

در دروس قبلی در مورد شبکههای عصبی بازگشی RNN صحبت کردیم. این شبکهها کاربردی هستند و البته مشکلاتی نیز دارند. یکی از مشکلات RNNها، محوشدگی گرادیان در هنگام یادگیری از توالیهای بلند مدت است که توانایی یادگیری را در الگوریتم کاهش میکند.
شکل زیر را از دروس گذشته به یاد بیاورید:
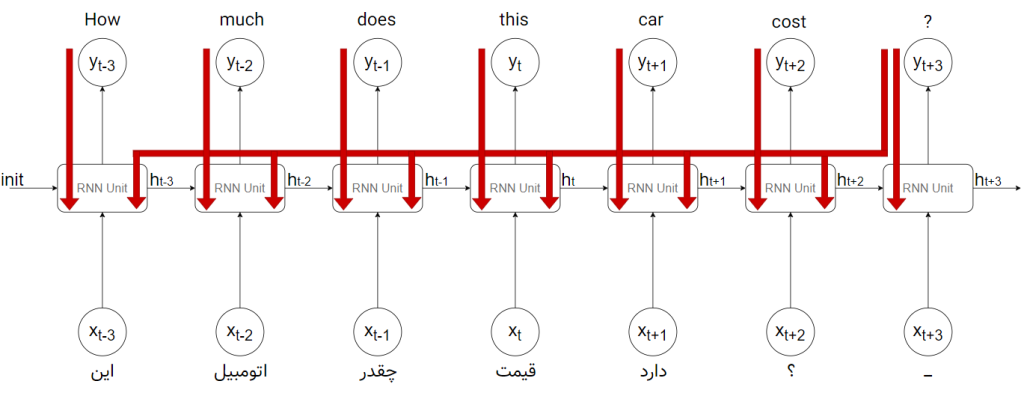
این محوشدگی در هنگام بالا رفتن تعداد توالیهای شبکههای عصبی بازگشتی نیز رخ میدهد. چیزی شبیه به شکل زیر:

در واقع شبکههای عصبی بازگشتی (RNN) ساده نمیتوانند توالیهای بلند مدت را یاد بگیرند و این مشکل باعث شد که شبکههای عصبی بازگشتی با حافظهی بلندِ کوتاه-مدت (long short-term memory) یا به اختصار LSTM ایجاد شوند.
