

اگر درس طبقهبندی (Classification) را خوانده باشید، میدانید که منظور ما از طبقه یا کلاس یا همان برچسب چیست. برای مثال در همان درسِ طبقهبندی دیدیم که مدیرِ یک بانک میخواست از روی ویژگیهای مختلفِ مشتریها، تصمیم بگیرد که به آنها وام بدهد/یا خیر. پس مجموعهی دادهای از مشتریهای قبلی آماده میکرد و ویژگیهای آنها به همراه بازپرداخت وام را برای هر یک به دست میآورد و در مجموعهی دادهی آموزشی قرار میداد. فرض کنید، از بین ۱۰هزار مشتری بانک، ۵هزار نفر آنها توانسته باشند وام را پس دهند و ۵هزار نفر نتواسته باشند وام خود را پس دهند. پس در اینجا یک مجموعهی دادهی متوازن داریم به صورتی که هر کدام از طبقهها به صورت تقریبی یک اندازه داده دارند و الگوریتمِ طبقهبندی میتواند الگوهای هر دسته را پیدا کرده و یادگیری خود را از روی این مجموعهی داده انجام دهد. اما همهی مجموعهی دادهها به این صورت متوازن نیستند.
فرض کنید مجموعهی دادهای از تراکنشهای بانکی دارید. برخی از این تراکنشها، تراکنشهای سرقتی هستند. برای مثال کارت بانکی به همراه رمز آن، دزدیده شده است و شخصِ سارق، میخواهد از آن حساب برداشت کند. حال به الگوریتمی نیاز داریم تا بتواند هر تراکنش را بررسی کرده و با توجه به دادههای گذشته، بفهمد که این تراکنش جدید، آیا تراکنش سالمی است یا تراکنش سرقتی.
برای انجام این پروژه بانک مرکزی به همراه نیروی انتظامی، در مدت یک سال تراکنشهای مختلف را ارزیابی کردهاند و برخی از این تراکنشها را به عنوان تراکنش سرقتی (با استفاده از اطلاعات انتظامی) برچسب گذاری کردهاند. برای هر تراکنش نیز، ویژگیهایی نیز در نظر گرفته شده است (برای مثال ساعت انجام تراکنش، تاریخ تراکنش، میانگین حساب شخص و مقدار تراکنش). مجموعهی داده چیزی مانند شکل زیر است:
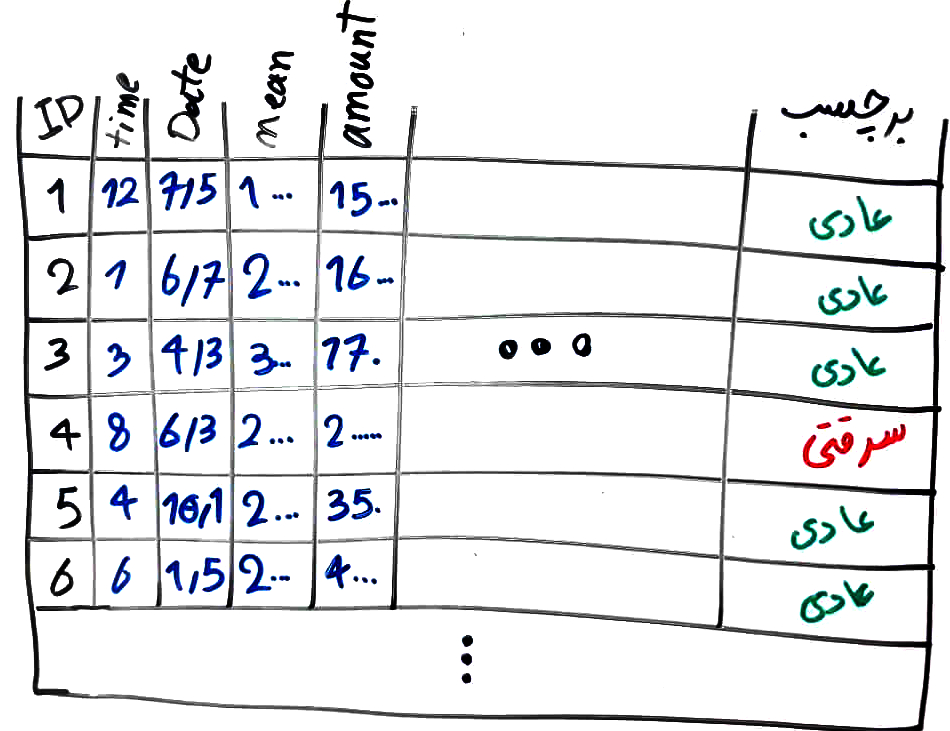
همانطور که مشاهده میکنید درصدِ بسیار کمی از تراکنشها (شاید کمتر از یک دهم درصد) تراکنشهای سرقتی هستند و اکثر تراکنشها را تراکنشهای عادی تشکیل میدهند. ما مجموعهی دادهی بالا را به یک الگوریتم طبقهبندی تزریق میکنیم تا یادگیری را انجام دهد. در این مواقع نباید انتظار داشته باشیم که الگوریتمهای طبقهبندی به درستی یاد بگیرد زیرا این الگوریتمها عموماً به سمتِ طبقههایی با برچسب اکثریت، تمایل پیدا میکنند. برای نمونه، در مثال بالا یک الگوریتم طبقهبندی عادی مانند SVM بعد از یادگیری از مجموعهی دادهها، تمامیِ تراکنشهای جدید را به عنوان تراکنش عادی طبقهبندی میکند!
