

دادههای پرت و دادههایی که دارای نویز (noise) هستند، در بسیاری از مجموعهها، دیده میشوند. فرض کنید شما مدیرِ یک وبسایتِ فروشگاهی هستید و میخواهید سنِ کاربران خود را تحلیل کنید. مثلاً اینکه افراد در بازهی سنیِ مختلف، بیشتر به کدام محصولات تمایل نشان میدهند. برای اینکار در هنگام خرید، سنِ خریدار را از او دریافت میکنید. آیا مطمئن هستید که افراد معمولاً سنِ خود را در بازهی ۰ تا ۱۰۰ سال وارد میکنند؟ برای مثال شخصی ممکن است سهواً سنِ خود را به جای ۲۵ سال، ۲۵۰ سال درج کند و یا شخصی به جای اینکه سن خود را درج کند، سهواً سالِ تولد خود را وارد نماید! به این دست از دادهها که معمولاً با بقیهی دادهها ناسازگار هستند دادههای پرت (outliers) میگویند و مجموعهی داده را دارای نویز (noise) میدانند. در این درس میخواهیم ببینیم چه راهکارهایی برای مقابله با این دست از دادهها وجود دارد.
نویزها که به دادههای غیرطبیعی (anomalies) نیز شهرت دارند، باعث خراب شدنِ آمارها و دادههای مجموعهی داده میشوند. برای مثال فرض کنید سنِ افرادِ مختلف از آنها دریافت کرده و در جدولی مانندِ جدولِ زیر قرار دادهاید:
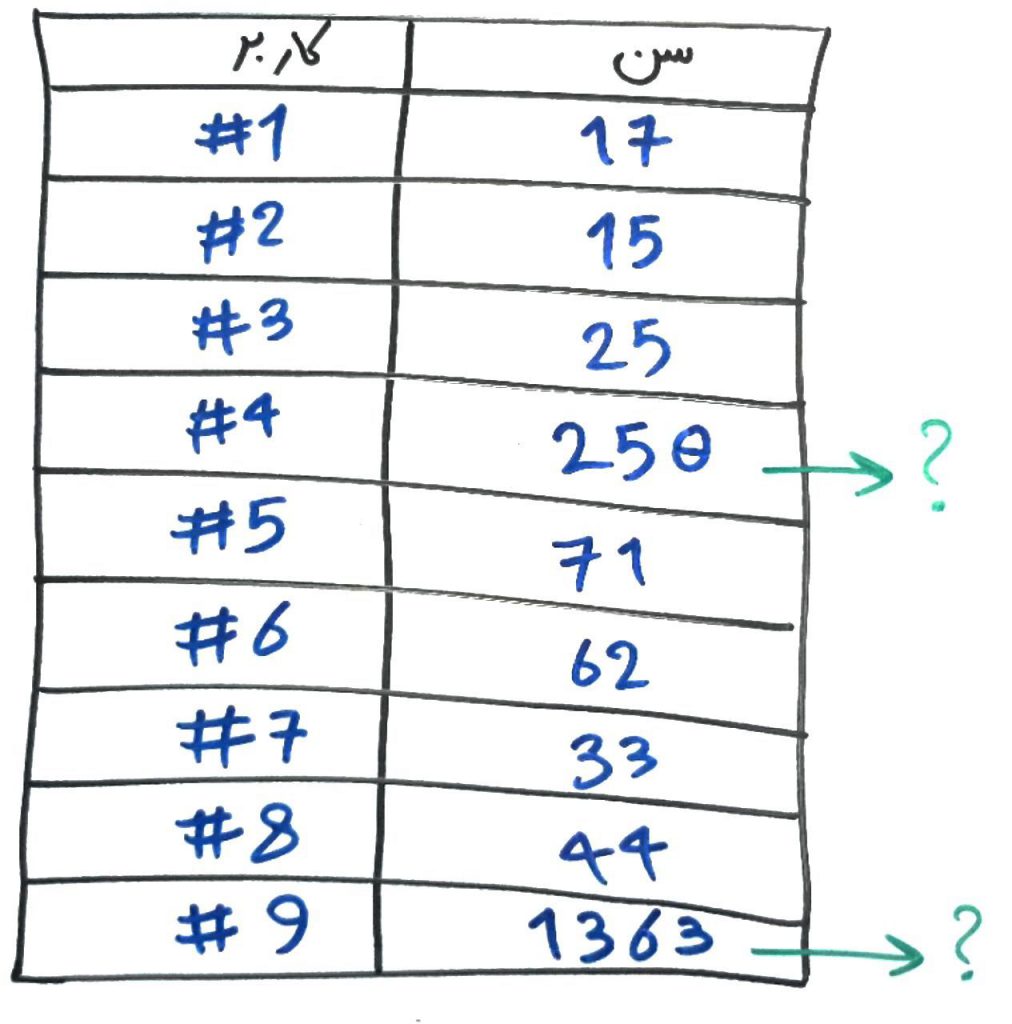
همانطور که میبینید، کاربرانِ شمارهی ۴ و ۹ دادههایی غیر طبیعی در ستون سن دارند. مثلاً کاربرِ شمارهی ۹، سهواً تاریخِ تولدِ خود را وارد کرده است و کاربرِ شمارهی ۴ نیز، به اشتباه یک صفرِ اضافی برای عددِ سنِ خود درج کرده. پس به سادگی میتوان تشخیص داد که این مجموعهی داده برای مقدارِ سن دارای دادههای پرت است.
