

فرض کنید مدیرِ یک اداره هستید و در روز عدهی کثیری از مراجعهکنندگان به ادارهی شما مراجعه میکنند. در این مراجعه به هر فرد یک فُرمِ دریافت مشخصات داده میشود و از او خواسته میشود تا اطلاعاتی مانند نام، جنسیت، سن، کدپستی، نامِ پدر، شمارهی شناسنامه، آدرس منزل، تعداد دفعات مراجعهی قبلی، و دلیلِ مراجعهی خود را در آن فُرم بنویسد تا بعداً عملیاتِ پردازشی بر روی دادهها انجام شود (مثلاً با عملیات متنکاوی-text mining- متوجه شوید که معمولاً مراجعهکنندگان به چه دلایلی به اداره مراجعه میکنند یا اینکه معمولاً این مراجعهکنندگان ساکن کدام محدودهی شهر-با توجه به کدپستی- هستند). با این تفاسیر آیا تضمین میکنید که تمامِ مراجعهکنندگان، اطلاعاتِ خود را کامل وارد کنند؟ مثلاً اگر شخصی کدپستیِ خود را فراموش کرده باشد چه؟ در اینجا طبیعتاً دادهها ناقص است و در واقع بعضی از دادهها وجود ندارند. به این دست از دادهها، missing values یا دادههای گم شده یا دادههای مفقود میگویند که موردِ بحثِ این درس است.
فقدانِ دادهها معمولاً یکی از مسائلِ اصلی در حوزهی جمعآوری داده است. برای همین راهحلهای فراوانی برای غلبه بر این مشکل به وجود آمده است. یکی از راهحلها غلبه بر دادهی گم شده با پر کردنِ آن توسط دادهی واقعی است. مثلاً در مثالِ بالا به افرادی که اطلاعاتِ ناقص گذاشتهاند تلفن بزنید و کدپستیِ آنها را به صورتِ دقیق بپرسید. ولی معمولاً روشهای غیر از این هم وجود دارد. به شکل زیر نگاه کنید:
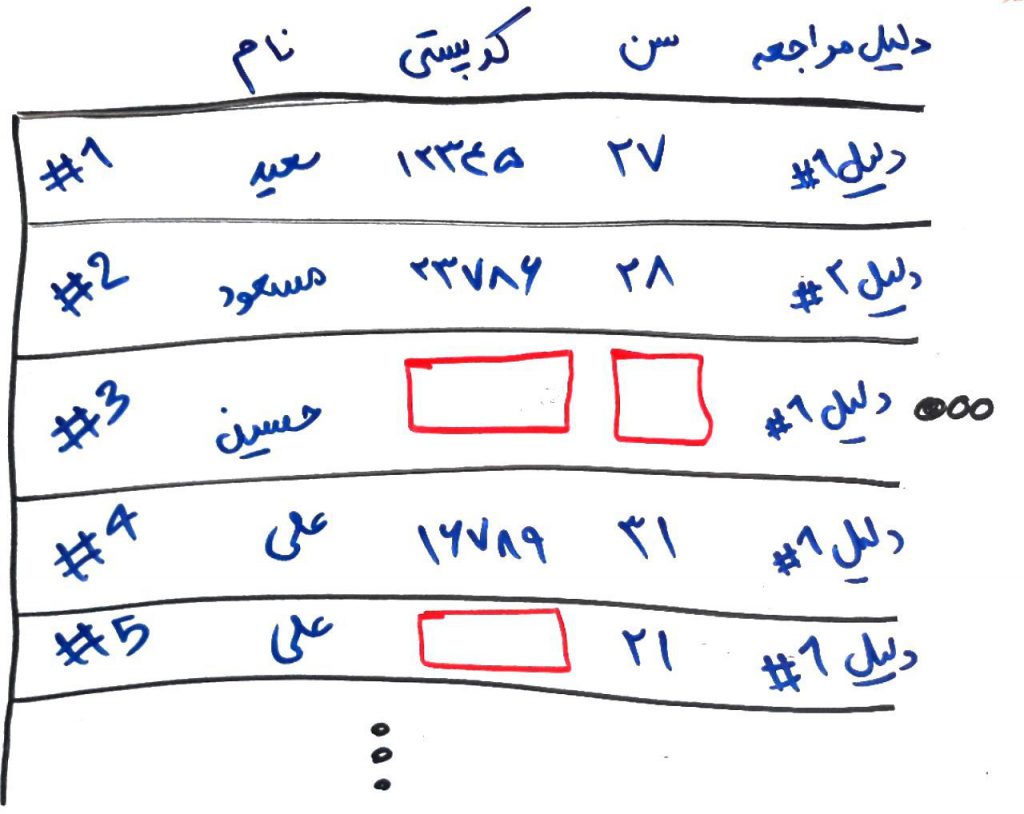
تصویر بالا یک قسمت از دادههای آن فرم را نمایش میدهد. در اینجا ستونِ کدِپستی برای مراجعهکنندگانِ ۳ و ۵ خالی است. همچنین ستونِ سن، برای مراجعهکنندهی ۳ فاقدِ داده است. در ادامه، روشهایی را با هم مرور میکنیم که میتوانند برای مقابله با این دادههای مفقود شده، کمک کنند.
