

مثالی که در درس قبل آوردیم را به خاطر بیاورید. اگر یک نفر از شما بخواهد بپرسد که میانگین سن افراد ورودی به دانشگاه شما چه سنی است احتمالا خیلی سریع پاسخ میدهید ۱۸سال. ولی اگر یک نفر از شما بپرسد که میانگین حدودی سن خانواده درجه ۱شما چند سال است قطعا جواب نه راحت خواهد بود و نه دقیق. زیرا برای مثال پدر شما ۵۰سال دارد و خود شما ۲۳سال و برادر کوچکتر شما ۱۵سال دارد. به این ترتیب اختلاف سنی در خانواده شما بسیار بیشتر از ورودیهای یک دانشگاه خاص است. اینجاست که مبحث تخمین مکان دادهها یا همان Estimation Of Location معنا پیدا میکند تا یک متخصص علوم داده یا مهندس آمار بتواند یک تخمین درست و ساده از دادهها داشته باشد. همانطور که در درس اول این دوره گفتیم، کار اصلی آنالیز اکتشافی دادهها (EDA) ساده سازی مقادیر زیاد داده است.
اجازه بدهید به معیارهایی که برای سنجش موقعیت یا همان Location و تخمین آن بپردازیم. بسیاری از این موارد را قبلا در دروسی مانند ریاضیات یا آمار و احتمالات خواندهاید ولی تکرار آنهای میتواند به یادگیری کمک کند:
۱. میانگین (Mean): فکر نمیکنم نیاز به توضیح داشته باشد. برای مثال میانگین سن افراد ورودی یک سال در یک دانشگاه حدودا ۱۸سال است. جمع تمامی سنین و تقسیم آن به تعداد افراد میانگین سن افراد را به ما میدهد. اگر درس دادههای پرت را خوانده باشید متوجه میشوید که میانگین، نسبت به دادههای پرت انحراف دارد به این معنی که یک داده پرت (مثلا یک سن خیلی زیاد-مثلا ۶۰ سال- در میان ورودیهای یک دانشگاه) میتواند میانگین را به سمت این سن بالا جا به جا کند. پس به اصطلاح گفته میشود که میانگین یک واحد قوی برای محاسبه تخمین مکان دادهها نیست.
۲. میانگین وزن دار (Weighted Mean): اگر هر کدام از دادههای ما یک وزن مشخص داشته باشند و بخواهیم میانگین آنها را حساب کنیم ابتدا باید این دادهها را در وزن آنها ضرب کنیم. سپس با هم جمع کرده و تقسیم بر تعداد کنیم. این کار را در کارنامه یک ترم دانشگاهی خود حتما دیدهاید. مثلا درس تربیت بدنی ضریب ۲دارید و درس آمار و احتمالات ضریب ۳ و به همین ترتیب بقیه دروس هر کدام ضریب خود را دارند. حالا وقتی میخواهند معدل یک ترم شما را حساب کنند، هر کدام از دروس را در ضریب (یا همان وزن آن) ضرب میکنند و سپس این مقادیر را با هم جمع کرده و تقسیم بر تعداد ضرایب میکنند تا معدل ترم شما حساب شود.
۳. مُد (Mode): مقداری که بیشترین تکرار را در میان دادهها دارد. برای مثال فرض کنید سن افراد حاضر در یک کلاس به صورت زیر است:
۱۸, ۱۹, ۱۸, ۱۸, ۲۰, ۶۰, ۲۱, ۲۰, ۱۸, ۱۹
همان طور که میبینید بیشترین تکرار را عدد ۱۸با ۴بار تکرار داشته است. پس مُد برای این دادهها عدد ۱۸ است.
۴. میانه (Median): ابتدا دادههایی را که دارید به ترتیب مرتب کنید. سپس مقدار وسطی (که نصف دادهها از آن بیشتر باشند و نصف دادهها از آن کمتر باشند) را انتخاب کنید. این مقدار همان مقدار Median است. اگر تعداد دادهها زوج بود، برای محاسبه Median بایستی میانگین دو عدد وسط را حساب کنید. برای مثال اعداد بالا را برای سن افراد حاضر در کلاس به ترتیب چینش میکنیم:
۱۸, ۱۸, ۱۸, ۱۸, ۱۹, ۱۹, ۲۰, ۲۰, ۲۱, ۶۰
مقدار Median برای دادههای فوق برابر ۱۹است. با توجه به درس دادههای پرت احتمالا متوجه شدهاید که مقدار Median از مقدار میانگین قویتر عمل میکند. یعنی سن ۶۰سال در مثال بالا تقریبا در میان دادهها برای مقدار Median حساب نشده است در حالیکه این مقدار (۶۰سال) میانگین را به نفع خود خیلی جا به جا میکرد. البته میانه وزندار هم داریم که خودتان میتوانید نحوه محاسبه آن را مانند میانگین وزندار به دست آورید.
