

فرض کنید مدیر یک بانک هستید و میخواهید سیستمی هوشمند ایجاد کنید و این سیستم بتواند تشخیص دهد که یک مشتریِ متقاضی وام، آیا میتواند وام خود را پس دهد یا خیر؟ برای ایجاد این سیستم با استفاده از الگوریتمهای شبکههای عصبی نیاز به مجموعهی دادهای از مشتریان سابق به همراه ویژگیهای آنها داریم. مشتریانی که برخی از آنها توانستهاند وام خود را بازگردانند و برخی نتوانستهاند این کار را انجام دهند.
شکل زیر قسمتی از دادهها را نمایش میدهد:
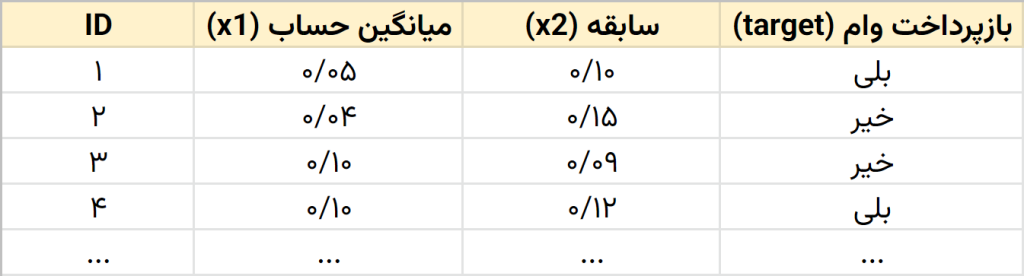
مشاهده میکنید که هر سطر از مجموعهی دادهی شکل بالا، یک مشتری را نمایش میدهد که بعضی از مشتریان وام خود را پس دادهاند و بعضی خیر. هر مشتری دو ویژگی (متغیر) دارد. میانگین حساب (x1) و سابقه (x2) ویژگیهای هر مشتری هستند که از الگوریتم شبکهی عصبی انتظار داریم با یادگیری از روی مجموعهی دادهی بالا، بتواند عملیات طبقهبندی (classification) را انجام دهد. الگوریتم بعد از یادگیری بایستی بتواند مشتریان جدید را مشاهده کرده و پیشبینی کند که میتوانند وام خود را بازپرداخت کنند یا خیر.
الگوریتمِ شبکهی عصبی با مشاهدهی مجموعهی دادهی بالا، یکی یکی سطرها را دریافت میکند تا بتواند با آپدیت کردن وزنهای خود، یادگیری را انجام دهد. پس یک معماریِ ساده برای الگوریتم شبکهی عصبی جهت یادگیری از مجموعهی دادهی بالا میتواند به صورت زیر باشد:
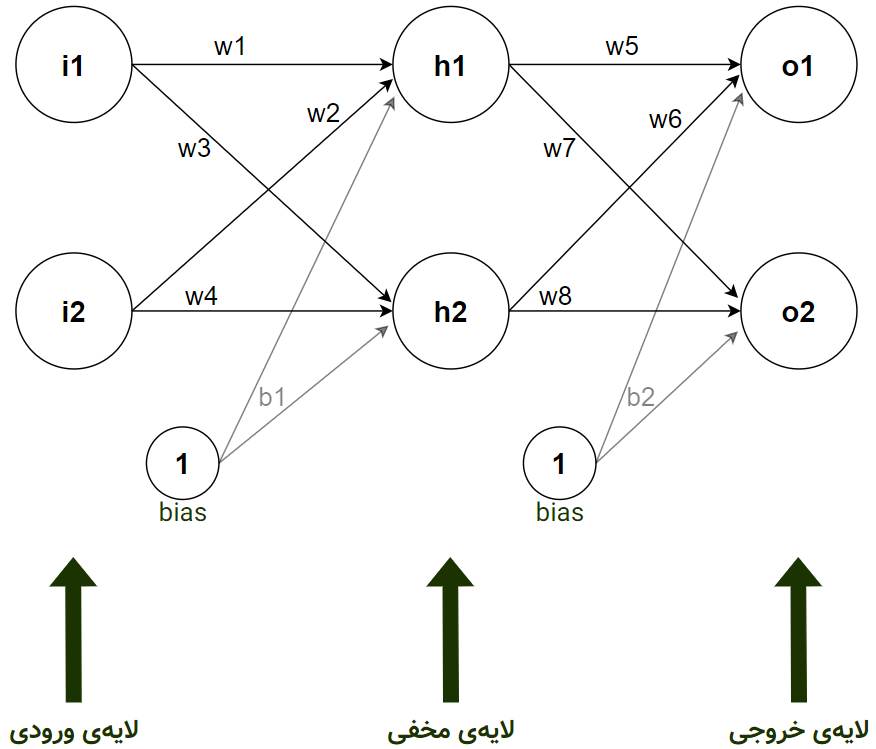
