

کاربرد اصلیِ الگوریتمهای یادگیری ماشین این است که اطلاعات موجود در دادهها را استخراج کنند یا از دادههای موجود یاد بگیرند. مانند بچهای که با مشاهدهی افراد و توصیههای والدین یادگیری را انجام میدهد. مثلا میتواند بفهمد که بخاری داغ است یا نباید به تنهایی از خیابان رَد شود. در واقع کار الگوریتمهای یادگیری ماشین یا همان machine learning این است که یک خلاصه (summarize) از دادهها را پیدا کنند یا در واقع یک مُدل (model) از دادهها با هر روشی ایجاد کنند. همان طور که میدانید یک مدل همواره شاملِ خلاصهای از دادهها است. برای مثال نقشه جهان یک مدل از جهان است که کشورها و راهها را بدون توجه به جزئیات زیاد (مثلاً اینکه چه مغازهای در چه خیابانی است) نگاشت میکند.
البته اینطور نیست که تمامیِ الگوریتمهای یادگیری ماشین خلاصهسازیِ دادهها را انجام دهند. اگر به الگوریتمهای خوشهبندی یا همان clustering در دوره خوشهبندی در درسهای آتی نگاهی بیندازید، متوجه میشود که این الگوریتمها میتوانند دادهها را به صورت خودکار به گروهها (خوشهها) تقسیم بندی کنند. علاوه بر این، الگوریتمهای خوشهبندی میتوانند دادههای جدید که از راه میرسند را به یکی از خوشههای قبلیْ که مدل کردهاند، ملحق کنند.
با این مقدمه اگر بخواهیم ساده نگاه کنیم، الگوریتمهای یادگیریماشین در دو دستهی کلیْ قرار میگیرند. یکی از آنها الگوریتمهایی است که به خوشهبندی (clustering) معروف هستند و در دورهی خوشهبندی به آنها خواهیم پرداخت و دیگری الگوریتمهایی که عملیات طبقهبندی (classification) را انجام میدهند و در دورهی طبقهبندی به آنها توجه خواهیم کرد.
دادههای مورد نیاز برای الگوریتمهای خوشهبندی، نیاز به دانستنِ برچسبِ دادهها ندارند. یعنی به الگوریتم نمیگوییم که هر کدام از دادهها، در کدام دسته بندیْ قرار میگیرند. در واقع هیچ پیشفرضی در مورد اینکه دادههای موجود در چه طبقه یا دسته یا گروهی قرار میگیرند نداریم و الگوریتم به صورت خودکار گروهبندیِ دادهها را کشف میکند. به همین دلیل به این دست از الگوریتمها، الگوریتمهای یادگیریِ غیرنظارتشده (unsupervised learning) میگویند.
این در حالی است که گونهی دیگرِ الگوریتمهای یادگیری ماشین، الگوریتمهای یادگیریِ ماشینِ نظارتشده (supervised) هستند. این الگوریتمها، که به آنها طبقهبندها نیز گفته میشود، دادههایی را دریافت میکنند که از قبلْ برچسبزده شده باشند. در مورد این الگوریتمها نیز در دوره طبقهبندی بحث خواهیم کرد.
البته نوعی دیگر از الگوریتمها نیز وجود دارند که چیزی بینِ دو گونهی قبلی هستند. به این دسته، الگوریتمهای یادگیری نیمه نظارت شده (semi supervised learning) گفته میشود. در این دسته از الگوریتمها، برخی از نمونهها برچسب دارند و برخی ندارند. این الگوریتمها را در درسها و دورههای آتی بررسی خواهیم کرد.
