

روشهای متعددی برای مقایسهی دو مجموعهی داده با یکدیگر است. مثلاً میتوان میانگین آنها را با یکدیگر مقایسه کرد و یا پراکندگی (واریانس) آنها را مورد مقایسه قرار داد. اما هر کدام از این مقایسهها قسمتی از حقیقت را پنهان میکنند. به همین دلیل معیارهایی با نام فاصلهی آماری به وجود آمده است که با استفاده از آنها بتوان مجموعه دادههای مختلف و یا متغیرهای متفاوت را با یکدیگر مقایسه کرد.
فرض کنید دو گروه ورزشکار داریم. یک گروه شناگران و گروه دوم بازیکنان واترپلو هستند. میخواهیم وزن هر یک از ورزشکاران را محاسبه کرده و ببینیم که آیا وزن ورزشکاران گروه شناگر با وزن ورزشکاران واترپلو تفاوت دارد یا خیر؟ برای این کار میتوانیم میانگین وزن شناگران را از میانگین وزن بازیکنان واترپلو کم کرده و اختلاف آنها را به دست بیاوریم. ولی این روش به خوبی نمیتواند فاصلهی دو مجموعه را نشان دهند. زیرا در این روش ما فقط به یک معیار (میانگین) بسنده کردهایم و از معیارهای دیگر مانند پراکندگی، چولگی و… صرف نظر کردهایم. برای همین بهتر است برای مقایسهی این دو مجموعه از معیارهای فاصلهی آماری استفاده کرد.
برای محاسبهی فاصلهی آماری نیاز به توزیعِ آماریِ هر مجموعه داریم. در درس قبل در مورد توزیع آماری و نحوهی ساخت آن صحبت کردیم. حال فرض کنید وزنِ ورزشکارانِ مثال بالا که در دو گروه قرار داشتند را به صورت توزیع آماری نمایش دهیم. چیزی مانند شکل زیر:
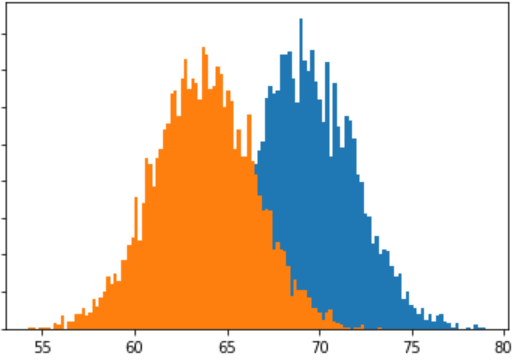
در شکل بالا، توزیعِ آبی رنگ، توزیعِ وزنِ ورزشکاران واترپلو را نمایش میدهد و توزیعِ نارنجی، توزیع وزنِ ورزشکاران شناگر را. این توزیع به صورت احتمالی رسم شده است، یعنی فرکانسِ هر قسمت را تقسیم بر تعداد کل بازیکنان هر گروه کردهایم. برای مثال اگر تعداد بازیکنان شناگر در بین وزن ۶۰ تا ۶۱ کیلو ۹ نفر باشد و تعداد کل بازیکنان شناگر ۵۰۰ نفر، مقداری که بر روی محور عمودی (فرکانس) برای بازهی ۶۰ تا ۶۱ مشخص میشود برابر ۹/۵۰۰ (۹ تقسیم بر ۵۰۰) یعنی ۰/۰۱۸ خواهد بود.
همانطور که گفتیم معیارهای فاصلهی آماری یا همان statistical distance، معیارهایی هستند که میتوانند میزان فاصله بین دو توزیع آماری را مشخص نمایند. برای مثال تعیین شباهت یا تفاوت بین دو توزیعِ مشخص شده در شکل بالا میتواند توسط معیارهای فاصلهی آماری صورت پذیرد.
اگر بخواهیم چند معیار برای فاصلهی آماری نام ببریم میتوانیم به
«واگرایی کولبک-لیبلر (Kullback-Leibler divergence)»
«فاصلهی هلینگر (Hellinger distance)»
«واگرایی جنسن-شنون (Jensen-Shannon divergence)»
«فاصلهی بهاتاچاریا (Bhattacharyya distance)»
«فاصلهی کولموگوروف-اسمیرنوف (Kolmogorov-Smirnov)»
و «فاصلهی ماهالانوبیس (Mahalanobis distance)»
اشاره کرد.
هر کدام از معیارهای گفته شده در بالا با استفاده از فرمول مخصوص به خود میتوانند فاصله یا شباهت بین دو توزیع آماری را محاسبه کنند. در دروس آینده با برخی از این معیارها و جزئیات بیشتر آنها آشنا خواهیم شد.

- ۱ » تحلیل اکتشافی دادهها (Exploratory Data Analysis) چیست؟
- ۲ » انواع مختلف دادهها در دادهکاوی کدامند؟
- ۳ » منظور از دادههای مستطیلی (Rectangular Data) چیست؟
- ۴ » داده پرت (Outlier) در دادهکاوی چیست؟
- ۵ » تخمین مکان دادهها (Estimation Of Location) چیست و انواع مختلف آن کدامند؟
- ۶ » تخمین تنوع و پراکندگی (Estimation Of Variability) و انواع مختلف آن
- ۷ » چارک (Quartile) و IQR در دادهها و کاربردهای آن
- ۸ » چولگی (Skewness) در دادهها
- ۹ » کشیدگی یا برجستگی (kurtosis) در دادهها
- ۱۰ » چگونه با EDA در دادهها اکتشاف کنیم؟
- ۱۱ » نمونهگیری آماری و محاسبهی حداقل تعداد نمونه (Min Sample Size)
- ۱۲ » توزیعهای آماری (Statistical Distributions)
- ۱۳ » فاصلهی آماری (Statistical Distance) و کاربردهای آن
- ۱۴ » واگرایی کولبک-لیبلر (Kullback-Leibler Divergence) و کاربرد آن در فاصلهی آماری
- ۱۵ » فاصلهی جنسون-شنون (Jenson-Shannon) برای مقایسهی توزیعهای آماری