شبکههای LSTM در واقع نوعی از RNNها هستند که تغییری در بلوک (RNN Unit) آنها ایجاد شده است. این تغییر باعث میشود که شبکههای عصبی بازگشتیِ LSTM بتوانند مدیریت حافظهی بلند مدت را داشته باشند و مشکل محوشدگی یا انفجار گرادیان را نیز نداشته باشند.
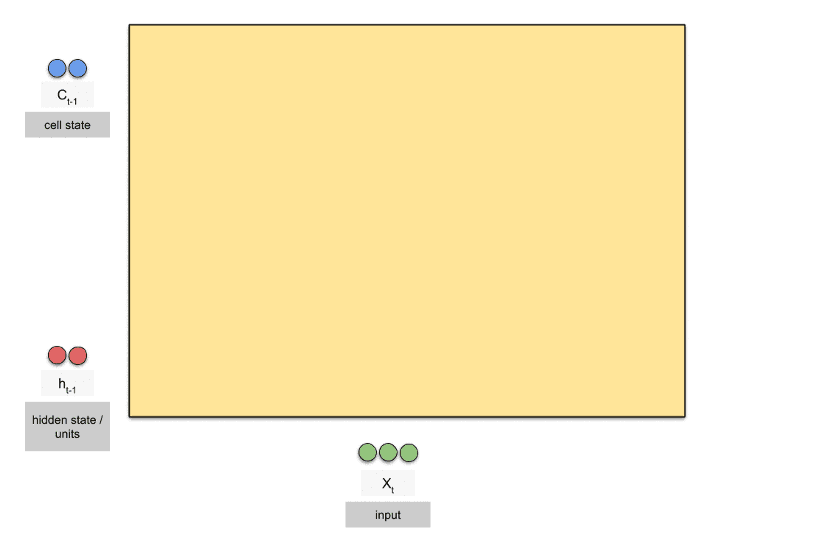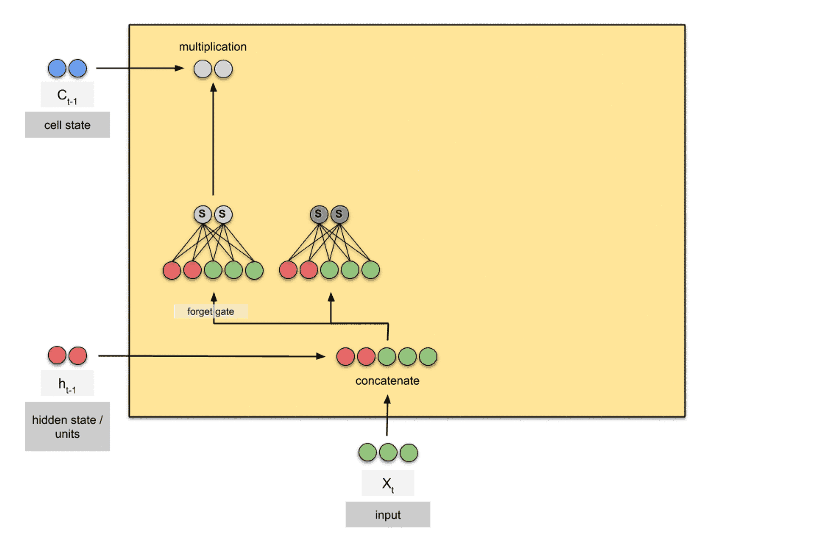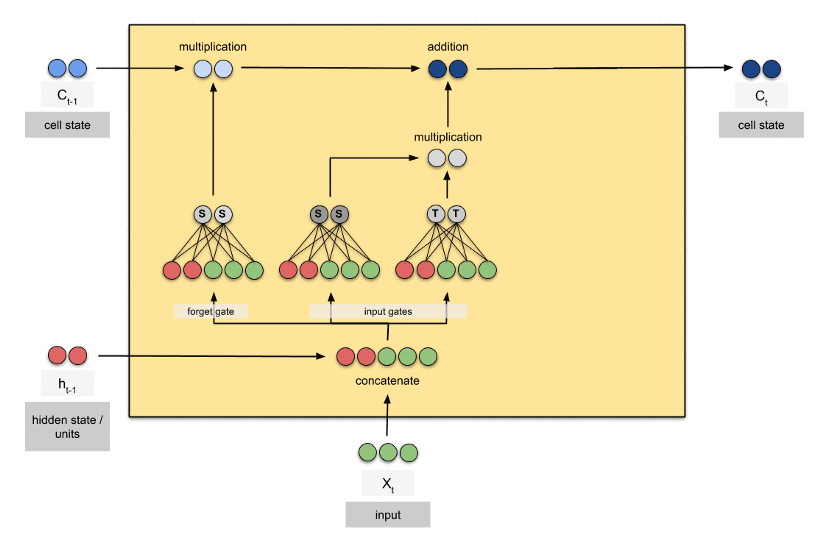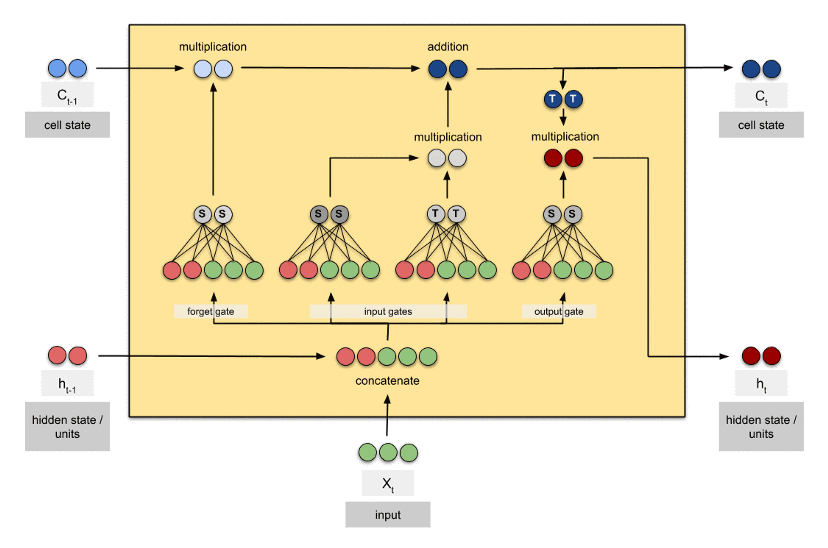
داخل یک بلوک LSTM به صورتِ زیر نسبت به بلوک RNN ساده تغییر کرده است:
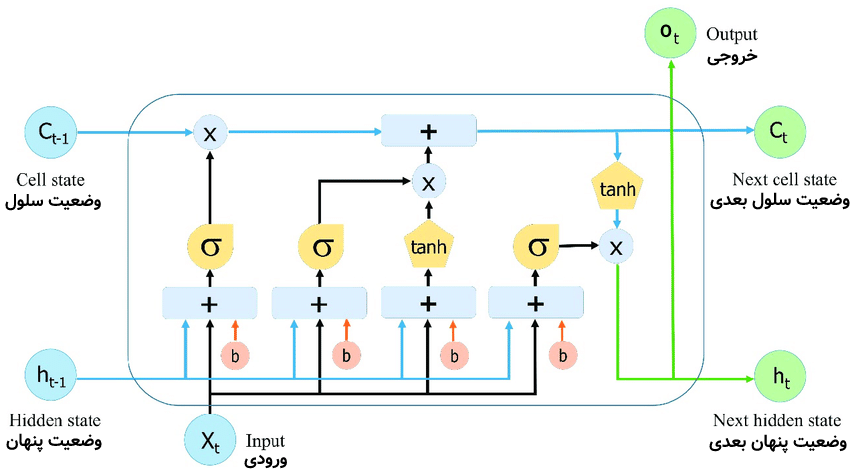
در شکل بالا مشاهده میشود که بر خلاف RNN ساده که دو ورودی (x و h) داشت، در اینجا سه ورودی (x و h و c) داریم. x همان ورودی در زمان (توالی) t است و h نیز مانند RNN ساده همان «وضعیت پنهان» بوده که از خروجیِ زمان قبلی (توالی قبلی) به عنوان حافظه دریافت میکند. ورودی c یک «وضعیت سلول» است که تنظیم میکند که چه مقدار اطلاعات از توالیهای بلندِ گذشته و کدام یک از آنها در بلوک تاثیر داشته باشند.