در این معماری شبکه، سه لایه وجود دارد. دو نورون ورودی در لایهی اول داریم (i1 و i2) که هر کدام مربوط به یک ویژگی (میانگین حساب به i1 و سابقه به i2 ) میشود. در واقع هر مشتری با دو ویژگی به این دو نورون تزریق میشود. یک لایهی مخفی با دو نورون هم ایجاد کردهایم (h1 و h2) . توجه کنید که تعداد لایههای مخفی و نورونهای آنها میتواند به دلخواه زیاد و کم شود. دو نورون نیز در لایهی خروجی داریم (o1 و o2). نورون اول در لایهی خروجی (o1) برای خروجیِ «خیر»، یعنی عدم توانایی شخص در بازگرداندن وام است و نورون دوم (o2) برای خروجیِ «بلی» به معنای توانایی شخص در بازگرداندن وام است. تمامی نورونها نیز تابع از فعالسازی سیگموید (sigmoid) استفاده میکنند.
شبکهی عصبی بایستی یاد بگیرد که با دو ورودی که در واقع همان دو ویژگی از یک مشتری هستند، یکی از خروجیها را به یک (۱) و دیگری را به صفر (۰) نزدیک نماید و با این کار بگوید که این مشتری خواهد توانست وام را پس دهد یا خیر. برای مثال شکل زیر یک حالت اولیه از الگوریتم است:
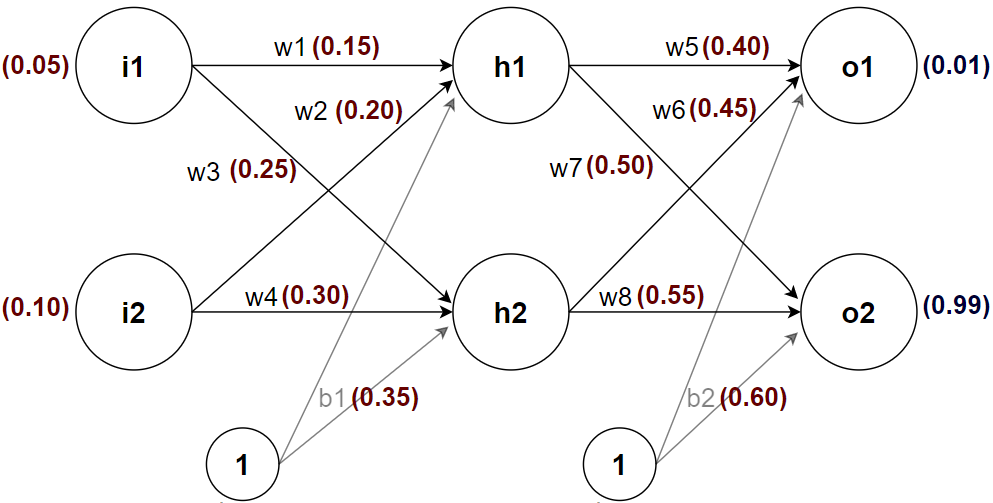
در این شکل یک مشتری (مشتری با شناسهی ۱ در مجموعهی دادهی بالا) با میانگین حساب ۰/۰۵ و سابقهی ۰/۱۰ به الگوریتم تزریق شده است و الگوریتم بایستی خروجیِ o2 را به یک نزدیک کرده و خروجیِ o1 را به صفر نزدیک کند (چون این شخص توانسته است وام خود را پس دهد). در واقع وزنها در هنگام یادگیری بایستی به گونهای آپدیت شوند که با مشاهدهی این ورودی، خروجیِ مد نظر ما را تولید کنند. وزنهای بالا به صورت تصادفی انتخاب شدهاند تا با ضرب آنها در ورودیها به یک خروجی برسیم.
