

هنگامی که دادهها به صورت ترتیبی (sequential) یا مبتنی بر سری زمانی (time series) باشند، شبکههای عصبیِ ساده کارایی بالایی نخواهند داشت. از این رو بهتر است که به سراغ معماریهایی برویم که توانایی پردازش دادههای مبتنی بر ترتیب را داشته باشند. شبکههای عصبی بازگشتی که به اختصار به آنها RNN نیز گفته میشود، توانایی شناسایی الگو و یادگیری را از مجموعه دادههای ترتیبی دارند.
برخی از دادهها بهتر است که به صورت ترتیبی پردازش شوند. برای مثال یک سیستم هوشمند را در نظر بگیرید که ترجمهی ماشینی را انجام میدهد. یعنی مجموعهای از کلمات را به عنوان یک جمله دریافت کرده و در خروجی، مجموعه کلمات زبان مقصد را ایجاد کند. چیزی شبیه به شکل زیر:
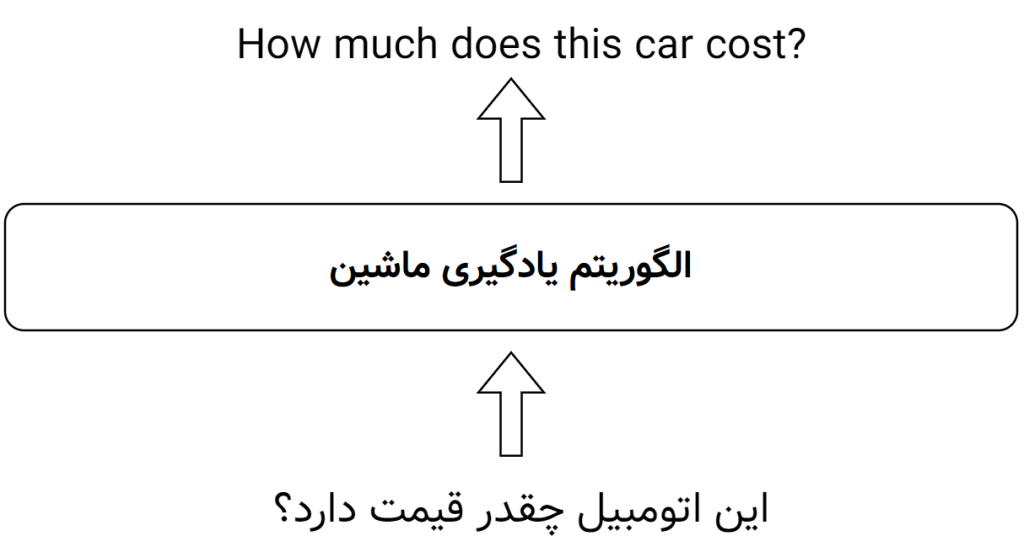
حتماً متوجه شدهاید که در این مثال کلمات ورودی و ترتیب ورود آنهابه الگوریتم اهمیت دارند. در مورد خروجی نیز کلمات و ترتیب آنها مهم است و نباید کلمات، جابهجا وارد یا خارج شوند. به این دست از دادهها، مجموعه دادههای ترتیبی (sequential) میگوییم.
بسیار از مسائل، دادههایی مبتنی بر ترتیب و توالی دارند. به عنوان یک مثالِ دیگر، پیشبینی قیمتِ یک رمزارز مبتنی بر قیمت روزهای گذشته را میتوان بیان کرد که این نیز نوعی دادهی سری زمانی (time series) بوده و از نوع دادههای ترتیبی است.
در حالت ترتیبی اگر بخواهیم دادهها را یکی پس از دیگری، به ترتیب وارد الگوریتمِ یادگیری ماشین (مثلاً شبکههای عصبی ساده) کنیم، الگوریتم با مشاهدهی دادهی شمارهی n، بایستی دادهی شمارهی n-1 را نیز مشاهده کند ولی به صورت پیشفرض چنین قابلیتی در الگوریتمهای ساده مانند شبکههای عصبی ساده (MLP) فراهم نشده است. در واقع یک شبکهی عصبی مانند پرسپترون چند لایه (MLP)، حافظهای برای یادگیریِ ترتیبی از دادهها ندارد و با مشاهدهی یک نمونه از مجموعهی آموزشی و آپدیت کردن وزنها، به سراغ نمونه بعدی رفته و ترتیب و توالی را در حافظهی خود ذخیره نمیکند.
