

الگوریتمهای زیادی جهت خوشهبندی (Clustering) عرضه شدهاند که هر کدام کاربردها و سرعتهای خاص خود را دارند. در دروسِ گذشته با انواع روشهای پایهای خوشهبندی آشنا شدیم. در این درس میخواهیم یک الگوریتمِ خوشهبندی که کمی پیشرفتهتر به نظر میرسد را با یکدیگر مرور کنیم. این الگوریتم که خوشهبندیِ طیفی یا همان Spectral Clustering نام دارد شاید در ابتدا کمی سخت و پیچیده به نظر برسد، ولی با شناختِ مفاهیمِ پایه و ترکیبِ آنها میتوان به خوشهبندی طیفی دست یافت. این خوشهبندیْ خود در نهایت از الگوریتمی مانند KMeans استفاده میکند، ولی قبل از آن یک سری تغییر در ساختار دادهها و در واقع تغییر در نگاه خود به دادهها به وجود میآورد.
شکل زیر را در نظر بگیرید:
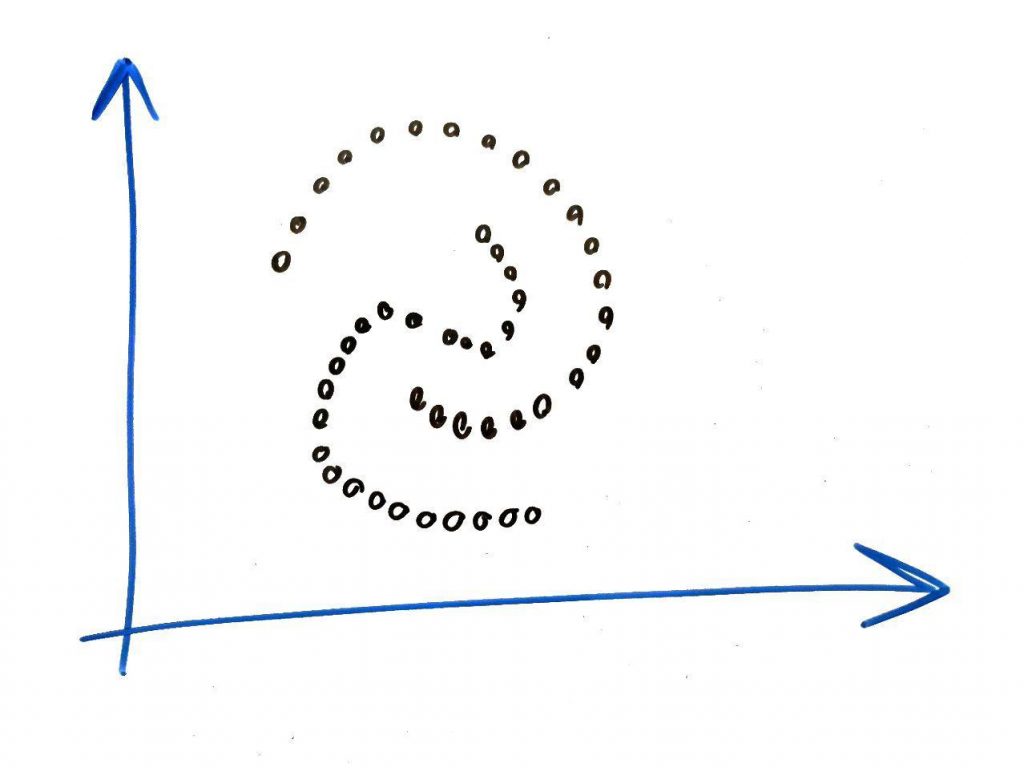