در اینجا اعدادد ۰/۰۱ و ۰/۹۹ را به الگوریتم دادهایم تا از الگوریتم بخواهیم وزنهای خود را به نحوی آپدیت کند که به همچین خروجی دست پیدا کند. میتوانیم مقدار نورون o1 را برابر صفر (۰) و مقدار نورون o2 را برابر یک (۱) قرار دهیم ولی برای این آموزش ترجیح دادیم به همین صورت باشد. توجه داشته باشید که در هنگام آموزش خروجی مورد انتظار را میدانیم. مثلاً همانطور که در جدولِ مجموعهی داده بالا مشخص است این شخص توانسته است وام خود را بازگرداند. پس به الگوریتم میگوییم که بهتر است خروجی را به صورت شکل بالا (۰/۰۱ برای o1 و ۰/۹۹ برای o2) ایجاد کند و الگوریتم باید سعی کند که با آپدیت کردن وزنها در هنگام یادگیری، به این خروجی یا چیزی نزدیک به این خروجی برسد.
پس به صورت خلاصه در شبکهی عصبی، در هنگام آموزش، ورودی و خروجی مورد انتظار را از مجموعهی دادهی آموزشی میگیرد و وزنها را با توجه به نمونههای مختلفی که از مجموعهی دادهی آموزشی مشاهده کرده آپدیت میکند. این همان فرآیند یادگیری در شبکهی عصبی است. پس از یادگیری، الگوریتم میتواند نمونههای جدید را به یکی از طبقههای «خیر» یا «بلی» طبقهبندی کند.
حال اجازه دهید به صورت دقیقتر و با یک مثال به بررسی این فرآیندِ یادگیری بپردازیم. برای شروع، الگوریتم، وزنها را مانند شکل بالا به صورت تصادفی مقداردهی میکند. سپس یکی از مشتریان (سطرها) را از مجموعهی داده خوانده و با ضرب ورودیها در وزنها به همراه بایاس (bias) که یک عنصر کمکی است و سپس اعمال تابع فعالسازی (در اینجا تابع سیگوید)، مقادیر خروجی در نورونهای لایهی مخفی را ایجاد میکند. به این فاز که حرکت از ورودی به خروجی است، پیشخور یا همان feed forward میگویند. برای مثال، مقدارِ نورون h1 در معماری شبکهی عصبی بالا با ورودی مشتریِ شمارهی ۱ از مجموعهی دادهی آموزشی، به صورت زیر محاسبه میشود:
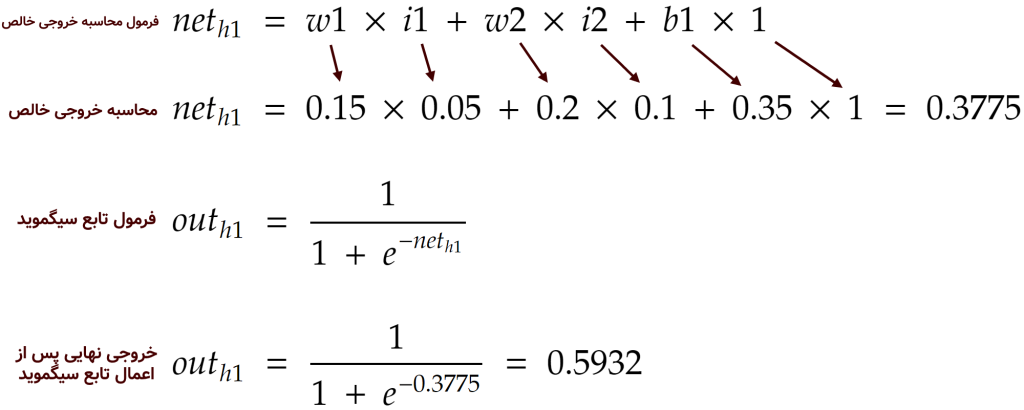
همین محاسبات برای نورون h2 در لایهی مخفی میتواند انجام شود و خروجی این نورون به صورت زیر درآید:
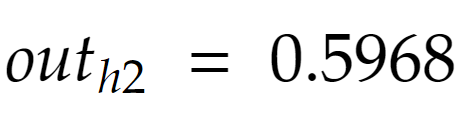
حال که مقادیرِ خروجی در نورونهای لایهی مخفی محاسبه شد، بایستی با استفاده از وزنهای لایهی پایانی (که به صورت تصادفی در ابتدا ساخته بودیم) به سراغ ایجاد مقادیر در نورونهای خروجی برویم. برای نورون o1 در لایهی خروجی، محاسبات به صورت زیر انجام میشود (تابع فعالسازی برای نورونها همان سیگموید است):
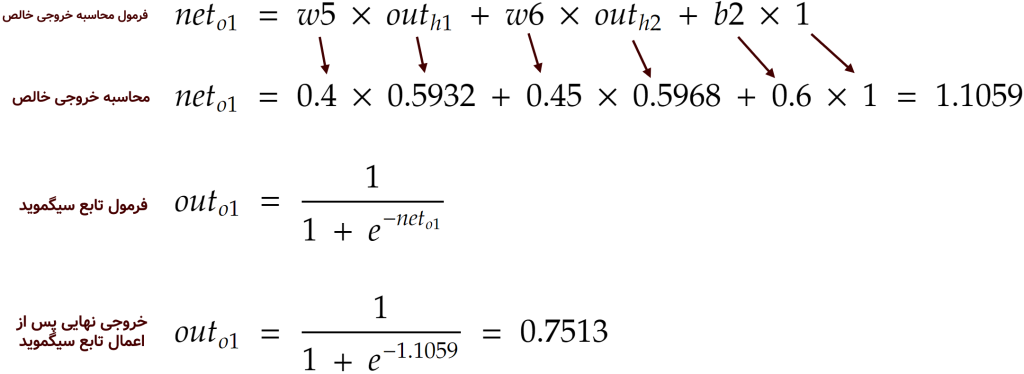
همین عملیات برای محاسبهی o2 نیز انجام میشود تا مقدار این نورون را نیز محاسبه کنیم:
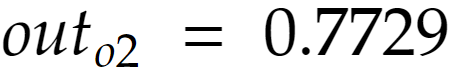
حال که مقادیر نورونهای خروجی محاسبه شد، نوبت به فاز دوم میرسد. به فاز دوم پسانتشار خطا یا همان back propagation of error میگویند. در فازِ پسانتشار خطا، بایستی ابتدا خطای الگوریتم را محاسبه کنیم. در اینجا یک تابعِ محاسبهی خطا به نام «جمع مربعات خطا» یا همان sum of squared error را انتخاب کرده، با استفاده از آن خطای الگوریتم را محاسبه میکنیم. فرمول محاسبهی خطا به در این تابع به صورت زیر است:
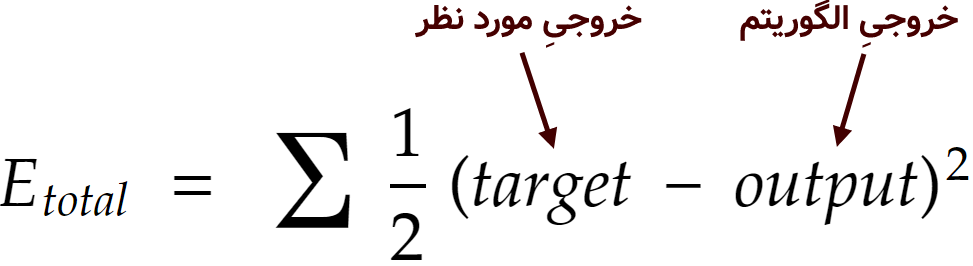
و در نتیجه خطا برای o1 و o2 و خطاهای کل به صورت زیر محاسبه میشود:

در اینجا جمع خطاهای o1 و o2 برابر ۰/۲۹ میشود. حال بایستی این خطا را به وزنها اعلام کنیم تا وزنها خود را با این خطا آپدیت کنند. هر چقدر خطا بیشتر باشد، وزنها بایستی بیشتر آپدیت شوند. آپدیت کردن وزنها در این مرحله با استفاده از قانون مشتق جزئی اجرا میشود. دلیل و کاربرد استفاده از مشتق را به صورت ساده در درس کاهش گرادیان در دورهی جاری فرا گرفتیم.
