

تا اینجا در بحث آنالیز اکتشافی دادهها که با هم قرار گذاشتیم دادهها را خلاصه کنیم به این نتیجه رسیدیم که یک سری داده پرت داریم و یک سری تعریف برای اینکه بتوانیم تخمین بزنیم که مکان حدودی دادهها کجا هستند. برای مثال میانگین یک تخمینی است که میتواند بگوید دادهها حدوداً در کجا قرار دارند. ولی نکته اصلی دیگری که میتوان گفت این است که این دادهها با چه تنوعی پراکنده شدهاند و در واقع پراکندگی دادهها به چه صورت بوده است. برای مثال احتمالا پراکندگی سن افراد در یک سینما خیلی بیشتر از یک کلاس درس است (البته اگر معلم را کنار بگذاریم!).
برای تعریف پراکندگی دادهها (یا مجموعهای از یک سری دادهها) تعاریف و معیارهای مختلفی موجود است که هر کدام کاربرد خاص خود را دارند. احتمالا اگر به صورت کاربردی یا حتی تئوری علوم داده را خوانده باشید در چند جا به انواع معیارهای پراکندگی برخوردهاید. اجازه بدهید چند مورد از مهمترین معیارهای پراکندگی را با هم مرور کنیم. قبل از آن حتما درس قبل را در مورد تخمین مکان (Estimation Of Location) خوانده باشید.