در شبکههای عصبی بازگشتی (RNN)، شبکه طوری طراحی شده است که نوعی حافظه در درون خود داشته باشد و بتواند تعداد n داده را به صورت متوالی مشاهده کند. برای فهمِ بهتر فرض کنید میخواهیم سیستم هوشمندِ ترجمهی ماشینی را ایجاد کنیم که با دریافتِ توالی کلمات یک جمله به زبان فارسی بتواند توالیِ کلماتِ معادل انگلیسی آن را تولید کند. برای این کار بایستی مجموعهای از جملات فارسی به همراه ترجمهی آن را به عنوان مجموعهی آموزشی داشته باشیم و یکی یکی آنها را برای آموزش به الگوریتم تزریق کنیم.
یک معماری از شبکههای عصبی بازگشتی (RNN) برای یادگیری جهت ترجمهی ماشینی به صورت زیر میتواند باشد:
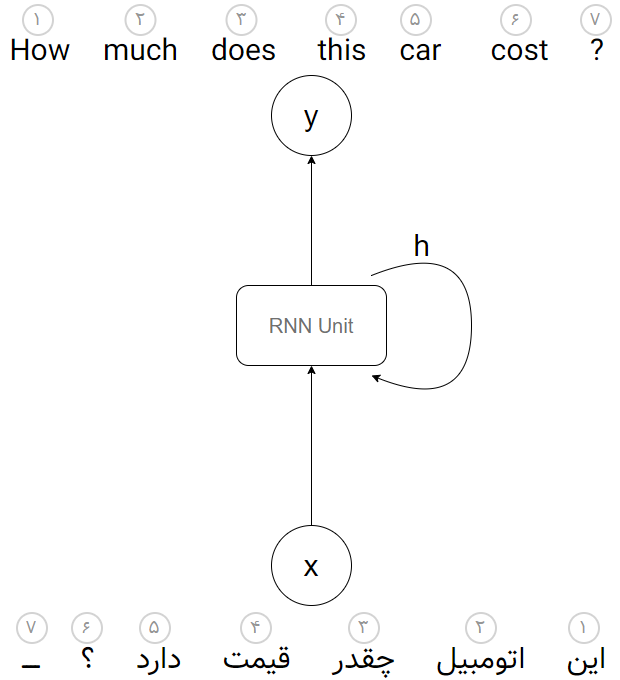
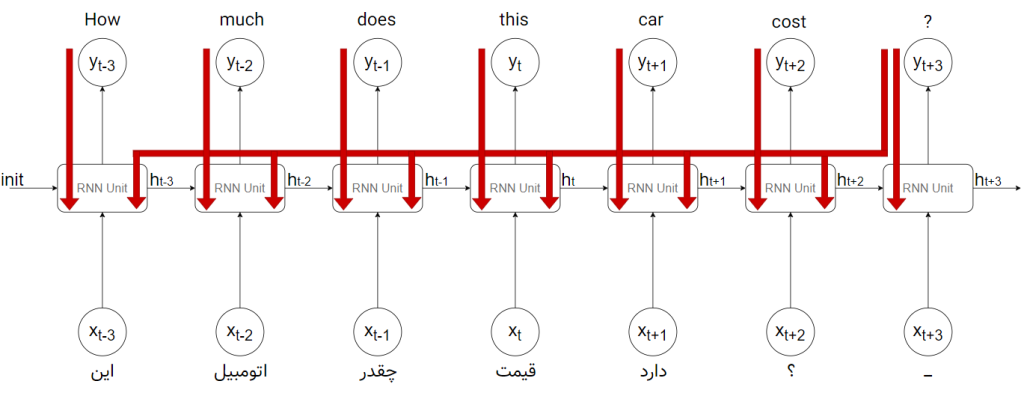
در شکل بالا یک جمله به صورتِ توالیای از کلماتِ ورودی به الگوریتم تزریق شده است. فعلاً فرض میکنیم که هر جملهی ورودی/خروجی حداکثر ۷ کلمه دارد. کلمات یکی یکی به بلوک (RNN Unit) تزریق میشوند و این بلوک با مشاهدهی کلمهی اول (کلمهی «این»)، علاوه بر خروجیِ y (خروجی «How»)، یک خروجیِ دیگر به نام «وضعیت پنهان» یا همان hidden state که با h در شکل نمایش داده شده است را برای استفادههای بعدی تولید میکند. این همان حافظهی شبکهی عصبی RNN است که در خود ذخیره میشود. در هنگام ورودیِ کلمهی دوم (کلمهی «اتومبیل»)، این وضعیت پنهانی که حاصلِ خروجیِ کلمهی اول بود (h1) را نیز دریافت کرده و این دو ورودی با هم به محاسبهی خروجی دوم (کلمهی «much») منجر