

شاید بَعد از الگوریتمِ خوشهبندی KMeans، الگوریتمِ DBSCAN را بتوان معروفترین الگوریتمْ در حوزهی خوشهبندیِ دادهها دانست. یکی از تفاوتهای اصلی این الگوریتم با KMeans این است که الگوریتم DBSCAN نیاز به تعیین تعدادِ خوشه توسط کاربر ندارد و خودِ الگوریتم میتواند خوشهها را مبتنی بر غلظتِ آنها شناسایی کند. اجازه بدهید در این درس ببینیم که این الگوریتم چگونه میتواند غلظت را شناسایی کند و خوشهها را در میان دادههای مختلف از یکدیگر تفکیک داده و شناسایی کند.
تصور کنید در بالای یک بُرج چند طبقه هستید و پایینِ بُرج انسانهایی قرار دارند. این آدم ها در گروههای مختلف در حال گفتگو با یکدیگر هستند. مانند شکل زیر:

حال به شما میگویند اینها را گروهبندی کنید. احتمالا یکی از روشهایی که به ذهنتان میرسد گروه بندیِ این افراد بر حسبِ تراکمی است که که در آن قرار دارند. ممکن است گروهبندیِ شما مانند شکل زیر باشد:
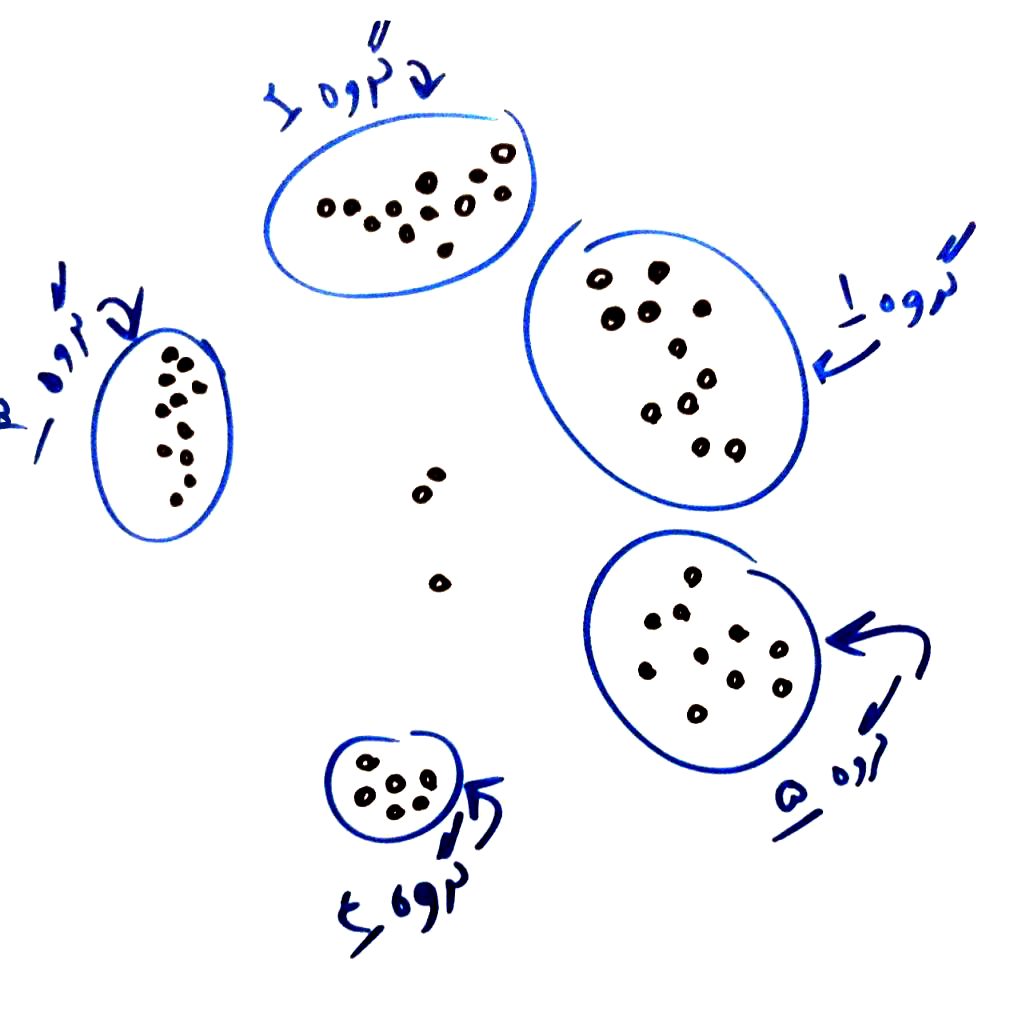
در واقع شما با استفاده از تراکم و غلظتی که از بالا میدیدید، این افراد را خوشهبندی کردهاید. همین کار توسط الگوریتمِ DBSCAN انجام می شود.