دادههای زیر را فرض کنید:
۱، ۲، ۵، ۵، ۷
میانگین این دادهها برابر ۴ است. یعنی فرض کنید تخمین مکان را برای این دادهها معیار میانگین در نظر گرفتهایم. حال اگر بخواهیم انحراف یا همان Deviation را تعریف کنیم مانند شکل زیر است:
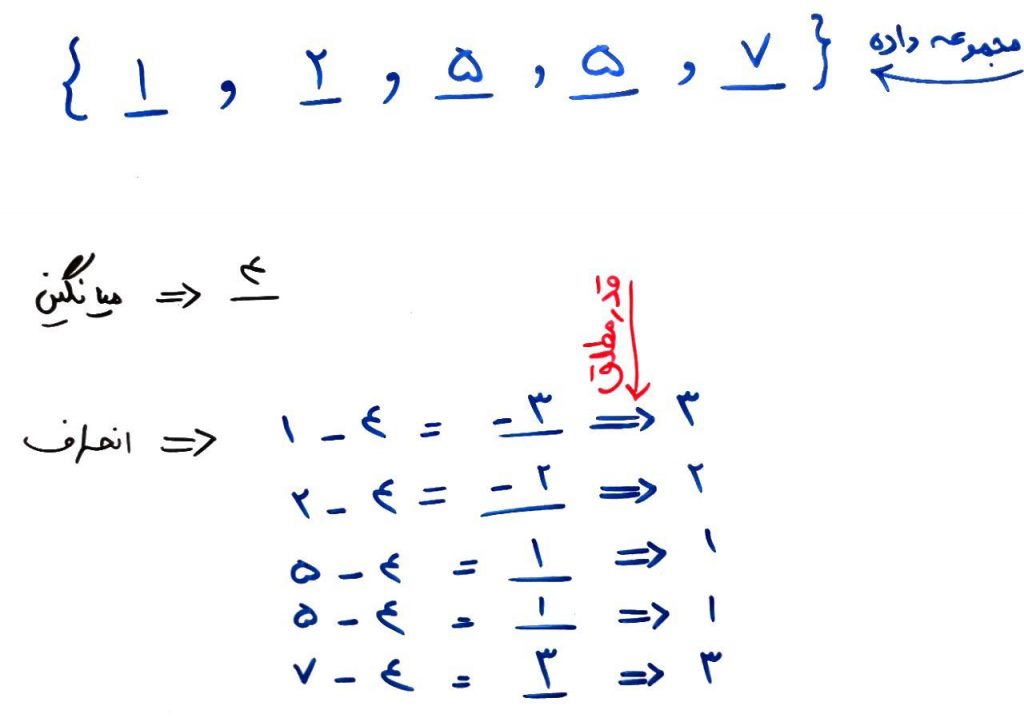
در واقع اختلاف هر کدام از اعداد نسبت به میانگین را اینجا انحراف یا همان Deviation در نظر گرفتهایم. البته برای انحراف میتوانیم مقدار قدر مطلق یا همان Absolute را در نظر گرفتهایم. یعنی مقدار منفیها را قدر مطلق گرفته و مثبت کردهایم. حال اگر میانگین این انحرافات را به دست بیاوریم یک معیار استاندارد را حساب کردهایم. این معیار همان میانگین قدر مطلق انحراف یا انحراف مطلق میانگین یا Mean Absolute Deviation است. شکل زیر را نگاه کنید:
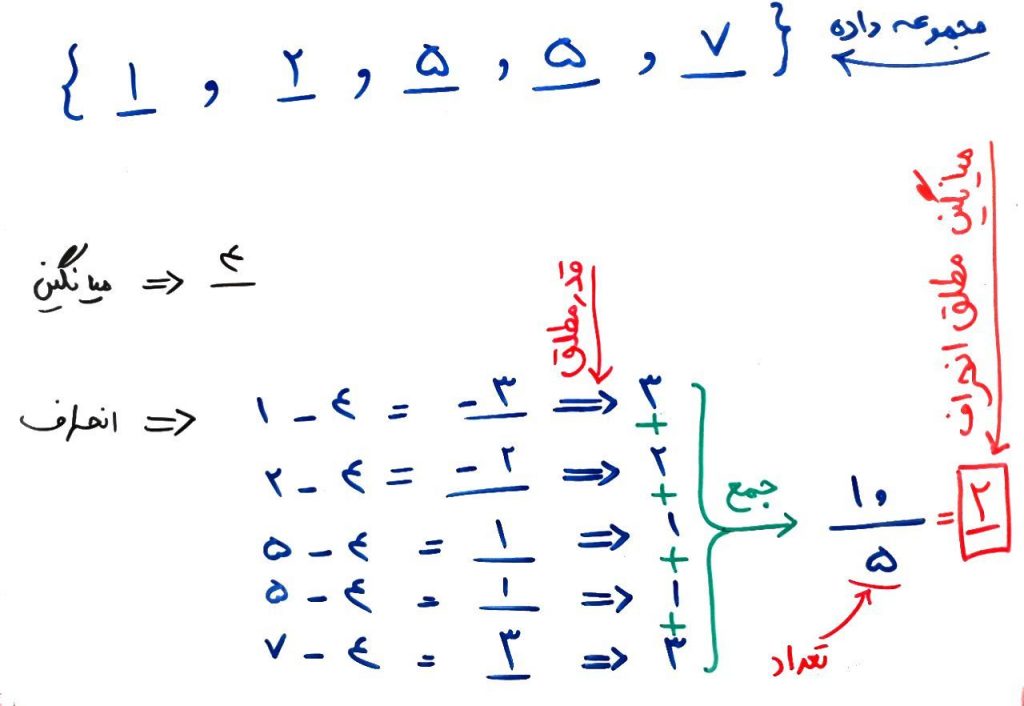
البته که Mean Absolute Deviation تنها معیار برای تخمین پراکندگی نیست. معروفترین معیار در این حوزه شاید همان واریانس Variance باشد. شکل زیر واریانس را برای اعداد بالا محاسبه کردهاست:
