

معمولاً در بحثِ پردازش دادهها و دادهکاوی، یکی از محدودیتها، محدودیت در منابع سخت افزاری است. برای مثال فرض کنید، ۵۰ گیگابایت داده در اختیار داریم ولی مقدار حافظهی موقتِ (RAM) موجود، ۴ گیگابایت است. یکی از راهکارها، برای حل این دست مسائل، کاهش دادن دادهها است. در درسِ قبل دیدیم که چگونه با حذفِ یک ویژگی (یک بُعد)، حجمِ دادهها کاهش پیدا میکند. در این درس میخواهیم ببینیم که چگونه به جای حذفِ یک ویژگی، نمونههای مختلف رامیتوان از بین دادهها کنار گذاشت.
مثال درسِ قبل را به یاد بیاورید:
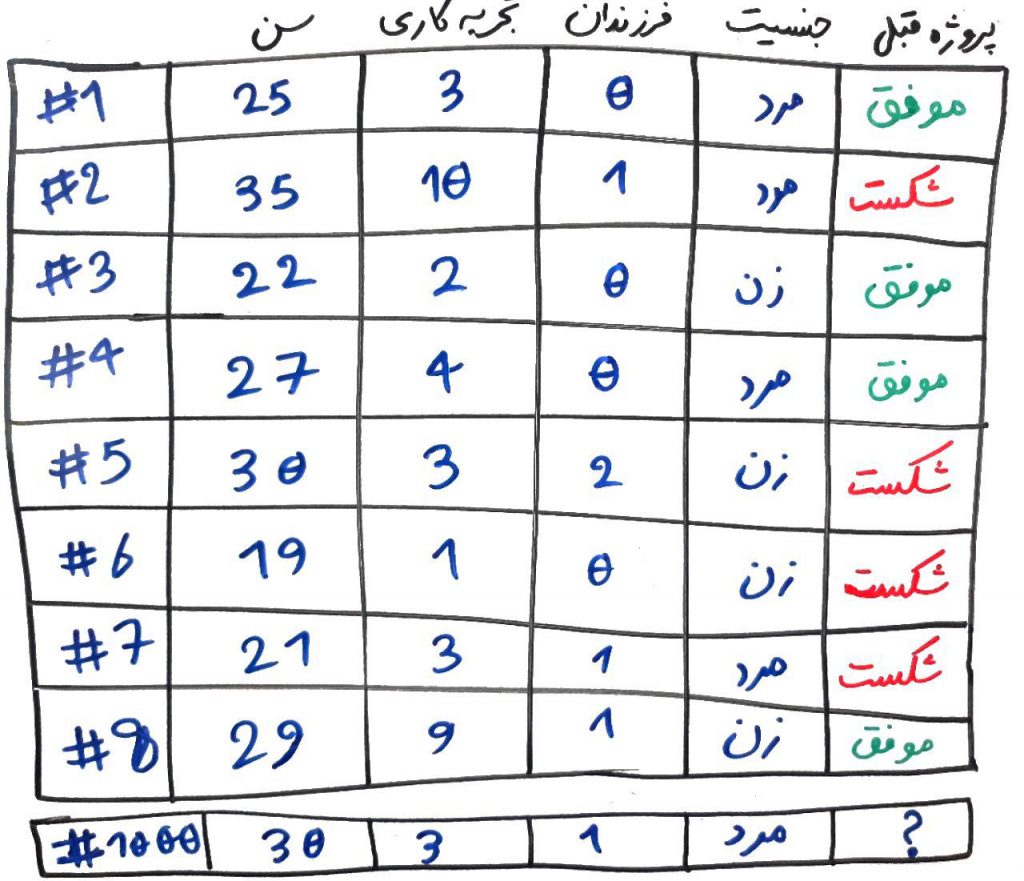
در این مثال، ما ۸ نمونه کارمند داریم که هر کدام ۴ویژگی دارند و میخواهیم با توجه به این ۴ ویژگی، یاد بگیریم که معمولاً یک شخص با چه ویژگیهایی میتواند یک پروژه را به موفقیت برساند (که این مثالی از طبقهبندی بود). ولی در میانِ دادهها، برخی از نمونهها هستند که اطلاعاتِ مفیدی برای الگوریتمِ طبقهبندی فراهم نمیآورند. الگوریتمهای انتخابِ نمونه یا همان instance selection، میتوانند این نمونهها را شناسایی کرده و آنها را از میانِ دادهها حذف کنند.
با اینکار سرعت در عملیاتِ یادگیریِ ماشین و طبقهبندی بیشتر میشود ولی دقتِ طبقهبندی تقریباً مانندِ قبل باقی میماند یا ممکن است کمتر شود. توجه کنید که الگوریتمهای طبقهبندی معمولاً خطاهای معقولی دارند و عملیاتِ کاهشِ نمونه، بایستی با ثابت نگهداشتن خطای یک الگوریتمِ طبقهبندی، تعداد نمونهها را کاهش دهد. سعی داریم در دورهای جداگانه به بررسی الگوریتمهای کاهش نمونه (instance selection) بپردازیم.

- ۱ » پیش پردازش دادهها (Data Preprocessing) چیست؟
- ۲ » بررسی یکپارچگی دادهها (Data Integrity)
- ۳ » نرمال کردن دادهها (Data Normalization) و انواع آن
- ۴ » تبدیل دادهها (Data Transformation) به فُرمت قالب فهم برای الگوریتم دادهکاوی
- ۵ » دادههای گمشده (Missing Values) و راهکارهای مقابله با آنها
- ۶ » تشخیص دادههای پرت و دارای نویز (Noise) و راهکار مقابله با آنها
- ۷ » انتخاب ویژگی (Feature Section) و کاهش ابعاد
- ۸ » انتخاب نمونه (Instance Selection) در پیش پردازش دادهها
سلام
عالی بود.چیزی فراتر از عالی.
تشکر
خدا قوت
یا حق
یا علی(ع)مدد
بهتر از بهترین.
واقعا ممنونم
خیلی خیلی خوب بود ممنون از شما
بی نهایت ممنون
بسیار عالی و روان توضیح میدید و با مثال های ساده به درک بهتر کمک میکنید.
یک دنیا ممنون
سلام خيلي عالي بود،ممنون از توضيحاتتون.
دمتون گرم بسیار عالی.
مطالبتون عالی بود.
توضیح خلاصه و مفید ضمن همراه بودن کامل بودن + بیان شیوا با مثال های ساده
خداقوت
ممنون. فقط ممکنه بفرمایید چه راههایی برای شناسایی نویز وجود داره؟
عالی، روان و علمی توضیح میدید
خدا خیرتون بده استاد