در این شرایط معیار ارزیابی طبقهبندی نیز بایستی تغییر کند و نمیتوان از معیارهای عادی مانند معیار دقت (Accuracy) استفاده کرد. چون برای مثال در همان مجموعهی دادهی بالا، اگر یک الگوریتم تمامیِ نمونههای جدید را به عنوان تراکنش عادی تقسیم بندی کند، دقت تقریباً ۹۹/۹۹ درصد میشود ولی حتماً میدانید که در این دست از مسائل، نمیتوانیم به این معیار دقت (Accuracy) اعتماد کنیم.
در این شرایط بایستی از روشهای مختلف متعادلسازی دادهها (Data Balancing) و یا الگوریتمهای خاصی استفاده کرد. البته این دادههای نامتوازن فقط در دستهی مسائل طبقهبندی نیستند و ممکن است در مسائل خوشهبندی نیز دادههای نامتوازن داشته باشیم که راهحلهای مربوط به خود را دارد.

- ۱ » دادهکاوی (Data mining) چیست؟
- ۲ » یادگیری ماشین (Machine Learning) چیست؟
- ۳ » تفاوت هوش مصنوعی، یادگیری ماشین، دادهکاوی، یادگیری عمیق و علم داده
- ۴ » طبقهبندی (Classification) چیست؟
- ۵ » خوشهبندی (Clustering) چیست؟
- ۶ » تفاوت طبقهبندی (Classification) و خوشهبندی (Clustering)
- ۷ » منظور از دادههای آموزشی (Training Sets) در طبقهبندی چیست؟
- ۸ » سیستم توصیه گر (Recommendation System) چیست؟
- ۹ » کاربرد دادهکاوی و یادگیری ماشین در پردازش متن (Text Processing)
- ۱۰ » معرفی چند نرم افزار کاربردی برای عملیات دادهکاوی
- ۱۱ » ویژگی (Feature) یا همان بُعد (Dimension) در دادهکاوی چیست؟
- ۱۲ » بررسی چند الگوریتم یادگیری ماشین (Machine Learning)
- ۱۳ » یادگیری دستهای (Batch Learning) و یادگیری برخط (Online Learning)
- ۱۴ » یادگیری فعال (Active Learning) در یادگیری ماشین
- ۱۵ » انتخاب ویژگی (Feature Selection) چیست؟
- ۱۶ » تفاوت داده ساختاریافته (Structured) با غیرساختاریافته (Unstructured) چیست؟
- ۱۷ » منظور از متغیر وابسته (Dependent) و مستقل (Independent)
- ۱۸ » مجموعه دادههایی با ابعاد زیاد (High Dimensional)
- ۱۹ » مجموعه دادهی نامتوازن (Imbalance) چیست؟
- ۲۰ » فرآیند کریسپ (CRISP) جهت انجام پروژههای دادهکاوی
- ۲۱ » رانش یا گذار در دادهها (Data Drift)
فوق العادس
آیا با روشهای برنامه نویسی پایتون در این حوزه کار نمیکنید؟ یا فیلم آموزشی ندارید؟
بسیار سپاسگزارم از مطالب خوبتون
تاریخچه داده های نامتوازان رو لطفا بزارید