برای درکِ بهتر، یک بلوک LSTM را میتوان به سه بخش اصلی تقسیم نمود و هر کدام را جدا بررسی کرد. ابتدا بخش اول این بلوک که به شکل زیر است:
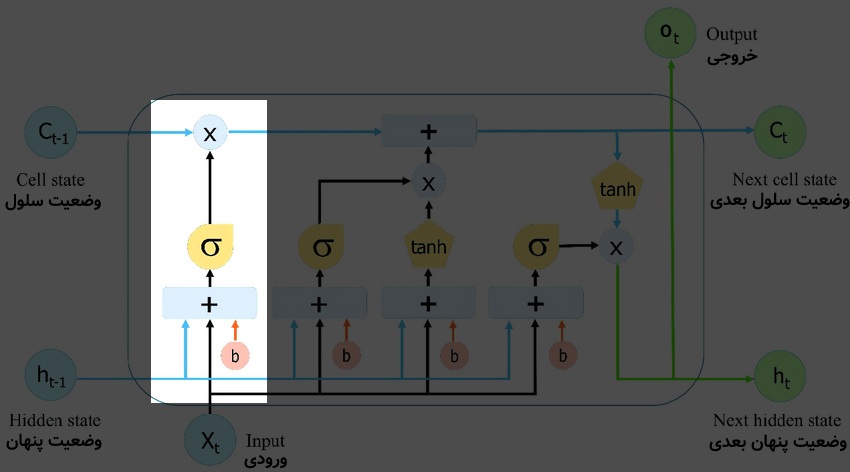
در شکل بالا به بخشِ مشخص شده، درگاهِ فراموشی (forget gate) گفته میشود. این قسمت از بلوک، تصمیم میگیرد که کدام بخش از اطلاعاتِ بلندِ قبلی (توالیهای بلندِ گذشته) در بلوکِ جاری مفید است و کدام بخش مفید نیست. در این قسمت «ورودی فعلی (x)» و «وضعیت پنهان (h) قبلی» با هم ترکیب شده (توسط وزنها) و به تابع فعالسازیِ سیگموید داده میشود و سپس خروجی در «وضعیت سلول (c)» ضرب میشود. در این بخش یادگیری توسط وزنهای یک شبکهی عصبیِ کوچکِ درونی، در هنگام ترکیب x و h انجام میشود تا بتوانند c را ضرب خود تنظیم کنند.