برای شروعِ این مرحله فرض کنید میخواهیم w5 را در معماری شبکهی عصبی بالا آپدیت کنیم. میخواهیم بدانیم که تغییرات در w5 چه مقدار تاثیر بر خطای نهایی (Etotal) دارند. در ریاضیات به این عمل «مشتق جزئیِ خطای نهایی با توجه به w5» گفته میشود. البته برای سادگی میتوانیم به آن «گرادیان با توجه به w5» نیز بگوییم که به صورت زیر فرمولبندی می شود:

در حسابان «قاعدهی زنجیرهای» یا همان «chain rule» رابطهای برای یافتن مشتقِ ترکیب دو تابع است (اگر متوجه نشدید فعلاً مهم نیست). از این قاعده، ما میتوانیم فرمول بالا را بسط دهیم:
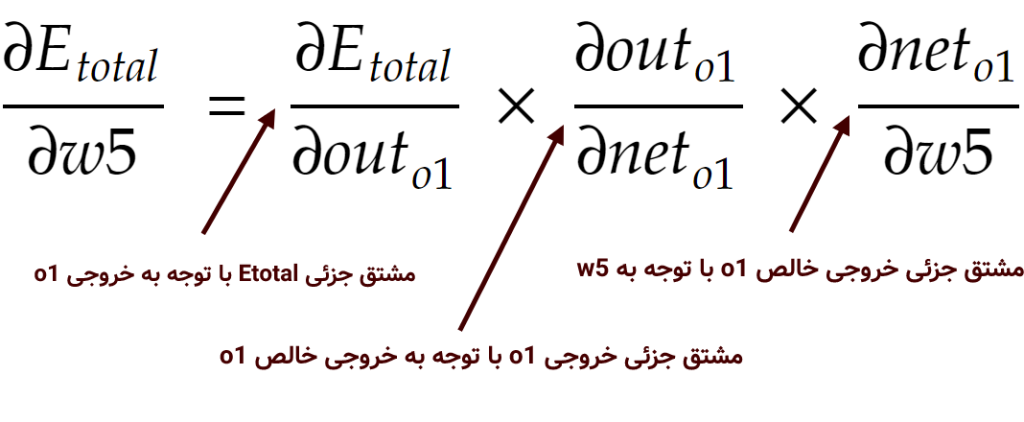