روشهای حذف دادههای دارای نویز زیاد است و در این درس به چند روشِ ساده و کاربردی در شناسایی و حذف نویز خواهیم پرداخت. یکی از این روشها حذفِ مقادیر بالا و پایین دادهها به تعداد مشخص است. برای مثال در همین جدول بالا، میتوانیم مقادیری که کمتر از ۱۰ و یا بیشتر از ۱۰۰ هستند را حذف کنیم و یا مقادیری که در بازهی بین ۱۰ تا ۱۰۰ قرار ندارد را با میانگینِ سنهای باقیمانده جایگزین کنیم. با اینکار دادهها در یک بازهی مشخص و معقول قرار میگیرند. پس در مثال بالا، میتوانیم کاربران ۴ و ۹ را حذف کنیم و یا مقدار سن را برای آنها برابر ۳۸ که میانگین سنهای باقیمانده افراد است، قرار میدهیم.
البته در بعضی از مواقع ما به دنبال پیدا کردنِ نویزها هستیم تا دادهها را با توجه به مقادیرِ غیرطبیعی (anomalies) تحلیل کنیم. مثلاً میخواهیم در یک سری تراکنشهای بانکی، آن دسته از تراکنشهایی که رفتارِ غیرِ عادی داشتند را کشف کرده و به تخلفهای یک فرد در بانک رسیدگی کنیم. اگر درسِ خوشهبندیِ DBSCAN را خوانده باشید متوجه میشوید که این الگوریتم یکی از الگوریتمهایی است که میتواند دادههای پَرت را تشخیص دهد. در واقع DBSCAN را هم میتوان برای خوشهبندی مورد استفاده قرار داد و هم میتوان از آن به عنوانِ یک الگوریتمْ جهتِ تشخیص دادههای پرت استفاده کرد. همچنین روشی به عنوان SVM تک کلاسه (one class SVM) موجود است که میتواند دادههای پرت را تشخیص دهد.