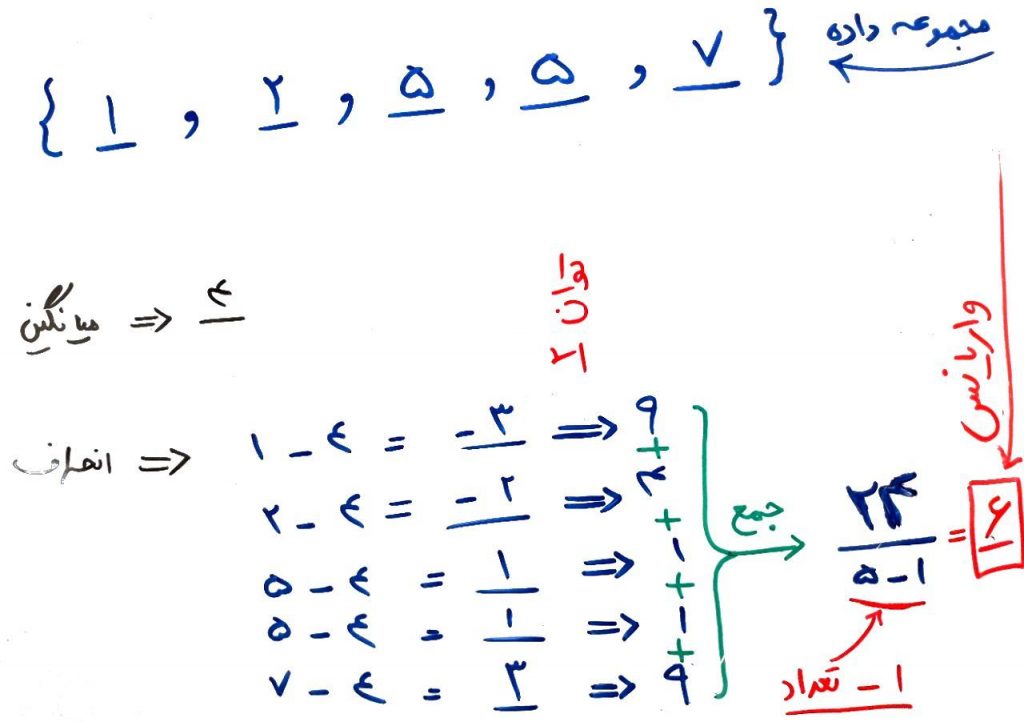
اگر از واریانس رادیکال بگیرید، معیار دیگری به اسم انحراف استاندارد یا همان Standard Deviation به دست میآید که عددی که از انحراف استاندارد به دست میآید نسبت به واریانس گویاتر است. زیرا واریانس هر کدام از اختلافات را به توان ۲ رسانده است. در واقع مثلا وقتی میگوییم انحراف استاندارد برابر ۲.۴ است یعنی هر کدام از اعداد تقریبا به اندازه ۲.۴واحد (به طور میانگین) از معیار میانگین مجموعه اعداد فاصله دارند. ولی وقتی بگوییم واریانس برابر ۶است، چیزی دستگیرمان نمیشود. (در واقع معیار انحراف استاندارد قابل تفسیرتر است) فقط میتوانیم واریانس دو مجموعهی مختلف را با هم مقایسه کنیم. یعنی اگر یک مجموعهای واریانس بیشتری نسبت به یک مجموعهی دیگر داشت، میتوانیم بفهمیم که این مجموعه پراکندگی بیشتری دارد.
درس دادههای پرت را که یادتان هست. دو معیاری که تا به حال گفتیم (واریانس و انحراف استاندارد) نسبت به دادههای پرت حساس هستند به این معنی که دادههای پرت میتوانند بر روی آنها تاثیر زیادی بگذارند.