شده و وضعیت پنهان جدید (h2) میشود. حال نوبت به کلمهی سوم میرسد. دو مرتبه این بلوک با مشاهدهی کلمهی سوم (کلمهی «چقدر») و وضعیت پنهان قبلی (h2) که حافظهی الگوریتم از دو کلمهی قبلی بود، به یک خروجیِ جدید (کلمهی «does») رسیده و دومرتبه یک وضعیت پنهانِ جدید (h3) برای استفادههای بعدی را تولید میکند. این کار به همین ترتیب تکرار شده تا تمامیِ هفت ورودی دریافت و هفت خروجی تولید شود.
شکل بالا میتواند به صورت زیر باز شده تا بهتر درک شود:
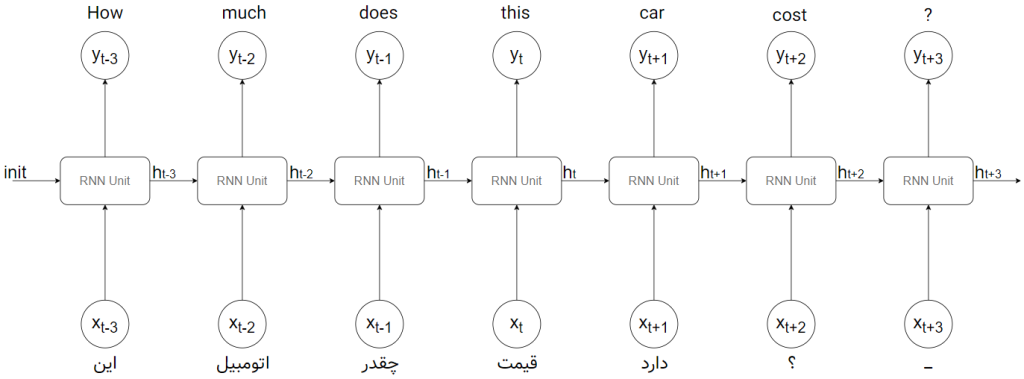
همانطور که مشاهده میکنید، دادهها به ترتیب زمان یکی یکی به بلوک داده میشود. توجه کنید که در شکل بالا، ما یک بلوک داریم (وزنها یکی هستند) ولی برای درک بهتر آن را به صورت هفت بلوک در زمانهای مختلف نمایش دادهایم. یعنی در این شکل وزنها مشترک هستند و این شکل، دقیقاً معادل شکل بالاتر است.
منظور از زمان در اینجا همان توالی و ترتیب رسیدن عناصر است. مثلاً در زمانِ اول، کلمهی «این» به بلوک داده میشود. بلوک کلمهی «How» را در خروجی قرار داده و یک وضعیت پنهان (h) را به خود باز میگرداند. این کار ۷ مرتبه تکرار میشود و هر بار علاوه بر خروجی، وضعیت پنهان برای استفادههای بعدی تولید شده و همراه با ورودیِ بعدی به خود بلوک تزریق میشود. توجه کنید که تمامیِ توالی کلمات که به صورت یک جمله به الگوریتم تزریق شده است، یک نمونه از دادهها هستند و برای نمونهی بعدی (جملهی بعدی) دو مرتبه ترتیبی از کلمات آن جمله به بلوک تزریق میشود.
