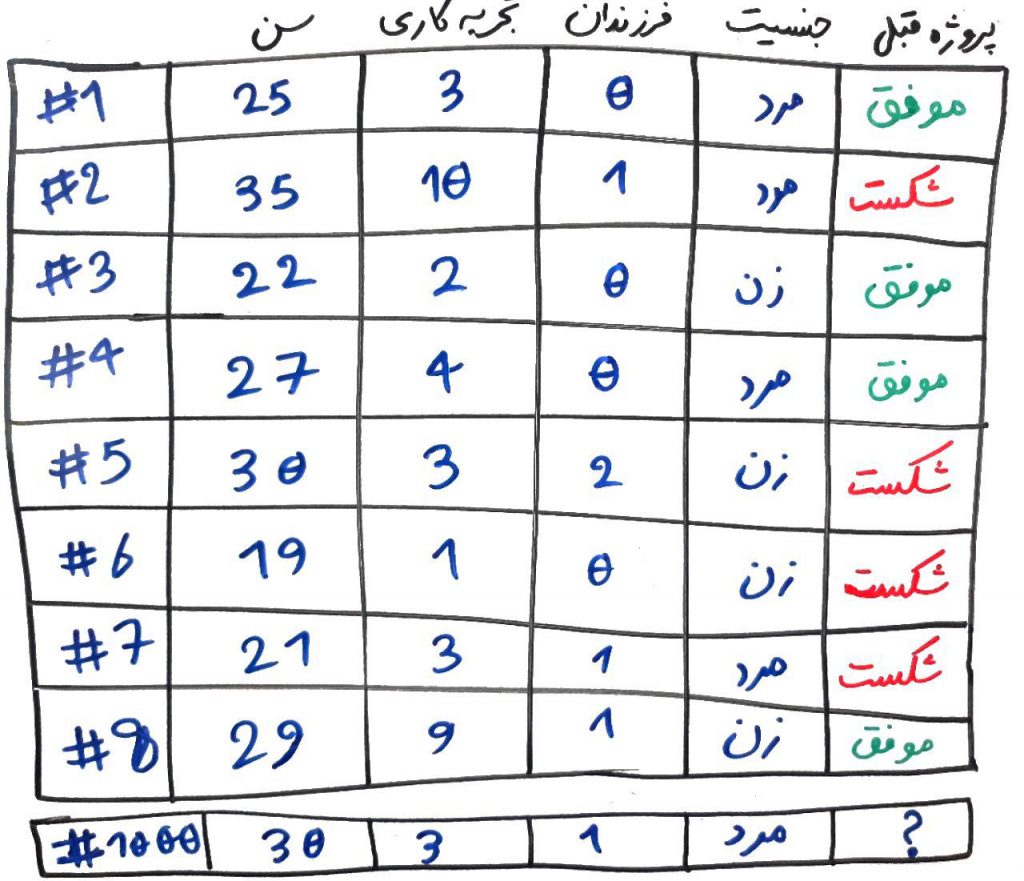
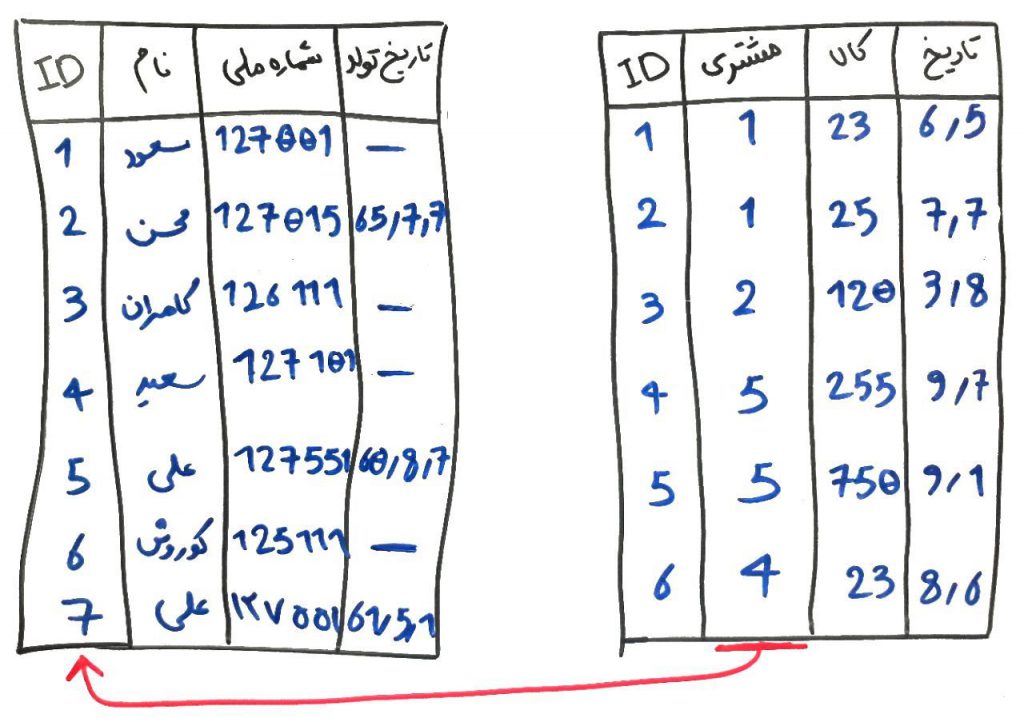
معمولاً در بحثِ پردازش دادهها و دادهکاوی، یکی از محدودیتها، محدودیت در منابع سخت افزاری است. برای مثال فرض کنید، ۵۰ گیگابایت داده در اختیار داریم ولی مقدار حافظهی موقتِ (RAM) موجود، ۴ گیگابایت است. یکی از راهکارها، برای حل این دست مسائل، کاهش دادن دادهها است. در درسِ قبل دیدیم که چگونه با حذفِ یک ویژگی (یک بُعد)، حجمِ دادهها کاهش پیدا میکند. در این درس میخواهیم ببینیم که چگونه به جای حذفِ یک ویژگی، نمونههای مختلف رامیتوان از بین دادهها کنار گذاشت.
ادامه خواندن “انتخاب نمونه (Instance Selection) در پیش پردازش دادهها”