حال هر کدام از این سه قسمت بسط داده شده را محاسبه میکنیم (برای فهم فرمول زیر باید مشتقگیری را بلد باشید):
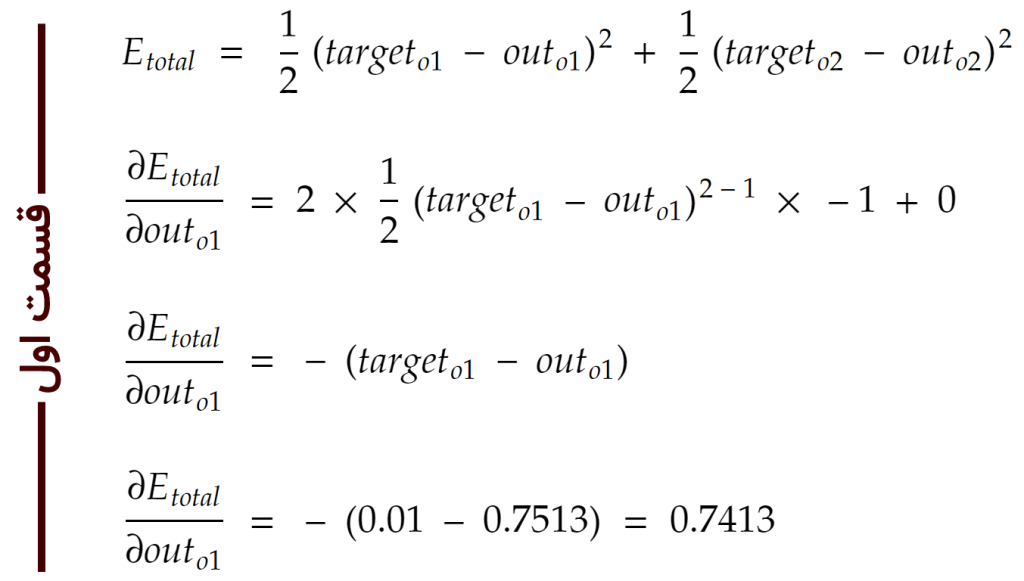
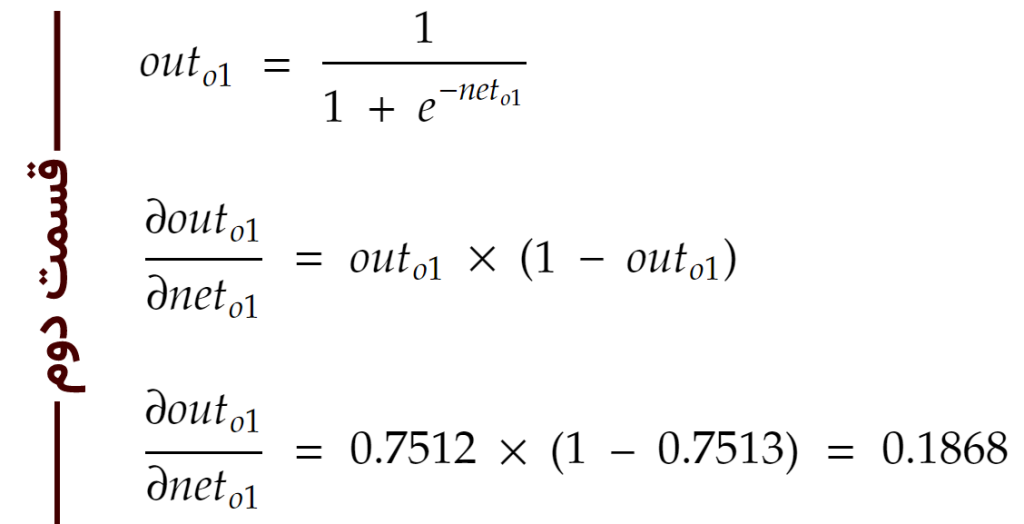
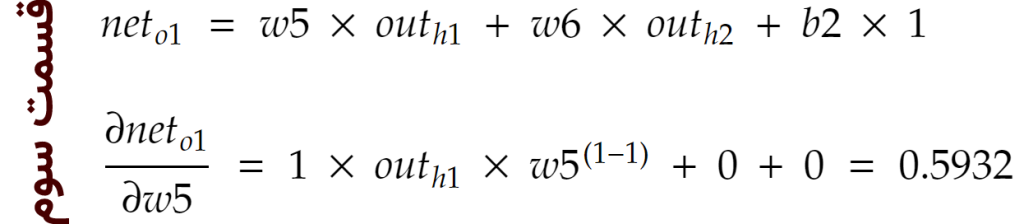
و در نهایت همه را با هم ضرب میکنیم تا به مقدارِ گرادیان مورد نظر با توجه به w5 برسیم:
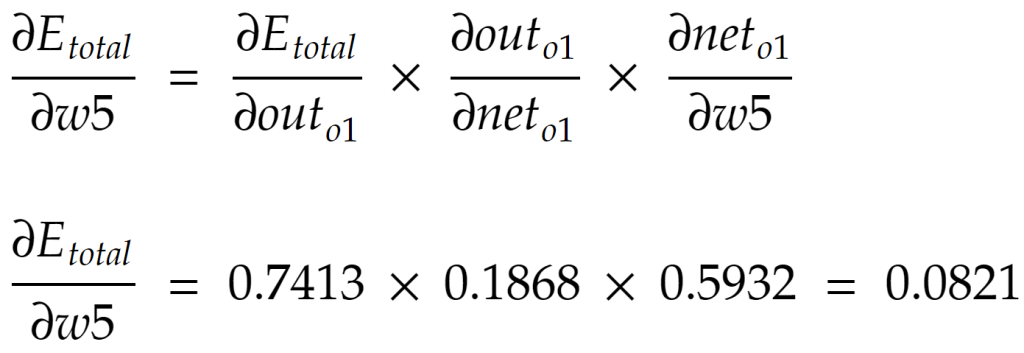
به این کارهایی که در بالا انجام دادیم در در اصطلاح «قانون دلتا» یا همان «delta rule» گفته میشود. مقداری که از قانون دلتا به دست آوردیم، مقداری است که بایستی از w5 کم کنیم تا w5 آپدیت شده به دست آید.

