

در درسِ ویژگی یا همان بُعد چیست، به این نکته رسیدیم که در دادهکاوی و یادگیری ماشین، بسیاری از مواقع، دادهها دارای ویژگیهای مختلفی هستند که آنها را ابعاد نیز مینامند. مثلاً در مثال همان درس دیدیم که برای تعیین نوع اتومبیل، دو ویژگیِ طول و ارتفاع را در نظر گرفتیم که هر کدام از اینها یک بُعد در فضا بودند. پس مسئله در آن درس ۲بُعدی بود. اما ممکن است یک مجموعهی داده دارای ابعاد بیشتری نیز باشد که میخواهیم در مورد آن، در این درس صحبت کنیم.
فرض کنید مجموعهای از تصاویر دارید و میخواهید هر کدام از آنها را با توجه به ماهیتِ این تصاویر شناسایی کنید، به این صورت که آیا این تصویر مناسب کودکان هست یا خیر؟ اگر درس طبقهبندی چیست را خوانده باشید میدانید که این مسئله یک مسئلهی طبقهبندی است. برای اینکار بایستی یک مجموعهی تقریباً بزرگ از تصاویر را توسط یک شخصِ ناظر (supervisor) – یعنی شخصی که مناسب یا نامناسب بودن تصویر برای کودکان را متوجه میشود – برچسب بزنید. مثلاً یک تصویر را به این شخصِ ناظر بدهید و به او بگویید که این تصویر برای کودکان مناسب هست یا خیر؟ هر جوابی که او داد به عنوان برچسب برای آن تصویر قرار میگیرد و به این صورت مجموعهی آموزشی (training set) که خوراک الگوریتم طبقهبندی هست را میسازید. در واقع وظیفهی اصلیِ الگوریتم طبقهبندی، این است که از روی این تصاویرِ برچسبزده شده توسط ناظر، یادگیری را انجام دهد و به حدی یاد بگیرد که از این به بعد خود (الگوریتم بدون دخالت شخصِ ناظر) بتواند تصاویرِ جدید را برچسب بزند. شکل زیر را نگاهی بیندازید:
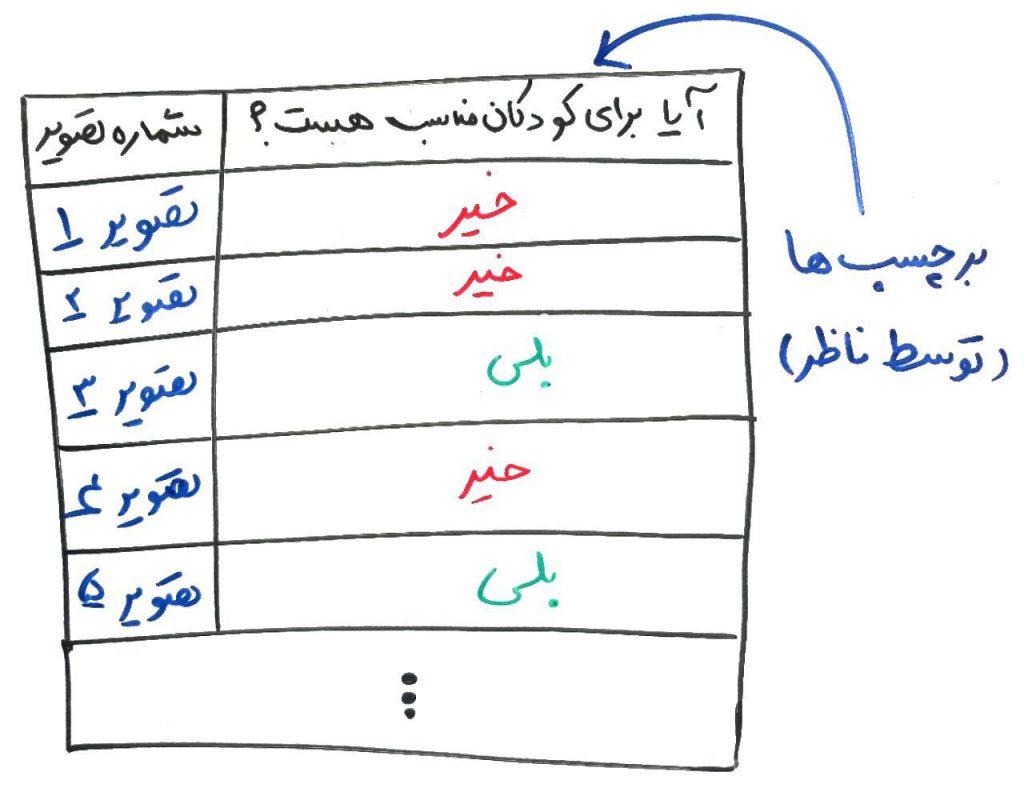
همانطور که مشاهده میکنید در این شکل، تعدادی تصویر به یک شخصِ ناظر داده شده است تا این شخص با توجه به تجربهی خود، هر کدام از تصاویر را (با توجه به مناسب بودن برای کودکان) برچسب بزند. در نهایت الگوریتمِ یادگیری ماشین بایستی از این مجموعهی داده، یادگیری را انجام دهد تا بتواند دادههای جدیدتر را بدون نیاز به شخصِ ناظر طبقهبندی (classification) کند.
میدانید که بایستی دادهها را برای کامپیوتر و الگوریتمهایی مانند الگوریتمهای طبقهبندی، آماده کرده و برای این کار بایستی دادهها به فُرمت قابل فهم برای الگوریتم تبدیل شوند. پس در مثال بالا نیاز است تا تصاویر به یک فرمتی مانند ماتریس، که خود از بردار تشکیل شده و بردار نیز از عدد تشکیل شده است تبدیل شود (درس ماتریس و بردار را خوانده باشید). به این صورت تصاویر به فُرمتِ قابل فَهم برای الگوریتم تبدیل میشوند. شکل زیر را نگاه کنید:
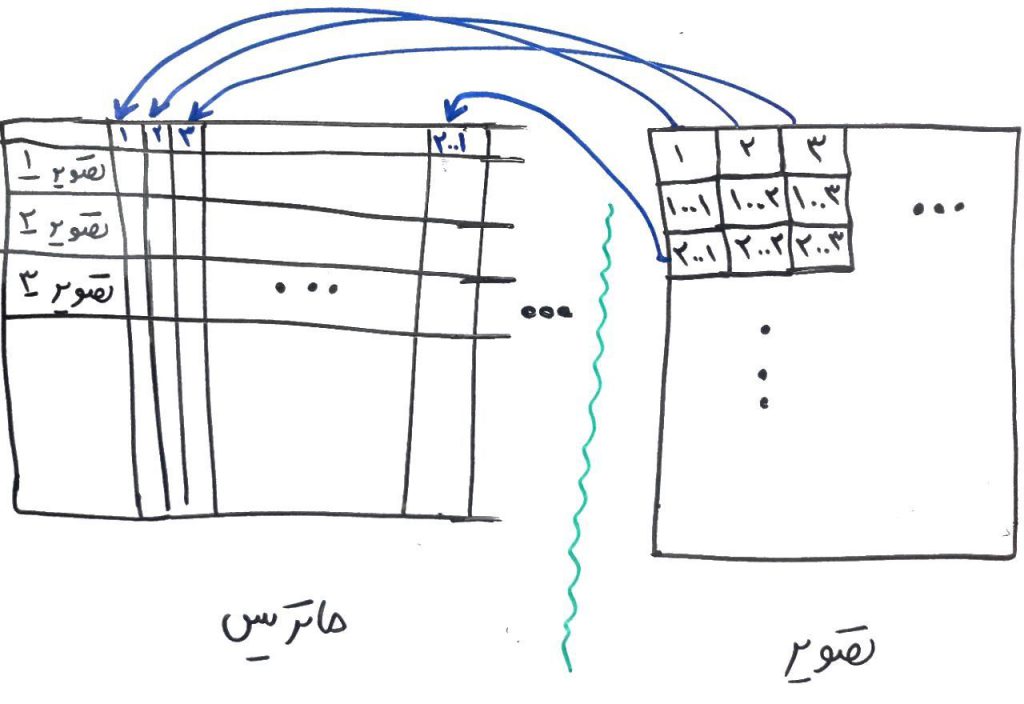
فرض کنید تصاویر سیاه و سفید هستند یعنی رنگی نیستند. در این شکل ما میخواهیم یک تصویر مانند تصویر سمت راست را به بردارهای سمت چپ تبدیل کنیم. برای اینکار هر پیکسل از تصویر یک خانه از بردار میشود و این تصاویر در کنارِ هم ماتریس مجموعهی داده را تشکیل میدهند (هر سطر از ماتریس یک تصویر است و هر ستون یک پیکسل از آن تصویر است). برای مثال ستونِ شمارهی ۱ در ماتریس بالا، نشاندهندهی پیکسل اول (از چپ بالا) برای هر تصویر است که میتواند عددی از ۰ تا ۲۵۵ بسته به روشنایی آن پیکسل در بازهی سفید تا سیاه داشته باشد (چون تصویر سیاه و سفید است) و به همین ترتیب بقیهی ستونها. پس در این ماتریس به تعداد پیکسلهای تصاویر، ستون داریم. ما این ماتریس را برای تزریق به الگوریتمهایی مانند الگوریتمهای طبقهبندی نیاز داریم. اگر درس ویژگی و بُعد چیست را خوانده باشید، متوجه میشوید که هر کدام از این ستونها یک ویژگی یا یک بُعد است. حالا به این نکته میرسیم که اگر در مثال بالا هر تصویر ۱۰۰۰ در ۱۰۰۰ پیکسل باشد یعنی مجموعاً ۱ میلیون پیکسل در هر تصویر موجود است. این یعنی که برای ساخت ماتریسِ ویژگی (مانند ماتریسِ ساختهشده در شکل بالا) نیاز به ۱ میلیون ستون (بُعد) داریم. به این دست از مسائل دادههایی با ابعاد بالا گفته میشود که طبیعتاً نمیتوان آنها را بر روی محورهای دوبُعدی یا سهبُعدی رسم کرد.