در تصویر متحرک زیر که برای ترجمهی جمله از انگلیسی به فارسی میتواند مورد استفاده قرار گیرد، این موضوع به خوبی نمایان است:

حال اجازه دهید نگاهی دقیقتر به نحوهی محاسبهی خروجی و وضعیت پنهان در هر بلوک (RNN Unit) داشته باشیم. شکل زیر داخل یک بلوک RNN را نمایش میدهد:
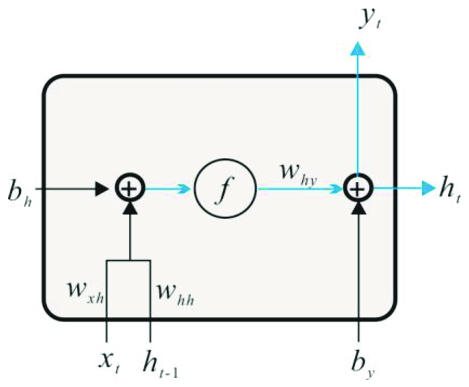
شاید در ابتدا کمی پیچیده به نظر برسد، ولی نحوهی محاسبهی هر کدام از خروجیها ساده است. برای مثال خروجی h در زمان t، حاصل جمع یک بایاس و یک وزن است که پس از اعمالِ یک تابع فعال سازیِ f مثل تانژانت هیپربولیک (tanh) به دست میآید. خروجی h در زمان t به عنوان ورودی h در زمان بعدی به همراه ورودی x بعدی به بلوک تزریق میشود و این بلوک با ضربِ ورودیها در وزنهای Whh و Wxh، به همراه یک بایاس و سپس اعمال تابع فعالسازی و یک وزن دیگر (Why)، خروجیِ بعدی و وضعیت پنهانِ بعدی را ایجاد میکند. وزنها و وزنهای بایاس عناصری هستند که مقدارِ آنها را الگوریتم در هنگام آموزش، یاد میگیرد. معماریهای مختلفی برای RNNها ارائه شده است که در معماری شکل بالا، در هر بلوک ۵ عنصر برای آپدیت کردن و یادگیری وجود دارد.
همانطور که مشاهده میکنید، هر کدام از خروجیها با استفاده از مقادیرِ عناصری (وزنها و بایاس) که در هنگام یادگیری از مجموعهی آموزشی آپدیت میشوند، یادگیری را انجام میدهند. در واقع یک شبکه عصبی RNN مانند شبکههای عصبی ساده رفتار میکند با این تفاوت که بلوکهای تشکیل دهندهی آن کمی پیچیدهتر شده و دارای حافظه از ورودی قبلی هستند.
در فرآیند یادگیری نیز، مانند شبکههای عصبی ساده بایستی وزنها با استفاده از پسانتشار خطا (back propagation of error) آپدیت شوند. ولی چون در شبکههای RNN به نوعی ترتیب زمانی در هر نمونه تاثیر دارد، در این شبکهها فرمول پسانتشار خطا کمی تغییر میکند و به آن «پسانتشار خطا در طول زمان» (back propagation through time) یا به اختصار BPTT میگویند. در شکل زیر نوعی پسانتشار خطا در طول زمان را مشاهده میکنید:
نکتهی مهم در الگوریتم شبکههای عصبی بازگشتی (RNN) این است که هر بلوک سه وزن ساده و دو وزنِ بایاس (مجموعاً پنج وزن قابل یادگیری) برای آپدیت شدن در هنگام پسانتشار خطا دارد و با این اوزان یادگیری را از روی مجموعهی آموزشی انجام میدهد.
