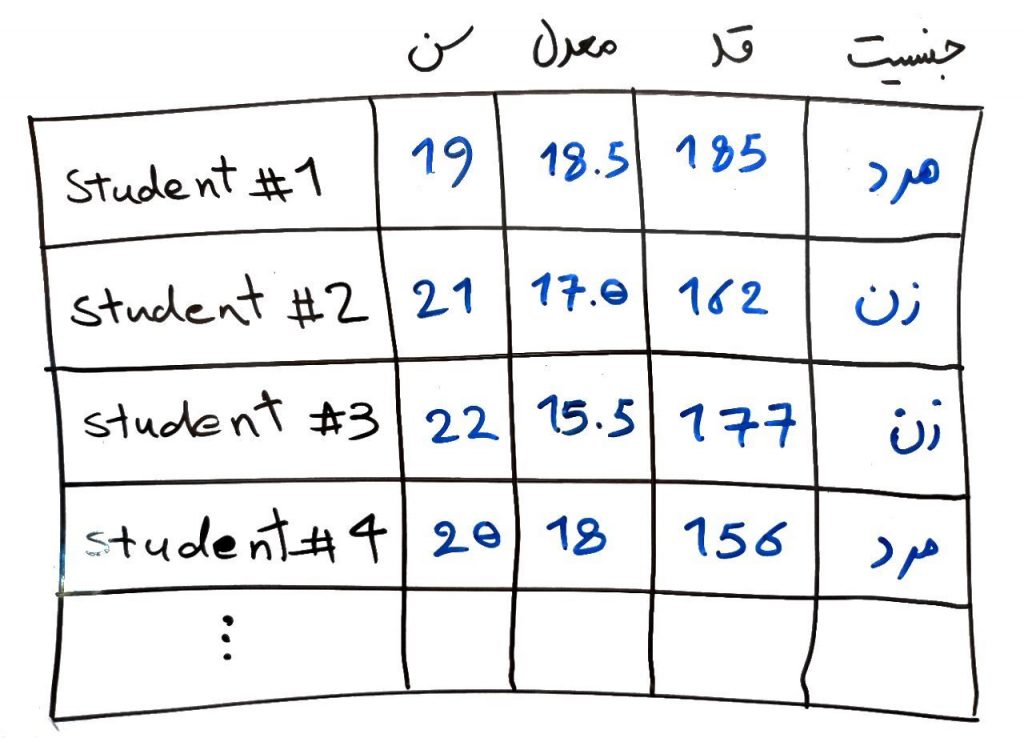
در این شکل هر سطر یک نمونه یا Instance یا رکورد (Record) نامیده میشود که بیانگر یک دانشجو است. هر دانشجو میتواند چندین ویژگی (ستونها) داشته باشد. در درس ویژگی یا بعد چیست کامل به این موضوع پرداختهایم. به این ترتیب دادهها را میتوان به شکل مستطیلی درآورد. حتی اگر دادهای شکل مستطیلی نداشت میتوان آن را به حالت مستطیلی درآورد. برای این کار روشهای مختلفی است که یکی از آنها را برای سادگی اینجا میآوریم. One Hot Encoding در واقع روشی برای تبدیل دادههای غیرعددی به عددی است که میتوان از آن برای ساخت دادههایی با شکل مستطیلی استفاده کرد. برای مثال در همان شکل بالا جنسیت را در نظر بگیرید. اگر بخواهیم این جنسیت را هم به یک ویژگی عددی تبدیل کنیم تا مانند ستونهای دیگر بتواند مقدار عددی بگیرد به صورت زیر تبدیل میشود:
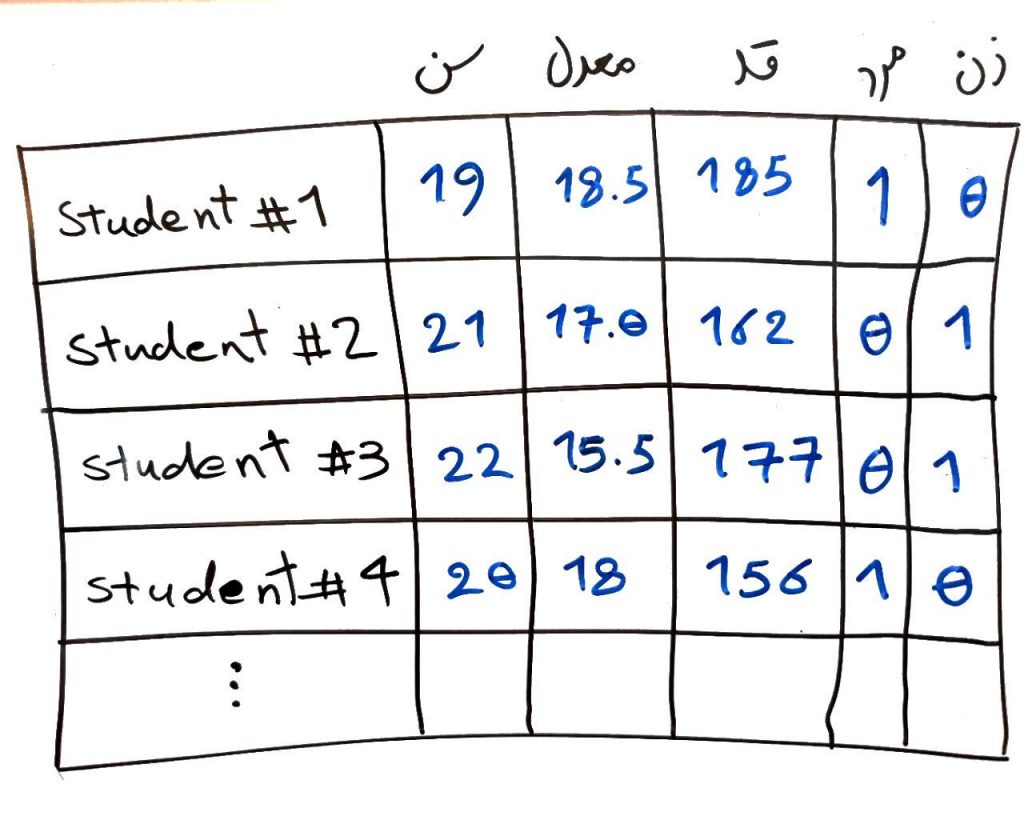
چون دو جنس (مرد و زن) داریم باید دو ستون اضافه کنیم و آنجایی که دانشجو مرد است، ستون مرد برابر ۱قرار میگیرد و ستون زن برابر ۰ و برای بالعکس برای زنها. به همین راحتی میتوان تبدیل One Hot Encoding را انجام داد و تمامی ویژگیها را به ویژگیهای عددی تبدیل کرد.

- ۱ » تحلیل اکتشافی دادهها (Exploratory Data Analysis) چیست؟
- ۲ » انواع مختلف دادهها در دادهکاوی کدامند؟
- ۳ » منظور از دادههای مستطیلی (Rectangular Data) چیست؟