این مثال بالا، یک نمونه از دادههایی با ابعاد زیاد یا همان high dimensional data set بود که در مباحثِ مختلفِ دادهکاوی و یادگیریِ ماشین برخوردهای متفاوتی با این دست از دادهها انجام میدهند.

- ۱ » دادهکاوی (Data mining) چیست؟
- ۲ » یادگیری ماشین (Machine Learning) چیست؟
- ۳ » تفاوت هوش مصنوعی، یادگیری ماشین، دادهکاوی، یادگیری عمیق و علم داده
- ۴ » طبقهبندی (Classification) چیست؟
- ۵ » خوشهبندی (Clustering) چیست؟
- ۶ » تفاوت طبقهبندی (Classification) و خوشهبندی (Clustering)
- ۷ » منظور از دادههای آموزشی (Training Sets) در طبقهبندی چیست؟
- ۸ » سیستم توصیه گر (Recommendation System) چیست؟
- ۹ » کاربرد دادهکاوی و یادگیری ماشین در پردازش متن (Text Processing)
- ۱۰ » معرفی چند نرم افزار کاربردی برای عملیات دادهکاوی
- ۱۱ » ویژگی (Feature) یا همان بُعد (Dimension) در دادهکاوی چیست؟
- ۱۲ » بررسی چند الگوریتم یادگیری ماشین (Machine Learning)
- ۱۳ » یادگیری دستهای (Batch Learning) و یادگیری برخط (Online Learning)
- ۱۴ » یادگیری فعال (Active Learning) در یادگیری ماشین
- ۱۵ » انتخاب ویژگی (Feature Selection) چیست؟
- ۱۶ » تفاوت داده ساختاریافته (Structured) با غیرساختاریافته (Unstructured) چیست؟
- ۱۷ » منظور از متغیر وابسته (Dependent) و مستقل (Independent)
- ۱۸ » مجموعه دادههایی با ابعاد زیاد (High Dimensional)
- ۱۹ » مجموعه دادهی نامتوازن (Imbalance) چیست؟
- ۲۰ » فرآیند کریسپ (CRISP) جهت انجام پروژههای دادهکاوی
- ۲۱ » رانش یا گذار در دادهها (Data Drift)
توضیحاتتون خیلی خوبه.. لطفا ادامش رو هم بزارید. مرسی
با سلام و احترام
تشکر از شما
عالی بود سپاس
منتظر ادامه اش هستم.
ساده وروان
ممنون
وبلاگتون محشره. زبان تدریستون عالی
هر یازده مطلب رو پشت سر هم خوندم. خیلی نسبت به این مطلب و شبکه های عصبی روشن شدم. تفهیم آسان مطلب پیچیده مهارت شماست
سلام
وقتی من داده هایی داشته باشم که مثلا ۴ بعدی باشه چطوری با خوشه بندی طیفی آن را پیدا سازی نمایم؟
لطفا کامل توضیح دهید.
تشکر.