یکی از روشها این است که مراجعهکنندگانِ ۳ و ۵ را از بین دادهها حذف کنیم. اینکار باعث میشود که معادلاتِ آماری در دادهها (مخصوصاً هنگامی که دادههای فراوان داریم) تقریباً مانندِ قبل بماند و در واقع حذفِ چند رکورد، عموماً در این معادلات خللی وارد نمیکند. ولی خوب، به نوعی پاک کردن صورت مسئله است.
راهحلِ دیگر این است که ستونِ کدپستی را از بینِ دادهها حذف کنیم! که البته در این مثال کاری منطقی به نظر نمیآید.
در بعضی از مواقع میتوان میانگین (mean) یا میانهی (median) اعدادِ موجودِ رکوردهای دیگر را برای یک ستونِ خاص محاسبه کرده و به جای مقادیرِ مفقود شده قرار داد. مثلاً اگر سنِ فردی دارای مقدارِ مفقود شده بود، میتوانیم میانگینِ سنِ افرادی که ستونِ سن، برای آنها وارد شده است را حساب کنیم و به جای این مقادیر مفقود شده برای مراجعهکنندگان دیگر قرار دهیم. در مثالِ بالا برای ستونِ کدِپستی این کار منطقی به نظر نمیرسد، چون مقدارِ کدِپستی مقداری نیست که بتوان میانگینِ آن را محاسبه کرد و میانگینِ آن بیمعنی به نظر میرسد.
همچنین میتوانیم یک مقدار ثابت را در نظر گرفته و به جای مقادیر مفقود شده قرار دهیم. مثلا برای سن، عددی مانند ۲۵ را برای اشخاصی که سنِ آنها وارد نشده است قرار دهیم. یا کدپستی را یک کد پستی واقع در مرکز شهر در نظر بگیریم.
این روشها کاملاً بدیهی به نظر میرسند و احتمالاً میتوانید روشهای دیگری را نیز با کمی تعقل ابدا کنید. اما اجازه بدهید یک روشِ دیگر که کمی با روشهای فوق متفاوت هست را با یکدیگر نگاهی بیندازیم.
الگوریتمِ KNN را از دورهی طبقهبندی به یاد بیاورید. این الگوریتم به دنبالِ نزدیکترین همسایه در بین نمونههای دیگر در دادههای موجود میگشت. برای حلِ مشکلِ دادههای مفقود نیز میتوان از این روش استفاده کرد. در همان مثالِ بالا، فرض کنید مراجعه کنندهی شمارهی ۳ را، که مقدار سنِ خود را وارد نکرده است، در نظر داریم. با توجه به ویژگیهای دیگرِ این مراجعهکننده (مثلاً علت مراجعه، جنسیت، تعداد دفعات مراجعهی قبلی و…) به دنبال نزدیکترین فرد در بینِ مراجعهکنندگانی که فرمِ خود را کامل پر کردهاند، میگردیم. فرض کنید مراجعهکنندهی شمارهی ۱، نزدیکترین فرد به این شخص باشد (بر طبق الگوریتم KNN و فاصلهی اقلیدسی). حال سنِ مراجعهکنندهی شمارهی ۱، یعنی ۲۷سال را برای مراجعهکنندهی شمارهی ۳ نیز قرار میدهیم. در واقع در اینجا با استفاده از روشِ الگوریتم نزدیکترین همسایه (KNN) توانستیم سنِ مراجعهکنندهی شمارهی ۳ را تخمین بزنیم.
روشهای متعدد و گستردهای در زمینهی مقابله با دادههای مفقود شده وجود دارد که به صورتِ دقیقتر در دورهای جداگانه به آن خواهیم پرداخت.

- ۱ » پیش پردازش دادهها (Data Preprocessing) چیست؟
- ۲ » بررسی یکپارچگی دادهها (Data Integrity)
- ۳ » نرمال کردن دادهها (Data Normalization) و انواع آن
- ۴ » تبدیل دادهها (Data Transformation) به فُرمت قالب فهم برای الگوریتم دادهکاوی
- ۵ » دادههای گمشده (Missing Values) و راهکارهای مقابله با آنها
- ۶ » تشخیص دادههای پرت و دارای نویز (Noise) و راهکار مقابله با آنها
- ۷ » انتخاب ویژگی (Feature Section) و کاهش ابعاد
- ۸ » انتخاب نمونه (Instance Selection) در پیش پردازش دادهها
بسیار عالی هست آموزش هاتون.
فقط حیف که دوره این درس هنوز کامل نشده.
با تشکر.
درون یابی و برون یابی هم کمک خوبی محسوب میشوند