همچنین در RNNها، ورودی «وضعیت پنهان (h)» یک بردار با تعداد n عنصر است. تعدادِ این n عنصر توسط کاربر در هنگام ساخت شبکه مشخص میشود و هر چقدر این تعداد بالاتر برود، شبکه توانایی کشف الگوهای پیچیدهتر را دارد. به همین دلیل برای آپدیت و یادگیریِ وزنها از یک شبکهی عصبی کوچک درونی برای ترکیب ورودیها (xها) و وضعیتهای پنهان (hها) استفاده میشود. چیزی شبه به تصویر متحرک زیر که در آن تعدادِ عناصر بردار h برابر ۲ است:
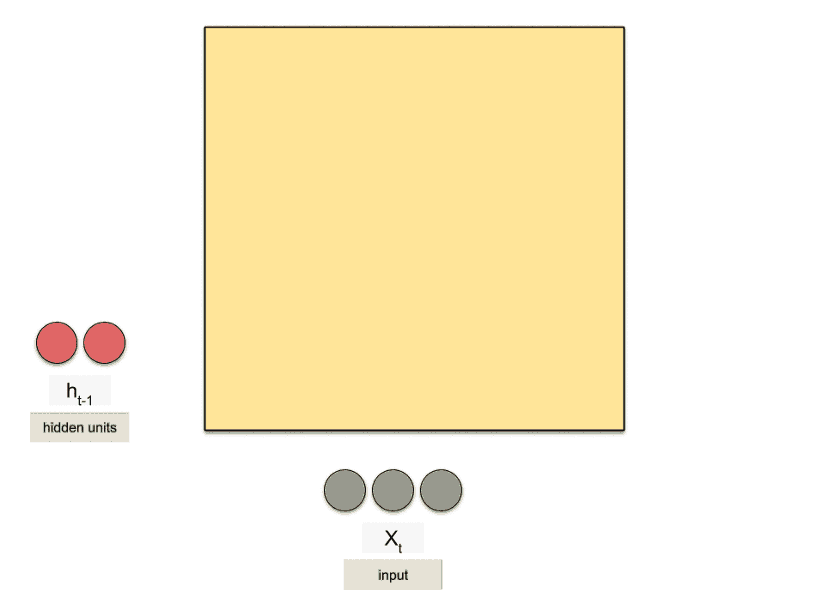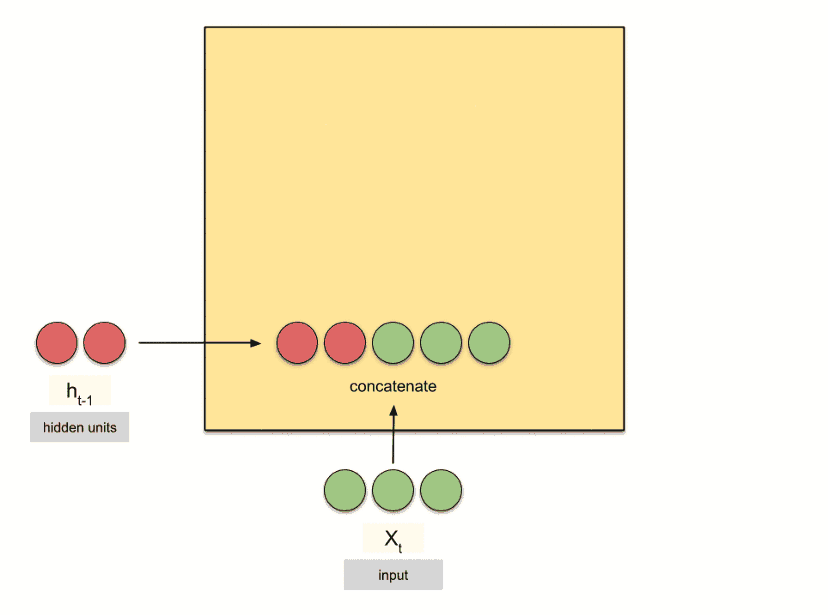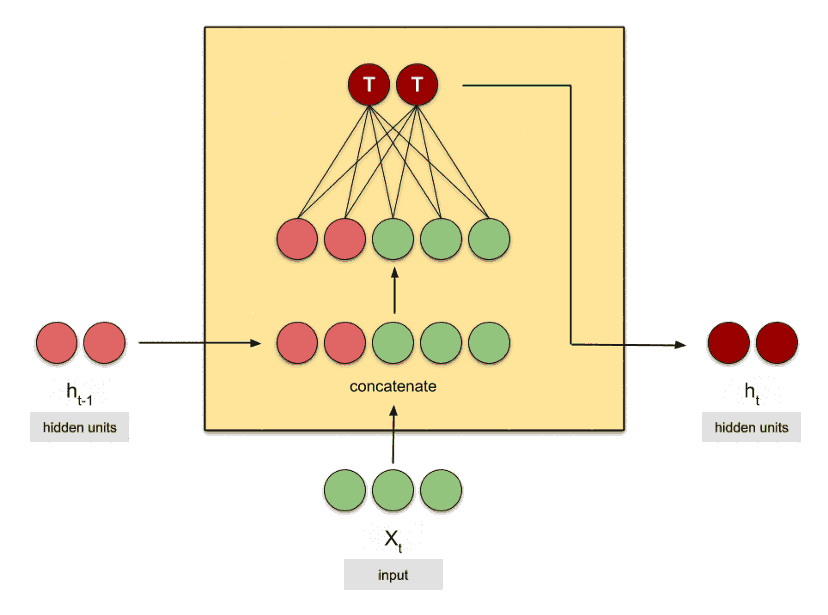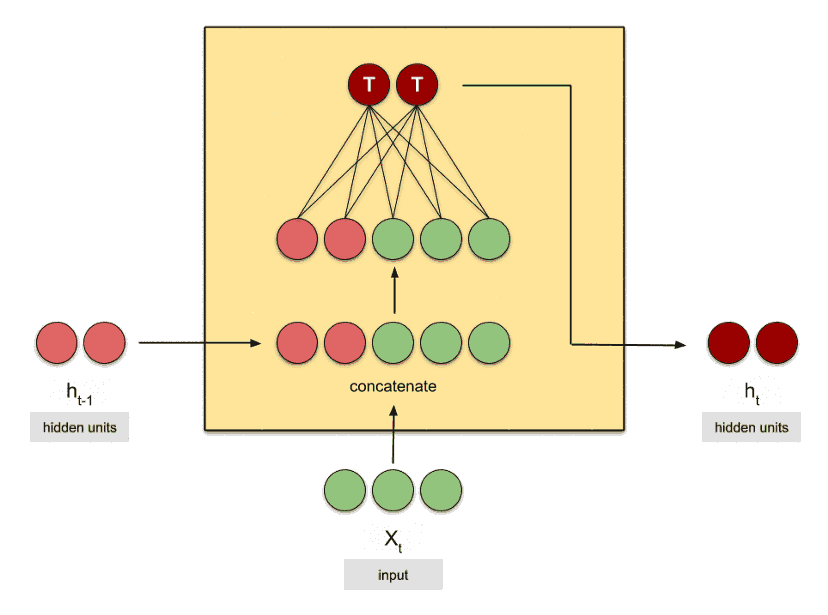
شبکههای RNN انواع مختلفی داشته که هر کدام از آنها در حل مسائل مختلف کاربرد دارند. برای مثال معماریِ ارائه شده در شکهای بالا، نمیتواند با دقت خوبی ترجمهی ماشینی را انجام دهد. در دروس آینده به انواع شبکههای RNN و کاربرد هر کدام از آنها خواهیم پرداخت.

