

اگر با الگوریتمهای طبقهبندی کار کرده باشید (و یا حداقل جایی خوانده باشید) متوجه میشوید که عبارتِ دادههای آموزشی یا همان training sets در کتابها و مقالات، بسیار تکرار میشود. در این نوشته میخواهیم ببینیم منظور از training sets چیست و چگونه میتوان از آن در طبقهبندیِ دادهها استفاده کرد.
یک مثالِ جالبْ برای درکِ بهترِ دادههای آموزشی و مورد کاربرد آنها میتواند به صورت زیر باشد:
فرض کنید شما یک دانشجو هستید و معلم ۱۰۰ سوالِ نمونه همراه با جواب در اختیار شما قرار داده است. شما بایستی با خواندن این ۱۰۰سوالْ خود را برای امتحان آماده کنید. به این ۱۰۰ سوال به نوعی دادههای آموزشی گفته میشود زیرا شما از این دادهها برای آموزش خود و آمادگی برای امتحانِ اصلی، استفاده میکنید. البته از آنجایی فرض بر این است که شما فقط ۱۰۰ سوال دارید و هیچ منبعِ دیگر در اختیار ندارید، نمیتوانید خود را قبل از امتحان ارزیابی کنید. پس معقول است که به صورت تصادفی (random)، از میان این ۱۰۰ سوال، مثلاً ۷۰ سوال را جدا کرده، آنها را بخوانید و خوب یاد بگیرید. سپس ۳۰ سوالِ باقیمانده، دادههای آزمایشی برای ارزیابی هستند که بایستی توسط آنها، خود را قبل از آزمونِ واقعی بیازمایید. توجه کنید که ۷۰ سوال و ۳۰ سوالی که تقسیم بندی کردهاید، جوابهایش را دارید. در واقع با خواندن ۷۰ سوال و دیدن جوابهای آنها، یادگیری را انجام میدهید و سپس ۳۰ سوال باقی مانده را برای ارزیابیِ خود میگذارید. ۳۰ سوال را خوانده و برای خود جواب میدهید، سپس جوابهای داده شده را با جوابهایی واقعیِ همان ۳۰ سوال، مقایسه میکنید و دقت و صحتِ خود را در پاسخ دادن به سوالات میسنجید.
این همان کاری است که بایستی در یک الگوریتمِ یادگیری ماشین (معمولا الگوریتمهای طبقهبندی) انجام شود. شما یک مجموعه داده در اختیار دارید که هر کدام برچسبِ (lable) خود را دارند. اگر با این موضوع آشنا نیستید مثال درس طبقهبندی را نگاه کنید. حال این دادهها را به نسبت (مثلاً در اینجا ۷۰ به ۳۰) تقسیم میکنید. الگوریتم از روی ۷۰ درصدِ دادهها، عملیاتِ یادگیری را انجام میدهد و از روی ۳۰ درصد بقیه، خود را ارزیابی میکند و نتیجهی تست را به شما میگوید. به این ترتیب میتوانید بفهمید که این الگوریتم چه مقدار دقت دارد. در واقع هنگامی که دادههای واقعی از راه میرسند، میخواهیم بدانیم که این الگوریتم چقدر میتواند دقت داشته باشد (منظور از دادههای واقعی، دادههایی است که در مجموعه دادههای آموزشی نیستند و میخواهیم واقعا عملیاتِ دادهکاوی و طبقهبندی را بر روی آنها انجام دهیم). اگر هنوز مسئله برایتان جا نیفتاده است تصویر زیر را نگاه کنید:
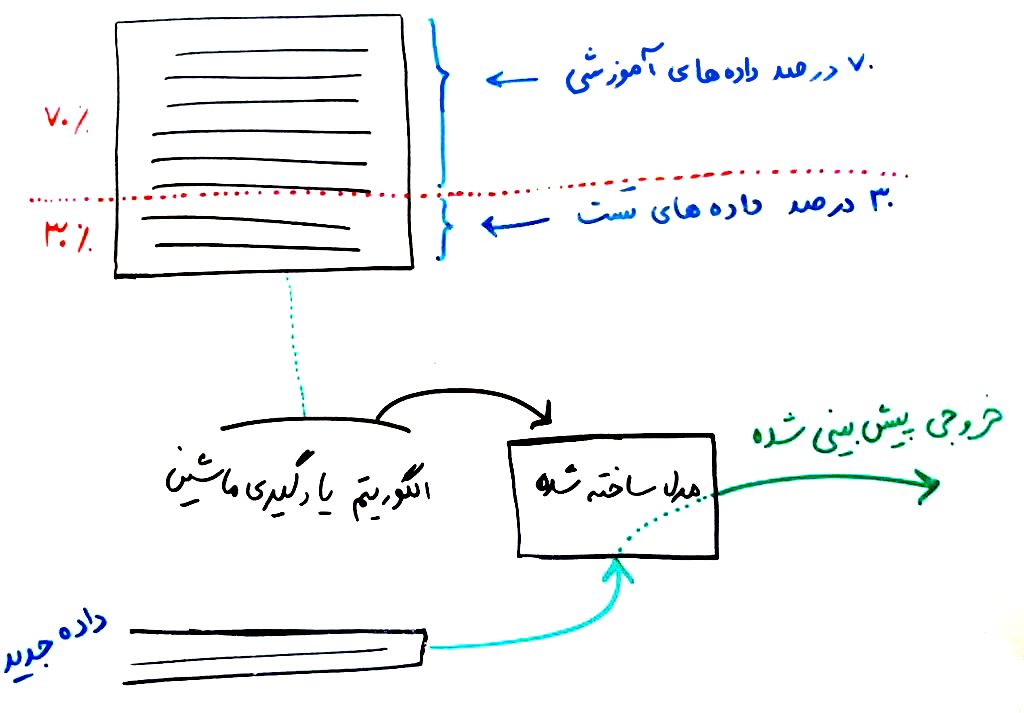
در هنگامِ آموزش، دادهها را به دو دستهی آموزشی و ازریابی تقسیمبندی میکنیم. حال الگوریتم از روی دادههای آموزشی یادگیری را انجام میدهد و از روی دادههای ارزیابی یا همان دادههای تست میتوانید بفهمید که الگوریتم و مدلِ ساخته شده توسطِ آن، چقدر دقت داشته است. وقتی الگوریتمْ عملیاتِ یادگیری را انجام داد و در واقع یک مدل را از روی این دادهها ساخت، حالا میتوان از روی این مدل، عملیاتِ دادهکاوی را بر روی دادههای جدید انجام داد.