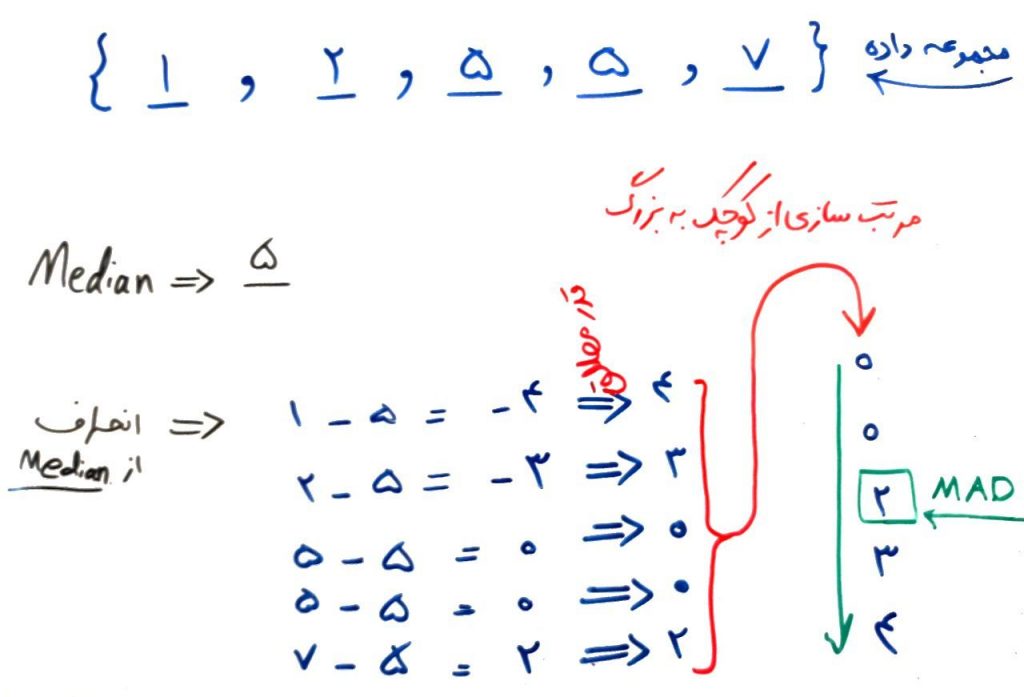
از درس قبل Median را به یاد بیاورید. گفتیم Median یکی از معیارهای تخمین مکان بود که نسبت به دادههای پرت قدرتمند (Robust) بود. یعنی دادههای پرت نمیتوانستند تاثیر زیادی بر روی محاسبه Median بگذارند. حال از روی همین Median به معیاری میرسیم که به آن Median Absolute Deviation میگویند. اگر Median برای دادههای بالا ۵ باشد، این معیار مانند شکل زیر محاسبه میشود:
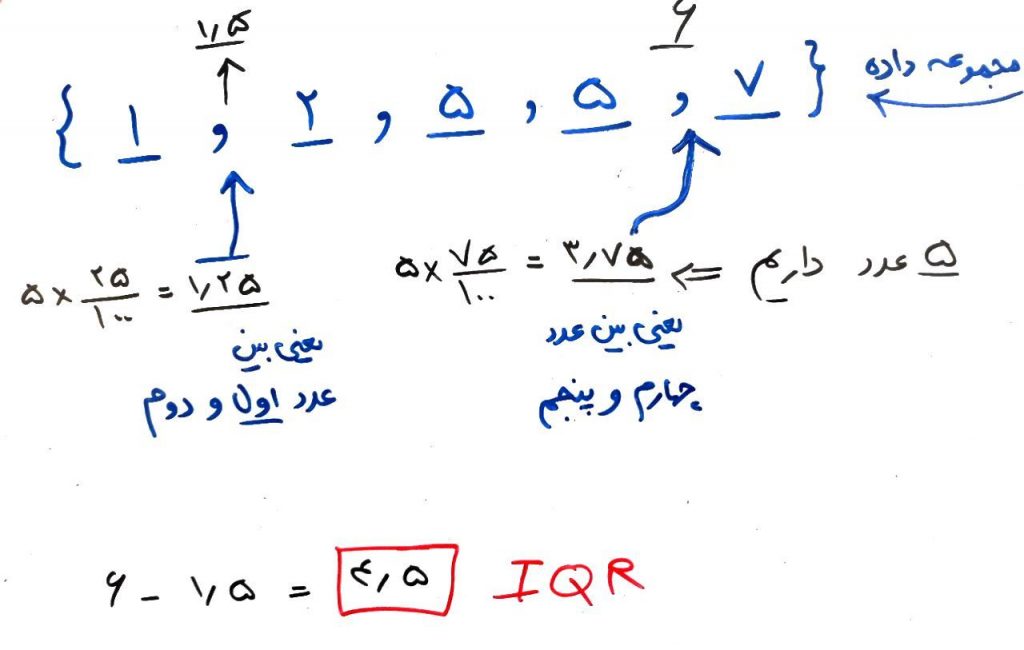
تا اینجا معیارهای معروفی را گفتیم، اما معیارهای دیگری در میان تخمینهای پراکندگی وجود دارد. یک معیار دیگر، معیار بازه یا Range است. معیار سادهای که در آن کافیست اختلاف کمترین و بیشترین مقدار را در یک مجموعه داده محاسبه کنید. برای مثال در دادههای بالا اختلاف کمترین و بیشترر عدد (۱ – ۷) برابر است با ۶. یعنی معیار Range برای این دادهها برابر ۶ است. اما معیار Range بسیار حساس به دادههای پرت است. برای همین یک معیار بهتر به نام IQR که مخفف InterQuartile Range است معرفی شده است. در این معیار، بازهای بین ۲۵درصد تا ۷۵درصد دادهها را محاسبه میکنیم. سپس اختلاف بیشتر مقدار باقیمانده و کمترین مقدار باقیمانده را گرفته تا IQR برای دادهها محاسبه شود. این معیار نسبت به دادههای پرت مقاومت بیشتری دارد. شکل زیر IQR را برای دادههای بالا محاسبه کرده است:
طبیعتا معیارها و سنجههای مختلف دیگری را هم میتوان برای پراکندگی دادهها محاسبه کرد که با کمی فکر کردن میتوانید معیاری که برای دادهها و نوع دادههای شما مناسب باشد را پیدا کنید.