- ۱ » یادگیری عمیق (Deep Learning) چیست؟
- ۲ » تفاوت یادگیری عمیق (Deep Learning) با یادگیری ماشین کلاسیک
- ۳ » تفاوت شبکههای عصبی (Neural Networks) با یادگیری عمیق (Deep Learning) چیست؟
- ۴ » مشکل محوشدگی گرادیان (Gradient Vanishing) در شبکههای عصبی عمیق
- ۵ » مشکل انفجار گرادیان (Exploding Gradients) در شبکههای عصبی عمیق
- ۶ » توابع فعالسازی (Activation Functions) در شبکههای عصبی عمیق
- ۷ » شبکه عصبی پیچشی (Convolutional Neural Network) در یادگیری عمیق
- ۸ » شبکه عصبی بازگشتی (Recurrent Neural Network)
- ۹ » انواع شبکههای عصبی بازگشتی (RNN) و کاربرد آنها
- ۱۰ » شبکه عصبی بازگشتی با حافظهی طولانی کوتاه مدت (LSTM)
- ۱۱ » شبکه عصبی واحد بازگشتی دروازهدار (GRU)
- ۱۲ » شبکههای عصبی عمیق توالی به توالی (Seq2Seq)
ساده، روان، مختصر و بسیار مفید
مرسی بابت مطالب ارزشمندی که رایگان در اختیار کاربران قرار میدید.
قدر زر زرگر شناسد
قدر گوهر گوهری
موفق باشید