حال به سراغ بخشِ بعدی از بلوک LSTM میرویم:
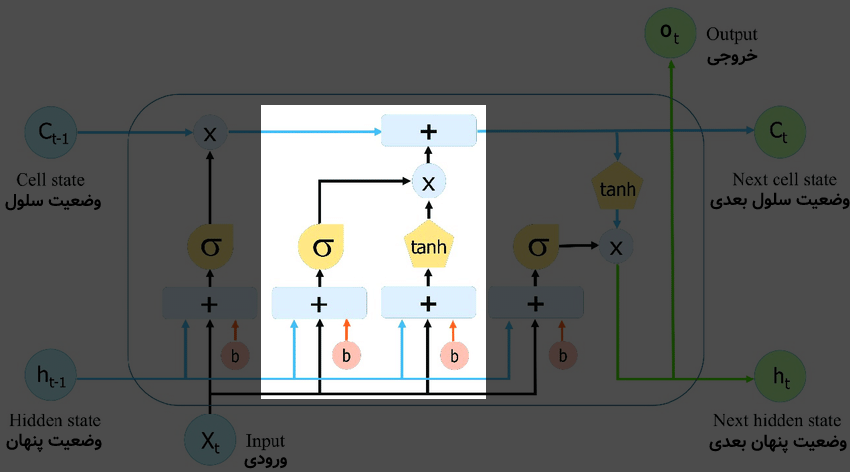
این بخش تصمیم میگیرد که چه اطلاعاتِ جدیدی باید به «وضعیت سول (c)» برای استفادههای بعدی اضافه شود. این قسمت که «درگاه ورودی (input gate)» نامگذاری شده است، با ترکیب «ورودی فعلی (x)» و «وضعیت پنهان (h) قبلی» و ترکیب آن به وسیلهی وزنهای شبکههای عصبیِ کوچکِ درونی با خروجیِ بخش قبل (درگاهِ فراموشی) ساخته میشود.
قسمت آخر این بلوک نیز به شکل زیر است:
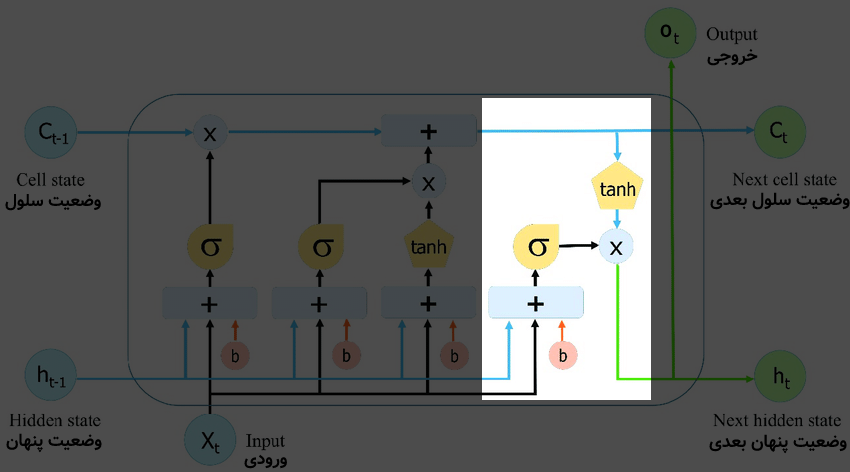
در بخشِ آخر در شکل بالا، «درگاه خروجی» وجود دارد که خروجیها را مشخص میکند. این خروجیها ترکیبی از «وضعیت سلول (c) که آپدیت شده است» به همراه ترکیب «ورودی فعلی (x)» و «وضعیت پنهان (h) قبلی» هستند. در این مرحله نیز یک شبکهی عصبیِ درونی برای یادگیری وجود دارد. خروجیهای h و c در زمان بعدی (t+1) یعنی در توالیِ بعدیِ همین نمونه مورد استفاده قرار میگیرند.