در الگوریتمِ DBSCAN دو پارامتر وجود دارد. یکی از آنها شعاع است که به آن Epsilon نیز میگویند و دومی حداقل نقاط موجود در یک خوشه است که به آن MinPoints میگویند. نحوهی کار الگوریتم ساده است. این الگوریتم ابتدا یک نمونه (که همان یک نقطه در فضای برداری میشود) را انتخاب میکند و با توجه به شعاعِ Epsilon به دنبال همسابه برای این نقطه در فضا میگردد (در موردِ فضا و بُعد در درسِ ویژگیها صحبت کردهایم). اگر الگوریتم در آن شعاعِ مشخصِ Epsilon حداقل توانست به تعدادِ MinPoint نقطه پیدا کند، آنگاه همهی آن نقطهها با هم به یک خوشه تعلق میگیرند. الگوریتمْ سپس به دنبال یکی از نقطههای همجوار نقطه فعلی میرود تا دوباره با شعاعِ Epsilon در آن نقطه به دنبالِ نقاط همسایه دیگر بگردد و اگر تعدادِ نقاطِ همسایهی جدید بازهم پیدا شوند، این الگوریتم دوباره همه آن نقاطِ جدید را با نقاط قبلی به یک خوشه متعلق میکند و اگر نقطهی جدیدی در همسایگی پیدا نکرد این خوشه تمام شده است و برای پیدا کردنِ خوشههای دیگر در نقاط دیگر، به صورت تصادفی یک نقطه دیگر را انتخاب کرده و شروع به یافتن همسایه و تشکیلِ خوشهی جدید برای آن نقطه میکند. این کار آنقدر ادامه پیدا می کند تا تمامی نقاط بررسی شوند.
اجازه بدهید به سراغ مثال برویم. فرض کنیم داده های ما مانند مثال پراید و اتوبوس در درس شبکه های عصبی در ۲بُعد پراکنده شده بودند (در اینجا فرض کنید دادهها، مانند نمونههای تصاویر بالا هستند) و میخواهیم این ها را توسط الگوریتم DBSCAN به خوشههای مختلف تفکیک کنیم:
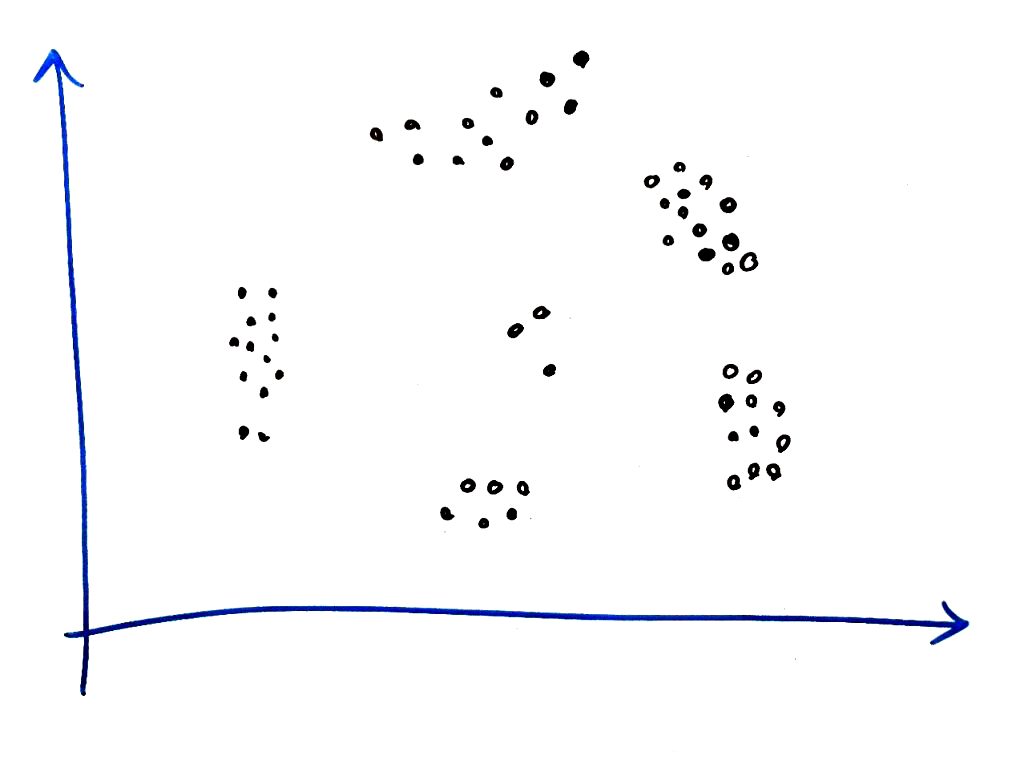