اما ممکن است در بعضی از مواقع، کلاً یک ویژگی (یک بُعد) پَرت باشد (با ویژگی و بُعد در درس ویژگی چیست آشنا شدید). مثالِ زیر را از درسِ درخت تصمیم در نظر بگیرید:
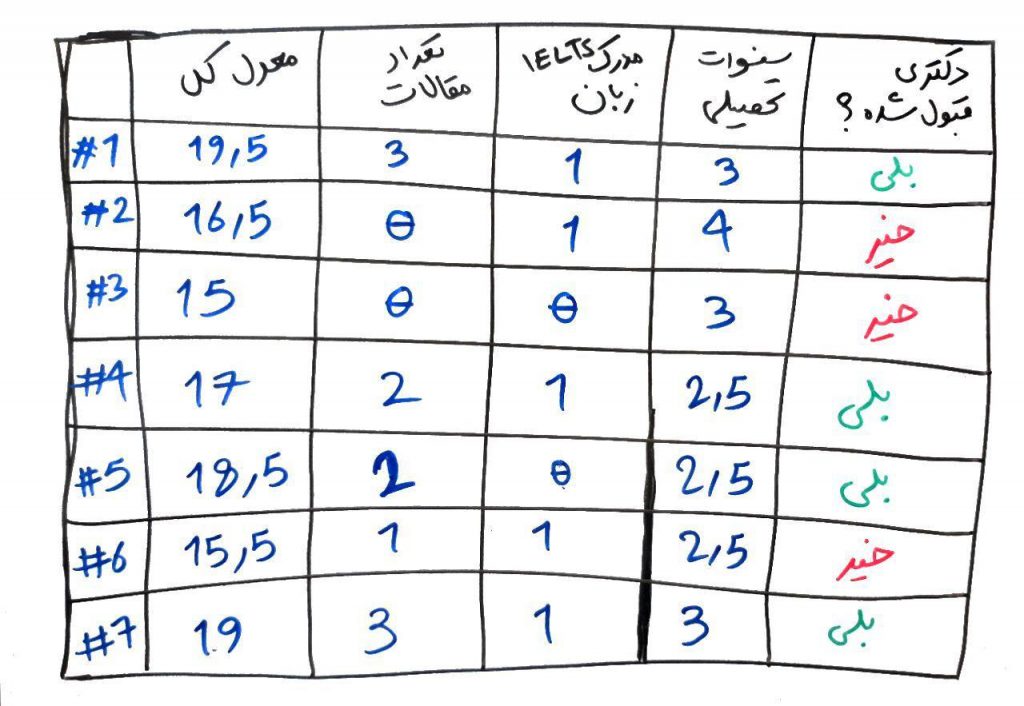
در این مجموعهی داده، یک رئیس دانشکده میخواهد بر اساسِ ویژگیهای دانشجویان و سابقهی دانشجویانِ گذشته، به این نتیجه برسد که کدام یک از دانشجوهای جدید، میتوانند در آزمون دکتر قبول شوند. همانطور که مشاهده میکنید، ویژگیهایی مانندِ معدلِ کل، تعداد مقالات، مدرک زبان IELT و سنوات تحصیلی در تشخیص و ساختِ مدل جهت پیشبینی دادههای آینده، کاربرد دارند. حال فرض کنید یک ویژگیِ دیگر مانندِ جنسیت به ویژگیهای بالا اضافه شده باشد. آیا این ویژگی میتواند در تشخیصِ اینکه شخصی دکتری قبول شود یا خیر موثر باشد؟ فرض کنیم جواب منفیست، یعنی ویژگیِ جنسیت با توجه به معیارهای آماری و از روی دانشجویان گذشته، تاثیری بر قبول شدن یا نشدنِ افراد در مقطع دکتری ندارد. پس این ویژگی یک ویژگیِ نویز به حساب میآید. یعنی برخی اوقات یک ویژگی یا بُعد نیز میتواند نویز باشد به این صورت که در تصمیمگیریِ نهایی تاثیرِ چندانی نداشته باشد. روشهای تشخیص ویژگیهای نویز بسیار هستند. یکی از آنها که در دورهی جبرخطی در موردِ آن صحبت کردیم، الگوریتمِ PCA است که ویژگیهایی با تاثیرِ کم را از میان ویژگیهای خود -تقریبا- حذف میکند. روشهای دیگری مانند chi2 نیز وجود دارند که قادر به تشخیصِ ویژگیهای کماهمیت هستند.

- ۱ » پیش پردازش دادهها (Data Preprocessing) چیست؟
- ۲ » بررسی یکپارچگی دادهها (Data Integrity)
- ۳ » نرمال کردن دادهها (Data Normalization) و انواع آن
- ۴ » تبدیل دادهها (Data Transformation) به فُرمت قالب فهم برای الگوریتم دادهکاوی
- ۵ » دادههای گمشده (Missing Values) و راهکارهای مقابله با آنها
- ۶ » تشخیص دادههای پرت و دارای نویز (Noise) و راهکار مقابله با آنها
- ۷ » انتخاب ویژگی (Feature Section) و کاهش ابعاد
- ۸ » انتخاب نمونه (Instance Selection) در پیش پردازش دادهها
سلام
سپاس فراوان که مطالب به این روانی و سادگی آموزش میدهید.