پس اگر بخواهیم یک نقشهی ذهنی در مورد انواع الگوریتمهای یادگیری ماشین داشته باشیم، میتوانیم به شکل زیر برسیم:
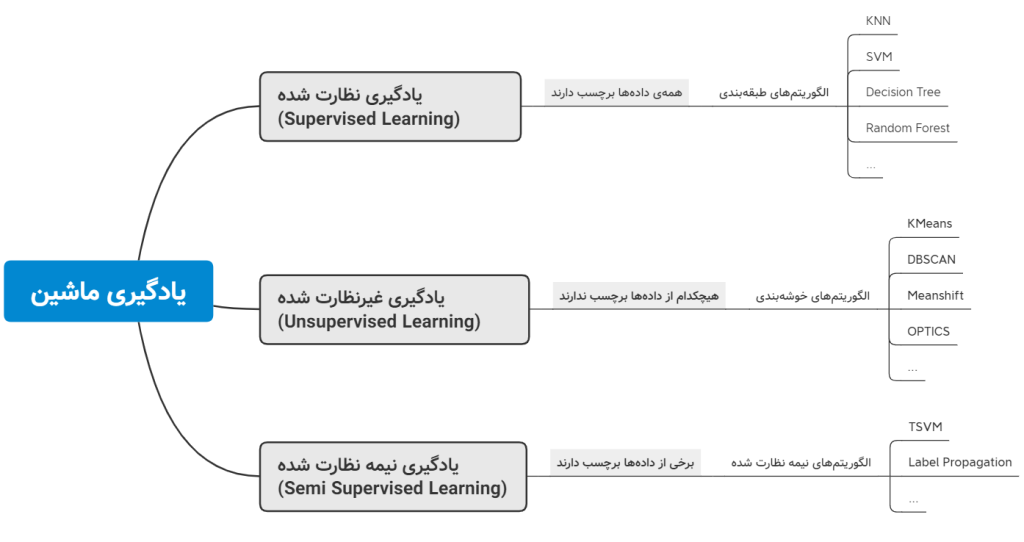
البته این یک نقشهی ذهنی ناکامل است و یادگیری ماشین بخشهای مختلف دیگری نیز دارد که به مرور با یکدیگر فرا میگیریم.

- ۱ » دادهکاوی (Data mining) چیست؟
- ۲ » یادگیری ماشین (Machine Learning) چیست؟
- ۳ » تفاوت هوش مصنوعی، یادگیری ماشین، دادهکاوی، یادگیری عمیق و علم داده
- ۴ » طبقهبندی (Classification) چیست؟
- ۵ » خوشهبندی (Clustering) چیست؟
- ۶ » تفاوت طبقهبندی (Classification) و خوشهبندی (Clustering)
- ۷ » منظور از دادههای آموزشی (Training Sets) در طبقهبندی چیست؟
- ۸ » سیستم توصیه گر (Recommendation System) چیست؟
- ۹ » کاربرد دادهکاوی و یادگیری ماشین در پردازش متن (Text Processing)
- ۱۰ » معرفی چند نرم افزار کاربردی برای عملیات دادهکاوی
- ۱۱ » ویژگی (Feature) یا همان بُعد (Dimension) در دادهکاوی چیست؟
- ۱۲ » بررسی چند الگوریتم یادگیری ماشین (Machine Learning)
- ۱۳ » یادگیری دستهای (Batch Learning) و یادگیری برخط (Online Learning)
- ۱۴ » یادگیری فعال (Active Learning) در یادگیری ماشین
- ۱۵ » انتخاب ویژگی (Feature Selection) چیست؟
- ۱۶ » تفاوت داده ساختاریافته (Structured) با غیرساختاریافته (Unstructured) چیست؟
- ۱۷ » منظور از متغیر وابسته (Dependent) و مستقل (Independent)
- ۱۸ » مجموعه دادههایی با ابعاد زیاد (High Dimensional)
- ۱۹ » مجموعه دادهی نامتوازن (Imbalance) چیست؟
- ۲۰ » فرآیند کریسپ (CRISP) جهت انجام پروژههای دادهکاوی
- ۲۱ » رانش یا گذار در دادهها (Data Drift)
با سلام
در انتهای مطلب در مورد پیاده سازی موازی الگوریتم ها صحبت شده. امکانش هست بیشتر توضیح دهید.
ممنونم
سلام پیاده سازی موازی به چه معنی هست