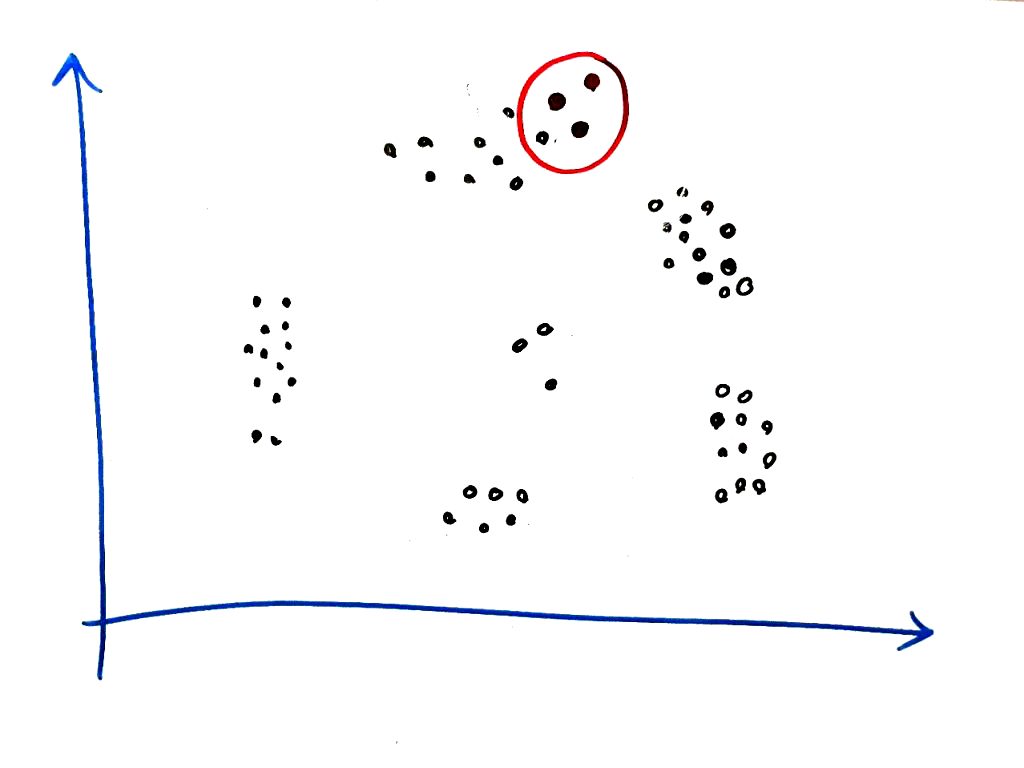
همان طور که گفتیم یک نقطه را به صورت تصادفی در فضا انتخاب میکنیم. ما از نقطه بالا سمت راست شروع میکنیم. در ضمن در این فرآیند، مقدار MinPTS را برابر ۳ قرار داده (یعنی حداقل نقاطی که باید در شعاع باشد تا یک خوشه تشکیل شود) و شعاعِ دایرهی جستجو برای هر نقطه را برابر ۱قرار میدهیم. شکل زیر انتخاب یک نقطه تصادفی و شعاع آن را نشان می دهد:
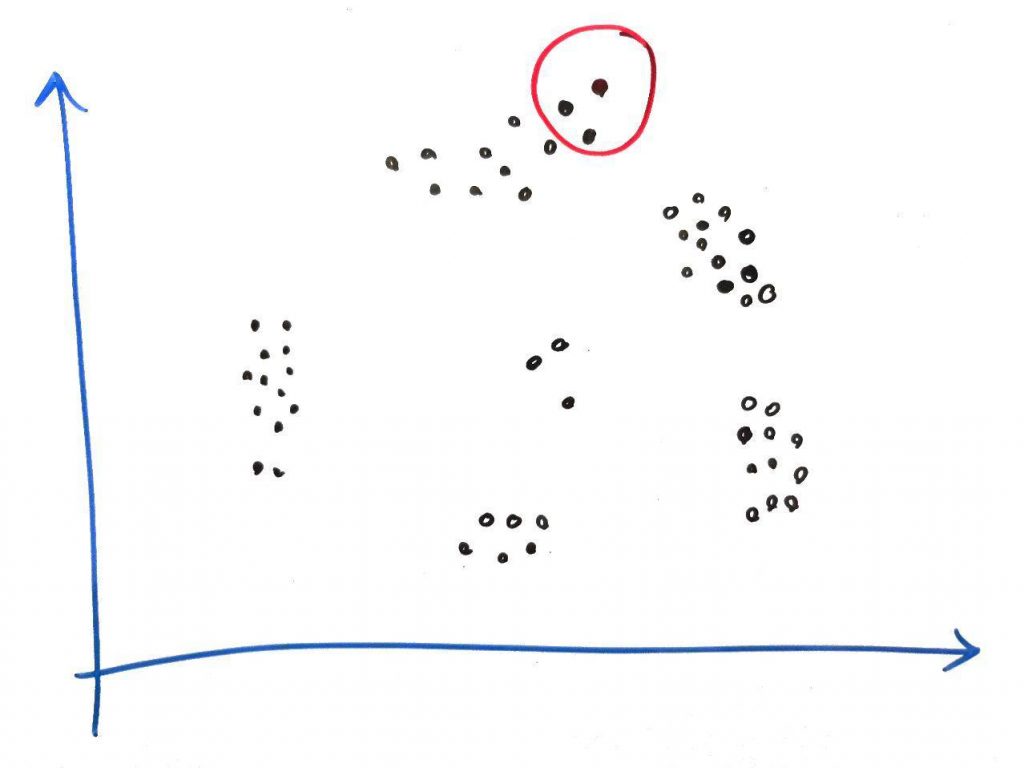
همان طور که میبینید، در یک شعاعِ مشخص، حداقل ۳نمونه در شعاعِ نمونهی مرکزی قرار دارند. پس این نمونه میتواند به عنوان یک خوشه انتخاب شود. مثلا رنگ قرمز را برای این خوشه انتخاب میکنیم. حال به سراغ نمونه همسایه ای نقطه میرویم و آن را مانند شکل زیر بررسی میکنیم:
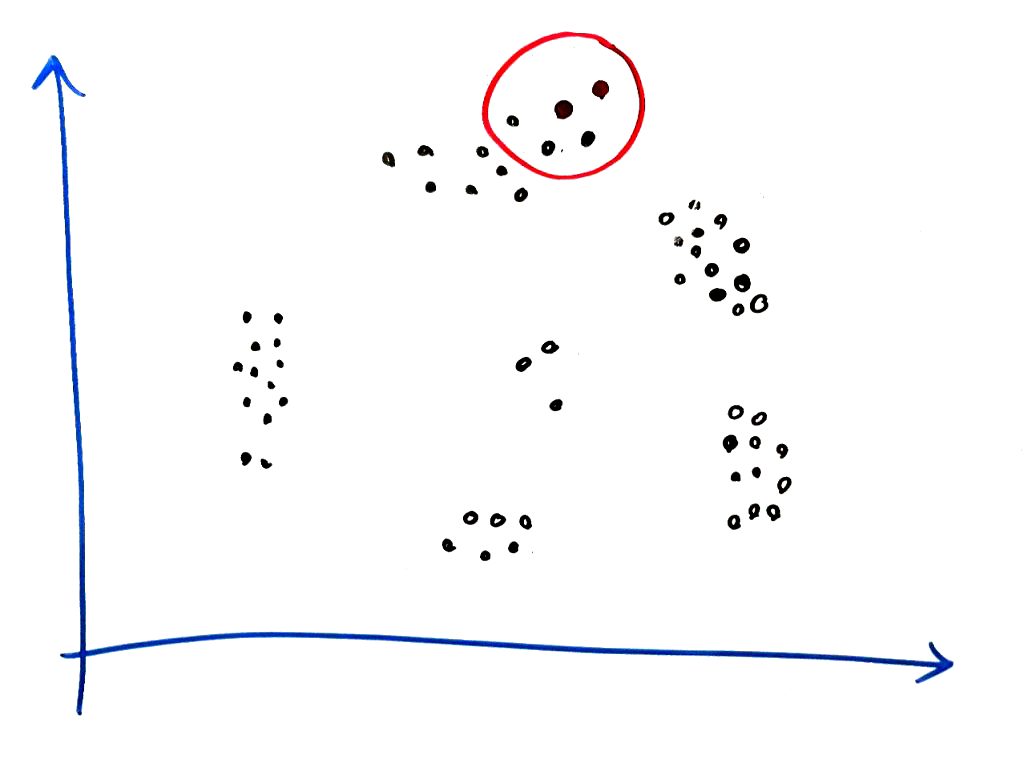
همان طور که نمونهی قبلی قرمز رنگ شده بود، با توجه به اینکه این نمونه هم حداقل ۳ نقطه در شعاع دور خود دارد، پس این نمونه هم به خوشه قبلی ما (خوشهی قرمز رنگ) میپیوندند و قرمز رنگ میشود. حال برای نقطهی همسایه نیز این کار را انجام میدهیم:
این کار ادامه پیدا میکند تا زمانی که دیگر نقطهای در میان خوشههای نزدیکِ همسایهها نباشد. مانند شکل زیر، که تمامیِ نمونههای بالای شکل را به خوشههای قرمز نسبت دادهایم:
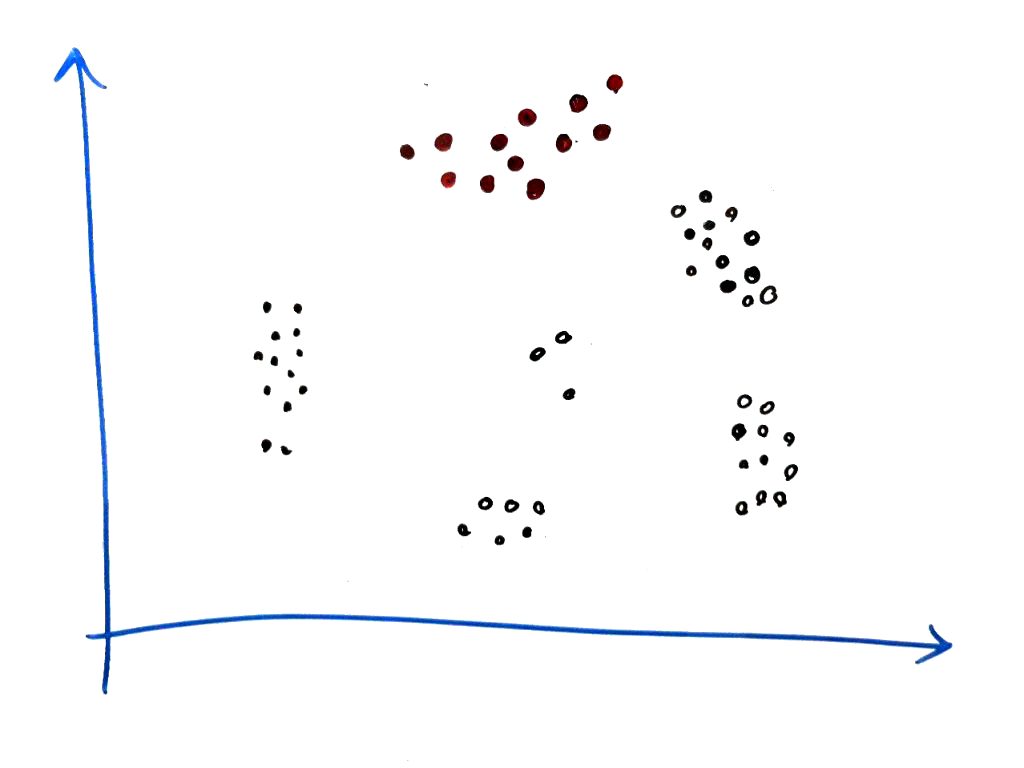
همانطور که میبینید، با پیشروی در میان همسایههای یک نمونه، توانستیم تمامی نمونههای خوشهی بالایی را شناسایی کنیم و همه آن ها را به یک خوشه نسبت دهیم. البته ممکن است تمامیِ نمونهها در همسایگی، دارای حداقل ۳همسایه نباشند. به این نمونهها، نقطه های مرزی یا حاشیه (border) گفته میشوند. مثلا در همان شکل بالا، در میان خوشهی قرمز رنگ، ممکن است نمونهای که انتهای سمت چپ قرار دارد، یک نقطه مرزی باشد که تعداد نمونههای داخلِ شعاع آن، برای مثال ۲باشد. در مقالهی اصلیِ این الگوریتم، به نقاطی که حداقل میزان MinPoints را در شعاع خود داشته باشند، نقاط هسته یا Core می گویند.
الگوریتم به همین ترتیب ادامه پیدا میکند. هنگامی که یک خوشه (مانند خوشهی قرمز بالا) تشکیل شد، یک نقطهی تصادفی دیگر را انتخاب میکنیم. برای مثال ممکن است نقطهی تصادفی جایی در نقاط سمت راست شکل باشد. این نقطه میتواند باعثِ شروعِ ایجاد یک خوشهی دیگر بشود. برای مثال خوشهی سبز رنگ در شکل زیر ایجاد می شود:
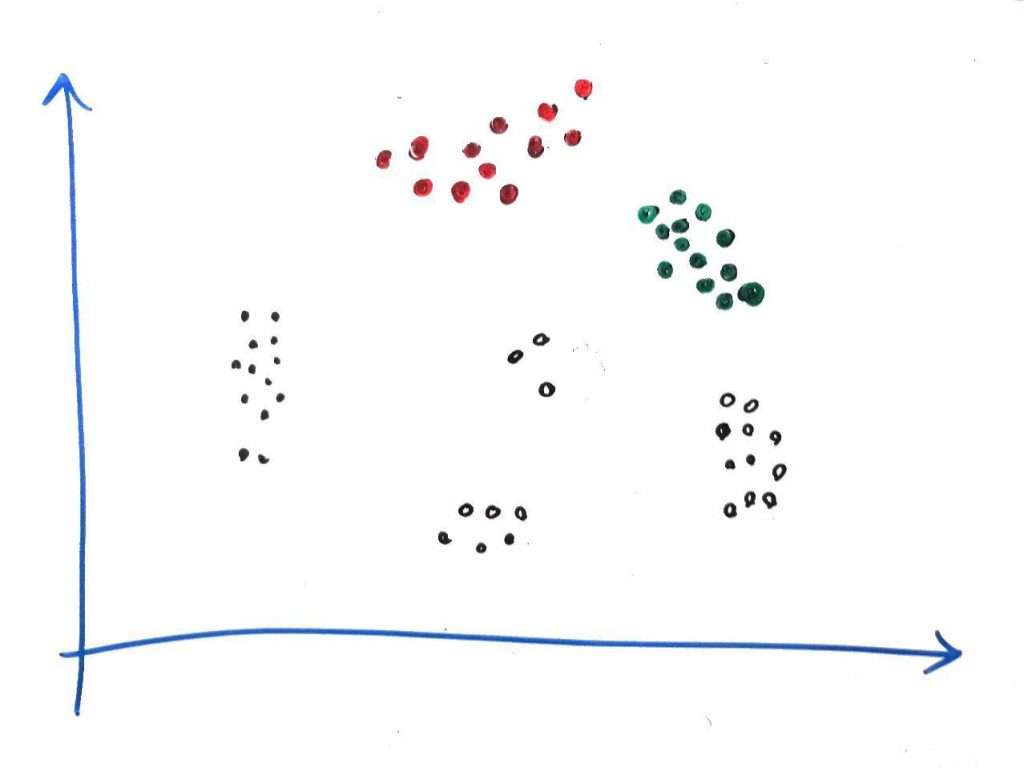
الان دو خوشه را ساختیم. به همین ترتیب میتوان خوشههای دیگر را نیز ساخت. توجه کنید هنگامی که یک خوشه به صورت کامل ساخته میشود، الگوریتم به دنبال نقاط دیگر در فضا به صورت تصادفی میگردد.
حال فرض کنید یک نمونه مانند شکل زیر پیدا شد که در شعاعِ مورد نظر الگوریتم، به تعداد کافی نمونه پیدا نکرد:
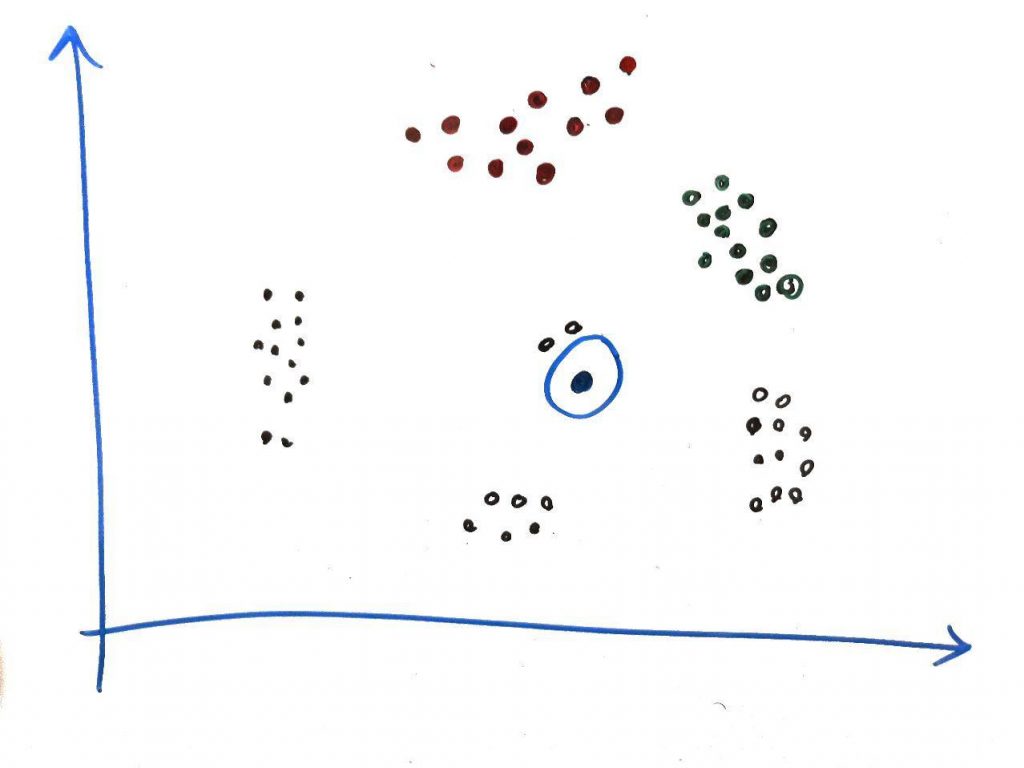
همانطور که میینید، این نمونه در شعاع خود، کمتر از ۳مورد نمونه دارد. الگوریتم DBSCAN این نمونه را به عنوان دادهی پرت یا Outlier شناسایی میکند و به هیچ خوشهای نسبت نمیدهد. البته الگوریتم بایستی تمامیِ خوشهها را بسازد و تمامیِ نقاط را بررسی کند تا بتواند بفهمد یک نقطه پرت است یا خیر.