- ۱ » تحلیل اکتشافی دادهها (Exploratory Data Analysis) چیست؟
- ۲ » انواع مختلف دادهها در دادهکاوی کدامند؟
- ۳ » منظور از دادههای مستطیلی (Rectangular Data) چیست؟
- ۴ » داده پرت (Outlier) در دادهکاوی چیست؟
- ۵ » تخمین مکان دادهها (Estimation Of Location) چیست و انواع مختلف آن کدامند؟
- ۶ » تخمین تنوع و پراکندگی (Estimation Of Variability) و انواع مختلف آن
- ۷ » چارک (Quartile) و IQR در دادهها و کاربردهای آن
- ۸ » چولگی (Skewness) در دادهها
- ۹ » کشیدگی یا برجستگی (kurtosis) در دادهها
- ۱۰ » چگونه با EDA در دادهها اکتشاف کنیم؟
- ۱۱ » نمونهگیری آماری و محاسبهی حداقل تعداد نمونه (Min Sample Size)
- ۱۲ » توزیعهای آماری (Statistical Distributions)
- ۱۳ » فاصلهی آماری (Statistical Distance) و کاربردهای آن
- ۱۴ » واگرایی کولبک-لیبلر (Kullback-Leibler Divergence) و کاربرد آن در فاصلهی آماری
- ۱۵ » فاصلهی جنسون-شنون (Jenson-Shannon) برای مقایسهی توزیعهای آماری
با سلام.
بابت مطالب خوبی که به زبان ساده و قابل فهم در اختیار جامعه علوم داده کشور قرار می دهید بسیار سپاسگزارم.
عالی
بسیار سپاسگذارم
بنده هم به سهم خودم از مطالبتون تشكر ميكنم. كلي ابعاماتم رفع شد
اینقدر شیوا می نویسید که آدم از خواندن مطالب لذت می برد
سلام
شما در يك كلام عجيب و غريب خوبيد ، واقعا خوبيد ، لطفا بمونيد برامون ، و اينكه جايي راهنمايي كرديد كه براي شروع دوره علم داده چه مطالبي رو بايد ياد بگيريم ؟
ممنون واقعا
استاد ارجمند از دقت نظر ششما و ارايه مطالب به زبان قابل فهم سپاسگزارم