- ۴ » داده پرت (Outlier) در دادهکاوی چیست؟
- ۵ » تخمین مکان دادهها (Estimation Of Location) چیست و انواع مختلف آن کدامند؟
- ۶ » تخمین تنوع و پراکندگی (Estimation Of Variability) و انواع مختلف آن
- ۷ » چارک (Quartile) و IQR در دادهها و کاربردهای آن
- ۸ » چولگی (Skewness) در دادهها
- ۹ » کشیدگی یا برجستگی (kurtosis) در دادهها
- ۱۰ » چگونه با EDA در دادهها اکتشاف کنیم؟
- ۱۱ » نمونهگیری آماری و محاسبهی حداقل تعداد نمونه (Min Sample Size)
- ۱۲ » توزیعهای آماری (Statistical Distributions)
- ۱۳ » فاصلهی آماری (Statistical Distance) و کاربردهای آن
- ۱۴ » واگرایی کولبک-لیبلر (Kullback-Leibler Divergence) و کاربرد آن در فاصلهی آماری
- ۱۵ » فاصلهی جنسون-شنون (Jenson-Shannon) برای مقایسهی توزیعهای آماری
ممنون از دوره خوبتون؛
در مورد One Hot Encoding که برای ویژگی جنسیت انجام دادید یه سوال داشتم. آیا بهتر نبود به جای اینکه دو ستون تشکیل بدیم یکی برای مرد و دیگری برای زن (کاری که شما کردید)، همون یک ستون جنسیت رو داشته باشیم ولی به جای نوشتن جنسیت، از صفر (برای مرد) و یک (برای زن) در همون ستون جنسیت استفاده کنیم؟
خب ابتدا باید مشخص کرد هر کدام از صفر و یک ها برای کدام ویژگی هست که خود نیازمند جدولی دیگر می شود
ممنون میشم آموزش هم در زمینه index برای SQL تهیه کنید