الگوریتم همین طور ادامه پیدا میکند تا بتواند خوشههای دیگر را که حداقل به اندازهی ۳نمونه در شعاع خود دارند، خوشهبندی کند و در آخر آنهایی که به هیچ خوشهای نسبت داده نشدهاند، به عنوان دادهی پرت شناسایی میشوند.
الگوریتم DBSCAN حساس به دو پارامتر MinPoints و پارامتر شعاع است و هر چه شعاع را کوچکتر در نظر بگیرید، خوشههای بیشتر و کوچکتری تشکیلی میشود. همچنین هر چه قدر MinPoint را بزرگتر در نظر بگیرید، احتمال ایجادِ خوشهها، کمتر میشود زیرا الگوریتم باید تعداد نمونههای بیشتری را در یک شعاع خاص ببینید تا خوشه را تشکیل دهد.

توضیحات بسیار خوب بود.
عاااالی نوشتید عاااالی
واقعا عالی بود من این الگوریتم رو اصلا متوجه نمی شدم اما با توضیح بسیار زیبای شما همراه با یک مثال و شکل کاملا متوجه شدم. بسیار سپاسگذارم از شما استاد گرامی
بسیار عالی…
متشکرم.
سلام
توضیحات عالی
اما من بعد از مطالعه تمام خوشه بندی ها نمی دانم وقتی یک دیتاست بهم میدن از کجا می تونم تشخیص بدم که کدام الگوریتم خوشه بندی براش بهتر؟؟
سلام
فقط باید تست کرد
ابزار و روش های مختلف رو
ممنون
خدا خیرتون بده
عالی بود
ممنون
بسیار عالی
بسیار قلم ساده و روانی دارید. سپاس
سلام
خیلی ممنون
یه سوالی برام پیش اومد. اگر یه فضای گسترده ای داشته باشیم که تقریبا بصورت پیوسته نقاط کنار هم باشند، و اگر فاصله ها کمتر از فاصله ی تعریف شده باشند، آیا الگوریتم همه ی نقاط رو یک خوشه می کنه؟
سلام
بله، این یکی از نقاط ضعف این الگوریتم هست، برای همین الگوریتمهایی مانند Optics به وجود آمدند که این نقاط ضعف را پوشش دهند. البته با استفاده از روش GridSearch هم میتوانید به پارامترهای بهینهبرای این الگوریتم برسید
با سلام خدمت شما استاد گرامی توضیحاتتون عالی بود
آیا این روش خوشه بندی برای داده های کمّی مربوط به ژنتیک مناسب است؟
سلام
بله، البته باید روشهای دیگر را هم امتحان کنید و بهترین را انتخاب کنید
Salam. bebakhshid English minevisam; ruye in system persian keyboard nadaram. Manzuretun az genetics data chiye? mn az in algorithm baraye trajectory clustering estefade mikonam. Protein design va simulation mikonam va baad clustering mikonam.
سلام
ممنون از تدریس عالیتون
می تونید در مورد خوشه بندی پویا هم تدریس کنید و این که DBSCAN میتونه به عنوان خوشه بندی پویا استفاده بشه ؟؟؟
لطفا راهنمایی کنید
سلام
منظورتون از خوشهبندی پویا چیه؟
behtarin blog va behtarin tozihe farsi az clustering bud ke ta hala didam.
بسیار عالی توضیح دادن. ممنونم