

توزیع آماری به پراکندگی دادهها و فراوانیِ هر کدام از مقادیر آنها میگویند. با استفاده از توزیعِ آماریِ یک متغیر، میتوانیم به نحوهی پراکندگی و احتمال هر کدام از قسمتهای آن متغیر (در بازهی پراکندگی) پی ببریم.
فرض کنید مجموعهی دادهی زیر، مراجعین یک پزشک را با دو متغیرِ «سن (Age)» و «تشخیص بیماری (Illness)» در خود جای داده است:
در مجموعهی دادهی بالا هر سطر یک نمونه (مُراجع) است. اگر بخواهیم توزیع دادهها را برای متغیرِ سن (Age) نمایش دهیم، نموداری شبیه به شکل زیر ساخته میشود:
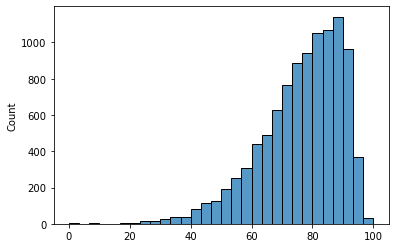
شکل بالا یک نمودار فراوانی (هیستوگرام) برای متغیرِ سن (Age) است. این نمودار، توزیعِ متغیر سن (Age) را نمایش داده و نشان میدهد که در کدام یک از بازههای سنی، فراوانی و احتمال بیشتری داشتهایم. برای مثال در نمودار بالا بازهی سن که بین ۰ تا ۱۰۰ سال بوده است را به ۳۰ قسمت مساوی تقسیم کرده (محور x) و تعدادِ تکرار (فرکانس – frequency) هر کدام از قسمتها را در محور عمودی (محور y) نمایش دادهایم. هر کدام از این ۳۰ قسمت، به اندازهی ۳/۳۳ بازهی سن را نمایش میدهند. مثلاً در بازهی سن ۰ تا ۳/۳۳ تعداد خیلی کمی نمونه (مُراجع) داریم ولی در بازهی سنِ ۸۰ تا ۸۳/۳۳ بیش از هزار نفر نمونه (مُراجع) در مجموعهی داده وجود دارد. هر چقدر تعداد قسمتها بیشتر باشد، نمودار دقیقتر میشود. برای مثال اگر متغیر سن (Age) را به ۵۰ قسمت تقسیم کنیم هر قسمت نشان دهندهی تعداد تکرار برای بازهی ۲ سال است (چون کل نمونهها از ۰ تا ۱۰۰ سال سن دارند).
توزیع دادهها همچنین میتواند به صورت آرایه یا بردار ساخته شود. چیزی مانند آرایهی زیر برای مجموعهی دادهی بالا:
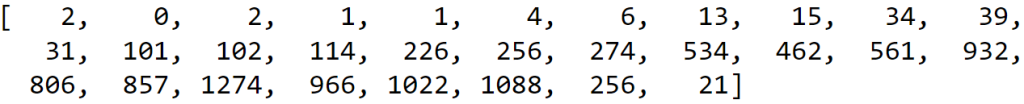
در هر کدام از عناصرِ آرایهی بالا، تعدادِ تکرارِ نمونهها (فرکانس) در یک قسمت از بازهی ۳۰ قسمتی را نمایش داده است. در واقع آرایهی بالا، یک حالتِ عددی برای نمودار رسم شده در شکلِ بالاتر است.
در مثال گفته شدهی قبل، دادهها در ستون «سن (Age)» عددی یا همان numerical بودند. اگر بخواهیم توزیع دادهها را برای حالت غیر عددی یا همان categorical به دست بیاوریم نیز به همین ترتیب عمل میکنیم. برای مثال توزیعِ دادهها برای بیمار بودن (۱) یا سالم بودن (۰) را از مجموعهی دادهی بالا در نظر بگیرید. این توزیع چیزی شبیه به شکل زیر میشود:

به این معنی که در مجموعهی دادهی بالا تعداد ۵۰۲۵ نمونه مُراجعِ بیمار (۰) و تعداد ۴۹۷۵ نمونه مُراجع سالم (۱) داریم. همین خروجی را میتوان به صورت نمودار رسم کرد.
از توزیع دادههای یک متغیر در یادگیری ماشین و دادهکاوی استفادهی متعددی میشود که در دروس آینده به این کاربردها خواهیم پرداخت. همچنین در دورهی توزیعهای احتمالی در مورد انواع این توزیعها و کاربرد هر یک صحبت کردهایم.

- ۱ » تحلیل اکتشافی دادهها (Exploratory Data Analysis) چیست؟
- ۲ » انواع مختلف دادهها در دادهکاوی کدامند؟
- ۳ » منظور از دادههای مستطیلی (Rectangular Data) چیست؟
- ۴ » داده پرت (Outlier) در دادهکاوی چیست؟
- ۵ » تخمین مکان دادهها (Estimation Of Location) چیست و انواع مختلف آن کدامند؟
- ۶ » تخمین تنوع و پراکندگی (Estimation Of Variability) و انواع مختلف آن
- ۷ » چارک (Quartile) و IQR در دادهها و کاربردهای آن
- ۸ » چولگی (Skewness) در دادهها
- ۹ » کشیدگی یا برجستگی (kurtosis) در دادهها
- ۱۰ » چگونه با EDA در دادهها اکتشاف کنیم؟
- ۱۱ » نمونهگیری آماری و محاسبهی حداقل تعداد نمونه (Min Sample Size)
- ۱۲ » توزیعهای آماری (Statistical Distributions)
- ۱۳ » فاصلهی آماری (Statistical Distance) و کاربردهای آن
- ۱۴ » واگرایی کولبک-لیبلر (Kullback-Leibler Divergence) و کاربرد آن در فاصلهی آماری
- ۱۵ » فاصلهی جنسون-شنون (Jenson-Shannon) برای مقایسهی توزیعهای آماری