۵. میانگین برشخورده (Trimmed Mean): دادهها را به ترتیب بچینید. nدرصد از بالای دادهها و nدرصد از پایین دادهها را بردارید (برش دهید). حال میانگین مقادیر باقی مانده را بگیرید. به این کار به اصلاح Trimmed Mean میگویند. شکل زیر را ببینید:
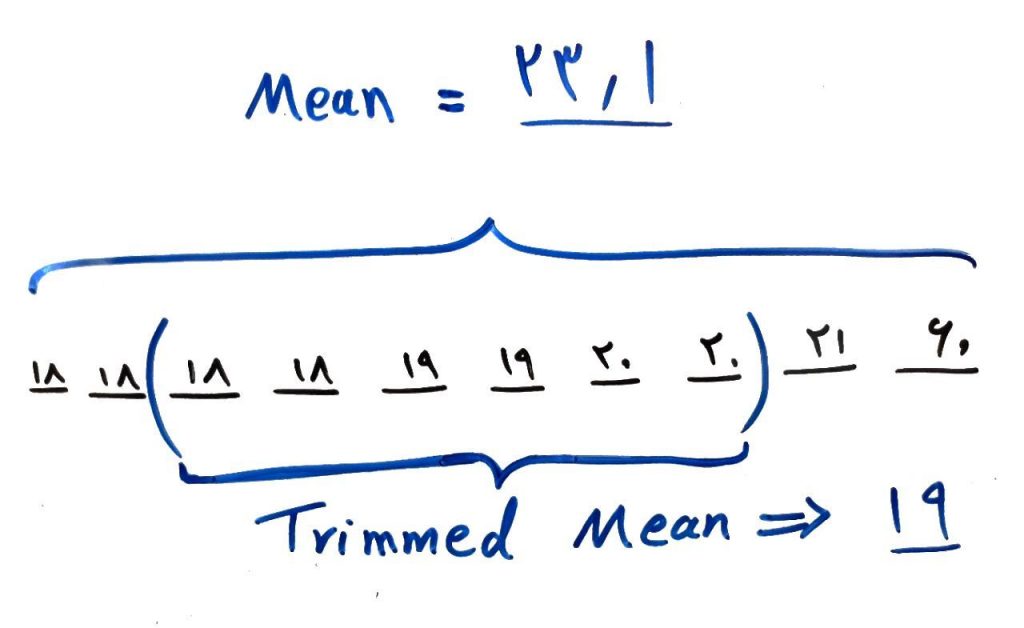
همانطور که میبینید از میاندادههای بالا، ۲تا از بالا و ۲تا از پایین را برش دادیم. حالا میانگین را گرفتیم. این کار باعث شد که میانگین نسبت به دادههای پرت قدرتمند (Robust) باشد. یعنی دیگر مقادیر پرتی مانند سن ۶۰سال نمیتوانند میانگین را خیلی خراب کنند.
۶. میانه-میانگین (Mid-Mean): مانند میانگین برشخورده (Trimmed Mean) است با این تفاوت که ۲۵درصد از بالای دادهها و ۲۵درصد از پایین دادهها را برمیداریم و از میان دادههای باقی ماننده در بین این دو (۲۵ تا ۷۵درصد) میانگین را محاسبه میکنیم. با این کار باز هم میانگین محاسبه شده نسبت به دادههای پرت قوی (Robust) است.
