

الگوریتمِ KMeans با وجودِ اینکه الگوریتمِ بسیار خوبی برای خوشهبندی است، یک مشکل اساسی دارد و آن این است که کاربر، در ابتدا باید تعداد خوشههای موجود را به این الگوریتم بگوید. در واقع الگوریتمِ KMeans بایستی تعدادِ نقاطِ اولیهی خود را بداند تا به وسیلهی آن بتواند خوشهها را بسازد. برای غلبه بر این مشکل میتوان از الگوریتمِ MeanShift استفاده کرد. در این درس قصد داریم به این الگوریتم و چگونگیِ کارکرد آن بپردازیم.
شکل زیر را نگاه کنید:

فرض کنید میخواهیم این شکل را بدون دانستنِ تعداد نقاطِ آغازین، خوشهبندی کنیم. همانطور که میبینید، در هر گروه یک سری نقاط وجود دارند که تجمُعِ بالاتری در آنها است (غلظت بالاتری دارند). کارِ اصلیِ الگوریتمِ MeanShift پیدا کردنِ این نقاطِ با تجمُعِ بالا در هر خوشه است تا با کمکِ آن بتواند خوشههای مختلف را پیدا کند. در واقع الگوریتمِ MeanShift مانند این است که هر نمونه (نقطه) در فضا را به آرامی و در تکرارهای مختلف، به سمت نقطهای با تجمُعِ بیشتر در نزدیکی خود حرکت میدهد تا سرانجام همهی نقاط در یکجا (یا تقریبا یکجا) جمع شوند. برای مثال شکل زیر را نگاه کنید:
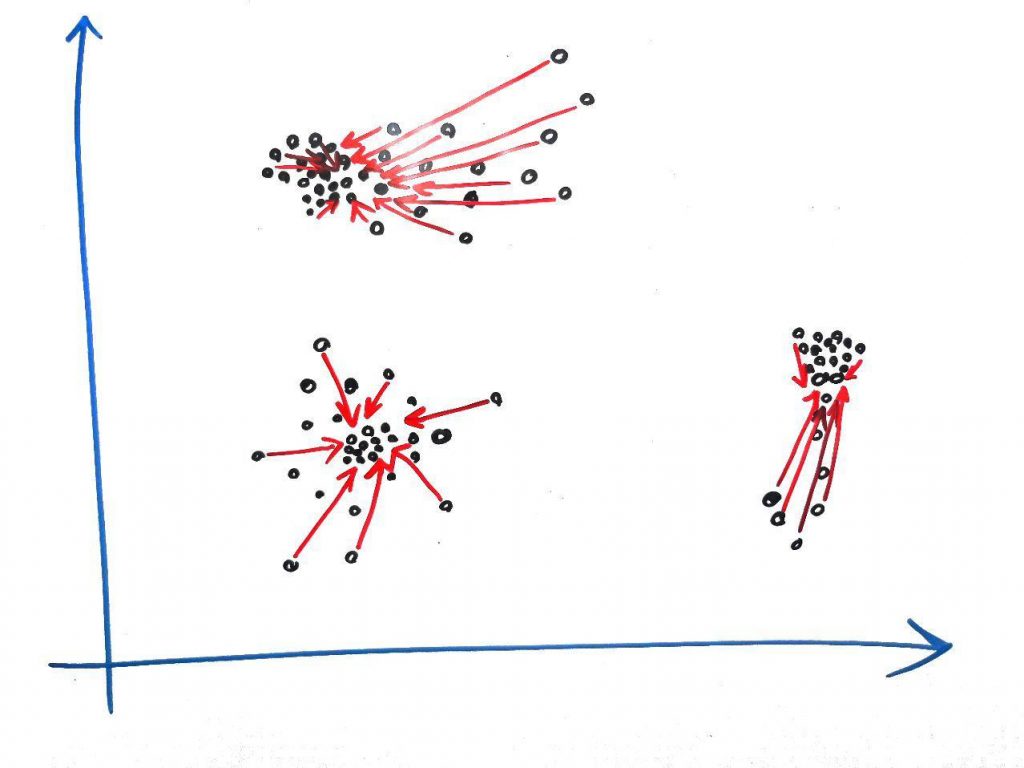
همانطور که میبینید، هر کدام از نقاط در هر گروه تمایل دارند به نقطهای که تجمُعِ بیشتری در آن قرار دارد (یعنی غلیظتر است) حرکت کنند. اگر بخواهیم آماری صحبت کنیم، در نقطه ای که تجمُع بیشتر است، مقدار PDF (Probability Density Function) بالاتری داریم و الگوریتم میخواهد نمونهها (نقاط) را آرام آرام به این نقطه که تجمُعِ زیادی دارد همگرا کند.
اجازه بدهید ببینیم برای یک خوشهی خاص که اتفاقی میافتد. دو حرکت از نقاط زیر را در نظر بگیرید:
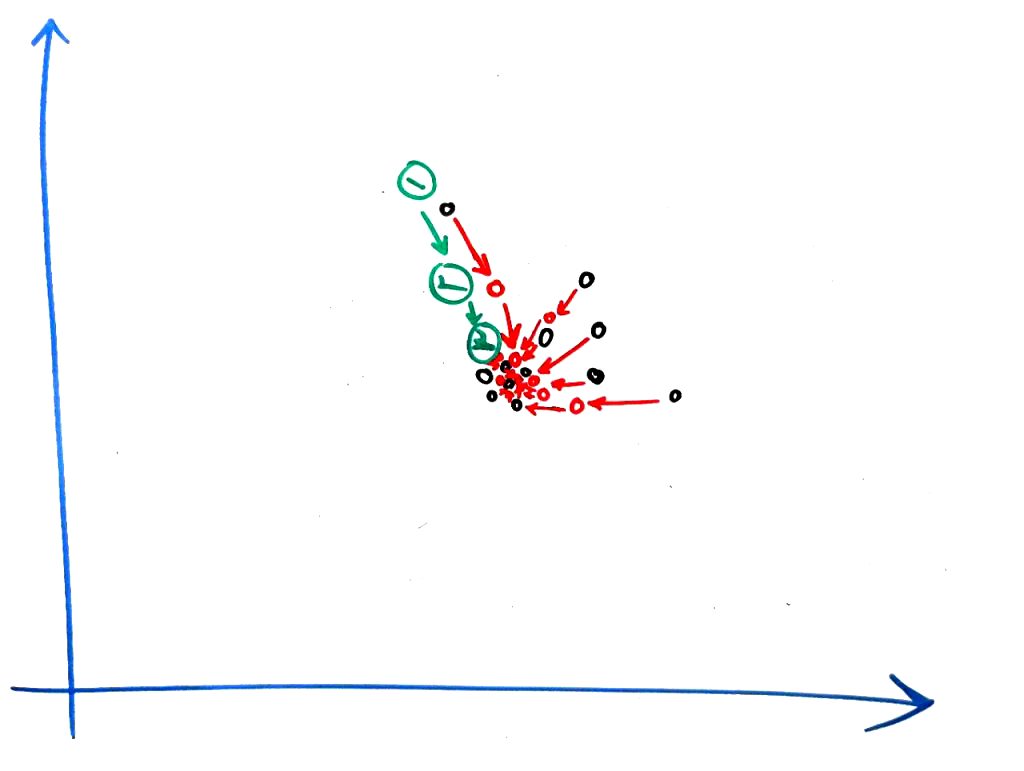