به صورت شهودی، ورودی و خروجیِ «وضعیت سلول (c)» که در LSTM نسبت به RNN ساده اضافه شده است، به عنوان یک بزرگراه عمل میکند که اجازه میدهد اطلاعات در سرتاسر شبکه (توالیها) بدون دخالتِ عناصر پیچیدهتر گذر کرده و گرادیان محو نشود. در واقع RNN ساده مانند یک شهر است و هنگامی که این شهر بزرگ میشود، ترافیکِ زیادی در آن ایجاد شده و مشکل به وجود میآید. از این رو LSTM یک بزرگراه در کنار این شهر ایجاد میکند و اجازهی عبور و مرور سادهتر اطلاعات را برای مسیرهای بلندتر (توالیهای بلندتر) فراهم میآورد.
توجه کنید که مانند RNN ساده، در شبکههای LSTM نیز ورودیِ h و همچین ورودیِ c، یک بردار (vector) هستند که تعداد آن توسط پارامترِ کاربر ایجاد میشود. مثلاً ممکن است تعدادِ عناصرِ بردارِ h و c برابر ۶۴ باشد به این معنی که این دو وضعیت، هر کدام یک بردار ۶۴ عددی هستند. هر چقدر تعداد عناصر بردارهای h و c بزرگتر باشد، احتمال این الگوهای پیچیدهتری کشف شود بالاتر میرود.
شکل زیر برای درکِ بهتر، یک تصویرِ متحرک است که در آن تعداد عناصر بردار وضعیتهای h و c برابر ۲ قرار گرفتهاند. در این شکل شبکه عصبیهای درونی که وزنهای آن برای یادگیری استفاده میشوند نمایش داده شده است:
شبکههای عصبی LSTM معماریهای مختلفی دارند که هر کدام با تغییر کوچکی در ساختار بلوک ایجاد شده است. همچنین مشکل اصلی LSTMها، محاسبات سنگین در هنگام یادگیری و آزمایش است. در دروس بعدی شبکههایی ارائه میکنیم که این مشکل را نیز حل میکنند.

- ۱ » یادگیری عمیق (Deep Learning) چیست؟
- ۲ » تفاوت یادگیری عمیق (Deep Learning) با یادگیری ماشین کلاسیک
- ۳ » تفاوت شبکههای عصبی (Neural Networks) با یادگیری عمیق (Deep Learning) چیست؟
- ۴ » مشکل محوشدگی گرادیان (Gradient Vanishing) در شبکههای عصبی عمیق
- ۵ » مشکل انفجار گرادیان (Exploding Gradients) در شبکههای عصبی عمیق
- ۶ » توابع فعالسازی (Activation Functions) در شبکههای عصبی عمیق
- ۷ » شبکه عصبی پیچشی (Convolutional Neural Network) در یادگیری عمیق
- ۸ » شبکه عصبی بازگشتی (Recurrent Neural Network)
- ۹ » انواع شبکههای عصبی بازگشتی (RNN) و کاربرد آنها
- ۱۰ » شبکه عصبی بازگشتی با حافظهی طولانی کوتاه مدت (LSTM)
- ۱۱ » شبکه عصبی واحد بازگشتی دروازهدار (GRU)
- ۱۲ » شبکههای عصبی عمیق توالی به توالی (Seq2Seq)
{kind=link}