۷. میانگین Winsorized: این میانگین هم مانند میانگین برش خورده (Trimmed Mean) است با این تفاوت که دادههایی که از بالا و پایین قرار است حذف شوند، حذف نمیشوند. این دادهها تبدیل به بیشتر و کمتر مقدار باقی مانده شده و در محاسبه میانگین حساب میشوند. شکل زیر را نگاه کنید:
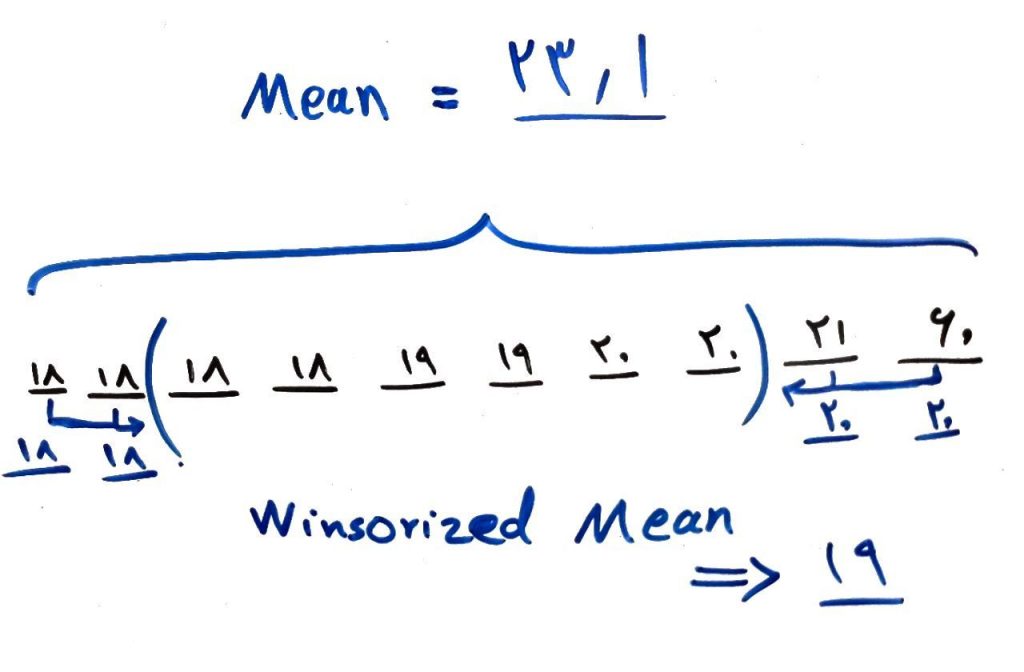
در این شکل ما۶۰ و ۲۱ را به جای اینکه حذف کنیم، به عدد ۲۰تبدیل کردیم و دو ۱۸پایین را به جای حذف کردن به عدد کوچکتر باقی مانده یعنی ۱۸ (سومین ۱۸) تبدیل کردیم. حالا میانگین همه اعداد را محاسبه کردیم. این میانگین علاوه بر اینکه به نسبت به دادههای پرت قوی است این دادهها را حذف نکرده و به نوعی در میانگین گیری تاثیر میدهد.
۸. میانه بازه (Mid-Range): کوچکترین مقدار و بزرگترین مقدار را با هم جمع و سپس تقسیم بر ۲ میکنیم. این میانگین شدیدا به دادههای پرت دار حساس و در واقع قدرت کمی نسبت به دادههای پرت دارد.

- ۱ » تحلیل اکتشافی دادهها (Exploratory Data Analysis) چیست؟
- ۲ » انواع مختلف دادهها در دادهکاوی کدامند؟
- ۳ » منظور از دادههای مستطیلی (Rectangular Data) چیست؟
- ۴ » داده پرت (Outlier) در دادهکاوی چیست؟
- ۵ » تخمین مکان دادهها (Estimation Of Location) چیست و انواع مختلف آن کدامند؟
- ۶ » تخمین تنوع و پراکندگی (Estimation Of Variability) و انواع مختلف آن
- ۷ » چارک (Quartile) و IQR در دادهها و کاربردهای آن
- ۸ » چولگی (Skewness) در دادهها
- ۹ » کشیدگی یا برجستگی (kurtosis) در دادهها
- ۱۰ » چگونه با EDA در دادهها اکتشاف کنیم؟
- ۱۱ » نمونهگیری آماری و محاسبهی حداقل تعداد نمونه (Min Sample Size)
- ۱۲ » توزیعهای آماری (Statistical Distributions)
- ۱۳ » فاصلهی آماری (Statistical Distance) و کاربردهای آن
- ۱۴ » واگرایی کولبک-لیبلر (Kullback-Leibler Divergence) و کاربرد آن در فاصلهی آماری
- ۱۵ » فاصلهی جنسون-شنون (Jenson-Shannon) برای مقایسهی توزیعهای آماری
پس بهترین راه برای اینکه داده های پرت تاثیر در میانگینمون نذاره کدوم راهه ؟ فک کنم میانگین برش خورده و یا میانه میانگین
بهترین راه بستگی به مسئله داره، ولی میانگین برش خورده یکی از راههای سرراست و خوبه
ممکنه محاسبه میانه وزندار رو هم توضیح بدید؟ با تشکر از مطال مفید و مرتبتون.
سلام تشکر بابت سایت خوبتون پیشنهاد میکنم مطالب رو غنی تر و بیشتر کنید.
اگه کمک خواستی بگو
خیلی عالی
ممنون