

در بسیاری از مراجعِ دادهکاوی، مخصوصاً آنهایی که پایهی آماریِ بیشتری داشته باشند، از عباراتی مانندِ متغیر وابسته و متغیرِ غیر وابسته استفاده میکنند. در این درس میخواهیم به این دو مفهوم بپردازیم، کاربرد و تفاوتِ این دو دسته متغیر را در حوزهی علوم داده و یادگیری ماشین درک کنیم.
از دروس گذشته، شکلی مانندِ شکلِ زیر را به یاد بیاورید:
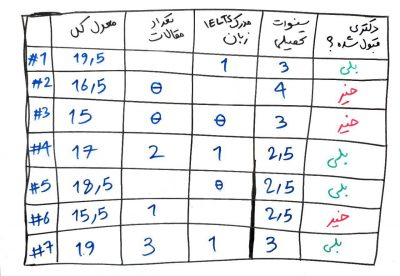
این یک مجموعهی داده (دیتاست) شامل ۷ دانشجو بود که هر کدام ۴ ویژگی داشتند. میخواستیم از روی این ۴ ویژگی، یادگیری را انجام دهیم و بعد از یادگیری توسط الگوریتم، پیشبینی کنیم که یک دانشجوی جدید، میتواند دکتری قبول شود یا خیر. در اینجا دو دسته داده داریم. دادههایی که ویژگیهای ما را میسازند و عموماً به صورتِ X نمایش داده میشوند. در مثالِ بالا چهار ستونِ اول (معدل کل، تعداد مقالات، مدرک IELTS زیان و سنواتِ تحصیلی) دادههایی هستند که به متغیر مستقل (independent) معروف هستند. چون وابسته به متغیرهای دیگری نیستند و در واقع مستقل از متغیرهای دیگر هستند.
اما ستونِ آخر، ستون برچسبها هستند که معمولاً با y نمایش میدهند، و به متغیرِ وابسته (dependent) معروف هستند. در اینجا ستونِ دکتری قبول شده؟ یک متغیر وابسته است. زیرا ما از ۴ ستونِ قبلی استنتاج میکنیم که آیا شخصی با این ویژگیها میتواند دکتری قبول شود یا خیر. برای مثال، شخص شماره #۱ با معدلِ کل ۱۹/۵، دارای مدرک زبان و ۳ سال سنوات تحصیلی توانسته دکتری قبول شود (حتماً توجه دارید که در موردِ شخصِ شمارهی ۱ مقدارِ ویژگیِ تعداد مقالات، خالی بود، یعنی برای این شخص دادهی تعداد مقاله مفقود شده است. همانطور که میبینید، این متغیرِ آخر (دکتری قبول شده یا خیر؟) وابسته به مقادیر مستقل یعنی همان Xها است. برای مثال در نمونهی بالا ما میخواهیم از روی متغیر مستقل (X)، متغیر وابسته (y) را پیشبینی کنیم.
از این مجموعه دادههای مستقل و وابسته در عملیات یادگیری ماشین، طبقهبندی و رگرسیون بسیار زیاد استفاده میشود.

- ۱ » دادهکاوی (Data mining) چیست؟
- ۲ » یادگیری ماشین (Machine Learning) چیست؟
- ۳ » تفاوت هوش مصنوعی، یادگیری ماشین، دادهکاوی، یادگیری عمیق و علم داده
- ۴ » طبقهبندی (Classification) چیست؟
- ۵ » خوشهبندی (Clustering) چیست؟
- ۶ » تفاوت طبقهبندی (Classification) و خوشهبندی (Clustering)
- ۷ » منظور از دادههای آموزشی (Training Sets) در طبقهبندی چیست؟
- ۸ » سیستم توصیه گر (Recommendation System) چیست؟
- ۹ » کاربرد دادهکاوی و یادگیری ماشین در پردازش متن (Text Processing)
- ۱۰ » معرفی چند نرم افزار کاربردی برای عملیات دادهکاوی
- ۱۱ » ویژگی (Feature) یا همان بُعد (Dimension) در دادهکاوی چیست؟
- ۱۲ » بررسی چند الگوریتم یادگیری ماشین (Machine Learning)
- ۱۳ » یادگیری دستهای (Batch Learning) و یادگیری برخط (Online Learning)
- ۱۴ » یادگیری فعال (Active Learning) در یادگیری ماشین
- ۱۵ » انتخاب ویژگی (Feature Selection) چیست؟
- ۱۶ » تفاوت داده ساختاریافته (Structured) با غیرساختاریافته (Unstructured) چیست؟
- ۱۷ » منظور از متغیر وابسته (Dependent) و مستقل (Independent)
- ۱۸ » مجموعه دادههایی با ابعاد زیاد (High Dimensional)
- ۱۹ » مجموعه دادهی نامتوازن (Imbalance) چیست؟
- ۲۰ » فرآیند کریسپ (CRISP) جهت انجام پروژههای دادهکاوی
- ۲۱ » رانش یا گذار در دادهها (Data Drift)
salam. besyar shafaf va ba zaban sade gofte shod. Thank you
سلام از روی اتفاق با سایت شما آشنا شده و حظ وافر بردم و منتظر ادامه دوره هستم. درود بر شما
سلام بسیار بسیار مطالب ساده و
روان و ارزشمند بود
بسیار عالی
سلام
بینهایت عالی با ارزوی موفقیت های بیشتر برای شما
با سلام
بسیار بسیار ساده و مفهومی توضیح داده شده. برایتان آرزوی موفقیت و سربلندی دارم.