در اینجا آلفا یک مقدار ثابت است که معمولاً توسط کاربر به الگوریتم به عنوان پارامتر داده میشود که هر چقدر کمتر باشد، الگوریتم آرامتر یادگیری را انجام میدهد و به اصطلاح با حوصلهی بیشتری هر کدام از وزنها را آپدیت میکند.
تا به اینجای کار مشاهده کردیم که با استفاده از مشتق و قانون دلتا، وزن w5 را به مقداری مورد نظر آپدیت کردیم. به همین ترتیب بقیهی وزنها را نیز میتوانیم آپدیت کرده و به سراغ نمونهی بعدی (مشتری بعدی) در مجموعهی آموزشی برویم. هنگامی که تمامیِ مشتریان یکی یکی توسط الگوریتم مشاهده شدند، یک دور (epoch) از الگوریتم پایان میپذیرد. در دورهای بعدی دومرتبه تمامی مشتریان از اول تا انتها به الگوریتم تزریق شده و این کار به تعداد دور دلخواه ادامه پیدا میکند. معمولاً هر چقدر تعداد دورهای الگوریتم بیشتر باشد، دقت بالاتر رفته و یادگیری بهتر انجام میشود.
معماریهای مختلفی را میتوان برای شبکههای عصبی متصور بود. در مثال درسِ جاری، ما یک معماری ساده را طراحی کردیم که فقط یک لایهی مخفی داشت. میتوان تعداد لایههای مخفی و همچنین تعداد نورونهای موجود در این لایهها را کم و زیاد کرد و با این کار دقت الگوریتم را افزایش داد.
برای درک بهتر شبکههای عصبی در آدرس nnplayground.chistio.ir یک محیط آزمایشی ساده و کاربردی ساخته شده است که میتوانید از آن برای طراحی شبکههای عصبی و اجرای آن در مرورگر خود استفاده کنید.

- ۱ » شبکه عصبی (Neural Network) چیست؟
- ۲ » تعریف پرسپترون (Perceptron) در شبکه های عصبی
- ۳ » پرسپترون در شبکه عصبی چگونه یاد میگیرد؟
- ۴ » پرسپترون چند لایه (Multi Layer Perceptron) چیست؟
- ۵ » درباره توابع فعال سازی پرسپترون و Sigmoid
- ۶ » تابع ضرر (Loss Function) در شبکه عصبی چیست و چه کاربردی دارد؟
- ۷ » نحوه یادگیری پس انتشار خطا (Back Propagation) در شبکه های عصبی
- ۸ » کاهش گرادیان (Gradient Descent) در شبکه های عصبی
- ۹ » حل یک مثال عددی یادگیری ماشین با شبکههای عصبی
سلام کسی میتونه راجع به حل معادلات انتگرال با استفاده از شبکه عصبی بهم کمک کنه؟
اقای کاویانی از شما ممنونم بابت این مثال و درس عالی…مخصوصا بابت ابزار آزمایشی شبکه عصبی…خیلی به درک بهترم کمک کرد! خدا به علمتون برکت بده!
سلام
دوره مقدمات شبکه عصبی را کامل مطالعه کردم
خیلی روان و مفهومی توضیح داده بودید و واقعا استفاده کردم
ممنون از محتوای خوبتون
منتظر بخش پیشرفته و ادامه ان هستیم
خداقوت
متشکرم
با درود و ابراز قدردانی از بزرگواری شما جناب کاویانی، باشد که مشعل دانشتان همواره پرفروغ و هموارکننده ی شاهراه زندگی عزتمندتان باشد.
خدا خیرتون بده، کل اینترنت رو زیرو رو کردم هرچی جزوه بود خوندم هیچی نفهمیدم تا این سایتو پیدا کردم. مرسی از توضیح روان و جامعتون و مخصوصا این مثال عددی آخر.
عالی