- ۱ » دادهکاوی (Data mining) چیست؟
- ۲ » یادگیری ماشین (Machine Learning) چیست؟
- ۳ » تفاوت هوش مصنوعی، یادگیری ماشین، دادهکاوی، یادگیری عمیق و علم داده
- ۴ » طبقهبندی (Classification) چیست؟
- ۵ » خوشهبندی (Clustering) چیست؟
- ۶ » تفاوت طبقهبندی (Classification) و خوشهبندی (Clustering)
- ۷ » منظور از دادههای آموزشی (Training Sets) در طبقهبندی چیست؟
- ۸ » سیستم توصیه گر (Recommendation System) چیست؟
- ۹ » کاربرد دادهکاوی و یادگیری ماشین در پردازش متن (Text Processing)
- ۱۰ » معرفی چند نرم افزار کاربردی برای عملیات دادهکاوی
- ۱۱ » ویژگی (Feature) یا همان بُعد (Dimension) در دادهکاوی چیست؟
- ۱۲ » بررسی چند الگوریتم یادگیری ماشین (Machine Learning)
- ۱۳ » یادگیری دستهای (Batch Learning) و یادگیری برخط (Online Learning)
- ۱۴ » یادگیری فعال (Active Learning) در یادگیری ماشین
- ۱۵ » انتخاب ویژگی (Feature Selection) چیست؟
- ۱۶ » تفاوت داده ساختاریافته (Structured) با غیرساختاریافته (Unstructured) چیست؟
- ۱۷ » منظور از متغیر وابسته (Dependent) و مستقل (Independent)
- ۱۸ » مجموعه دادههایی با ابعاد زیاد (High Dimensional)
- ۱۹ » مجموعه دادهی نامتوازن (Imbalance) چیست؟
- ۲۰ » فرآیند کریسپ (CRISP) جهت انجام پروژههای دادهکاوی
- ۲۱ » رانش یا گذار در دادهها (Data Drift)
بسیار عالی… خیلی ممنون
با سلام خدمت جناب مهندس کاویانی
وو با تشکر از مطالب بسیار عالی که به رایگان به اشتراک می گذارید
لطف می فرمایید در مورد مفاهیم داده کاوی : دقت – صحت – حساسیت و مواردی که در ارزیابی استفاده می شود توضیحاتی ارایه کنید
در بعضی مطالب دقت را برابر Accuracy در نظر می گیرند و برخی دیگر دقت را معادل لاتین Precision مطرح می کنند
ممنون می شوم اگر توضیحات کاملی ارایه بدهید
سلام. Accuracy صحیح هست و بیشتر به کار میره. در ضمن نباید خودتون رو زیاد درگیر واژه ها کنید. مهم مفهوم کار هست و میتونید هر واژه ای که دیدید رو ترجمه کنید و ربطش بدید به اون مفهومی که برداشت کرده اید. موفق باشید.
سلام. ببخشید الان Training Sets به معنی کدوم شد؟ مجموعه آموزشی یا کل داده های آموزش و تست با هم ، یا فقط داده های تست
با سلام
فقط مجموعهی آموزشی
ممنون
در مورد انتخاب نسبت داده های موزشی به اعتبار سنجی منبعی دارید؟
سلام در مورد نسبت داده های اموزشی ازمایش و علت نوع دسته بندی منبعی داریم؟؟؟
عالی خیلی ممنون
متشکر از توضیحات
با سلام و خداقوت
بنده سوالی در رابطه با انتخاب دوره آماری داشتم
یکسری داده از سال ۱۹۹۲-۲۰۲۱ در اختیار داریم و از سال ۱۹۹۲-۲۰۱۷ بعنوان دوره آموزشی در نظر میگیریم و از سال ۲۰۱۸-۲۰۲۱ را بعنوان دوره تست مدل در نظر میگیریم حالا سوال بنده اینست چرا بصورت رندوم انتخاب نمیشه؟
با سلام
این نسبت تقسیم بندی داده ها بر چه اساسی صورت میگیرد؟
مثلا چرا ۵۰ به ۵۰ تقسیم نمیشود یا اگر این نسبت تغییر کند در دقت مدل اثر دارد؟
سلام
هر چقدر تعداد دادهها بیشتر باشد، نسبت کمتری از دادهها را میتوان به مجموعهی دادهی آموزشی داد. برای تعیین دقیقتر میتوان از روشهای KFold Cross Validation استفاده کرد
با عرض سلام
بهترین نسبت داده آموزشی به داده تست در روش مکسنت چیست؟