برای سادگی یک نقطهی سیاه بالا را در نظر بگیرید (که یک نمونه است – درسِ ویژگی یا بُعد چیست را خوانده باشید). نقطهی سیاهی که با عدد ۱ نشان داده شده است در دورِ (Iterate) اول ابتدا به نقطه قرمز رنگ شماره ۲ میرود و در دورِ بعد به نقطهی قرمز رنگ شمارهی ۳ انتقال پیدا میکند. همانطور که میبینید این نقطه در هر دور به مکانِ غلیطتر (که تجمُعِ بیشتری از نقاط آنجا هستند) حرکت میکند. بقیه نقاط هم به همین شکل هستند. در واقع بعد از چند دور (مانند الگوریتم KMeans) نقاطِ حاضر در یک خوشه به یک نقطه همگرا میشوند و این نقطهی همگرایی باعث میشود که یک نمونه به یک خوشه تعلق پیدا کند. این کار آنقدر ادامه پیدا میکند که تمامیِ نقاط به یک نقطه در فضا همگرا شوند و یا اینکه به تعدادِ مشخصی تکرار (دور) داشته باشد.
الگوریتمِ MeanShift عملیاتِ خوشهبندی را با استفاده از میانگینِ وزنی یا همان Weighted Arithmetic Mean انجام میدهد. البته که این الگوریتم از Kernelهای مختلف میتواند استفاده کند که بحث در موردِ Kernelها خارج از این درس است ولی معمولا Kernel گوسی برای بسیاری از مسائل جواب میدهد. (برای مطالعه بیشتر و دقیق تر به قسمت منابع پایین همین درس مراجعه کنید)
نکته قابل ذکر در مورد الگوریتم MeanShift سرعت کندتر آن نسبت به الگوریتم KMeans است. زیرا پیچیدگیِ زمانی محساباتیِ این الگوریتم بیشتر از الگوریتم KMeans است ولی پیدا کردنِ تعداد خوشهها به صورت خودکار، میتواند در بسیاری از مسائل خیلی جذاب بوده و نقطهی قوت این الگوریتم باشد. برای مثال، شما یک دسته از مشتریان دارید که دقیقاً نمیدانید که آنها، در چند گروه مجزا قرار میگیرند و الگوریتمِ MeanShift این قابلیت را دارد که تعداد خوشهها را به صورتِ خودکار (مانند الگوریتم DBSCAN) برای ما پیدا کند. این الگوریتم کاربرد وسیعی در خوشهبندیِ تصاویر و شناساییِ عناصرِ متحرک در تصاویرِ پیوسته مانند فیلم دارد.

اقا خیلی وبسایتتون عالیه
اقا خیلی وبسایتتون عالیه
سلام.خواستم بابت وبسایت خوبتون ازتون تشکر کنم و امیدوارم
باعث ایجاد انگیزه براتون بشه
سلام.وبسایت خیلی خوبی دارید.ممنون
سلام.واقعا وبسایت خوبی دارید
عالی
عالی هستید