همان طور که میبینید در این شکل دو مسیرِ غیرِ مسطح در یکدیگر تنیده شدهاند. برخی از مواقع دادهها یک همچنین شکلی دارند (برای درکِ بُعد، این درس را خوانده باشید). البته الان ما برای سادگی در دو بُعد داده ها را رسم کردیم که در اکثر مواقع تعداد ابعاد بیشتر است. اگر بخواهیم شکل بالا را با استفاده از الگوریتم KMeans به دو خوشه تبدیل کنیم، احتمالاً به دو خوشهی زیر میرسیم:
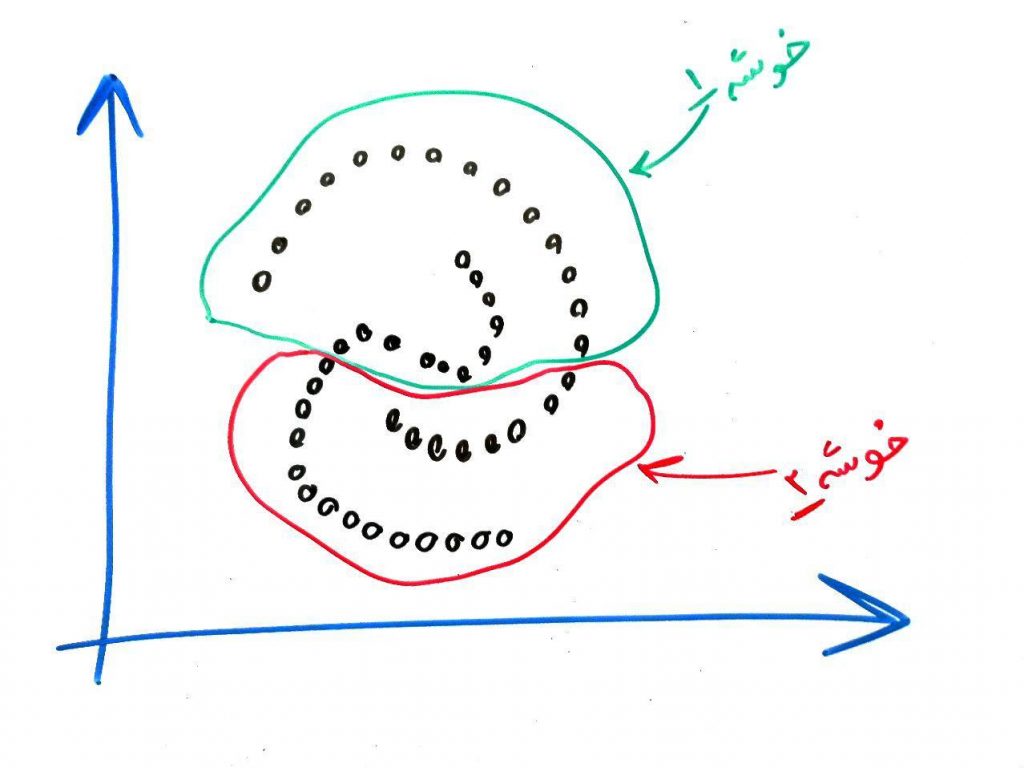
ولی فرض کنید ما میخواهیم شکل بالا را به صورت زیر خوشهبندی کنیم:
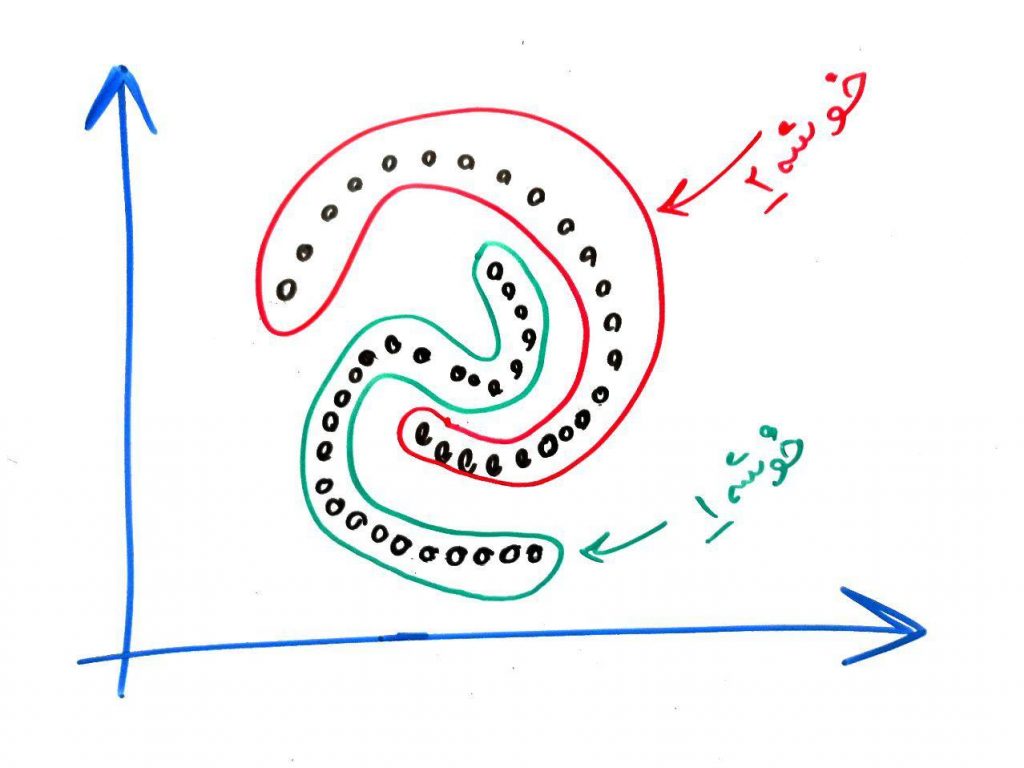
یعنی هر کدام از شکلهای تو در تو را به صورت یک خوشه در نظر بگیریم. برای این کار میتوان از الگوریتمِ Spectral Clustering استفاده کرد. در واقع این الگوریتمِ خوشهبندی باعث میشود که خوشهها به صورت شکلهایی ساخته شوند که نقاطِ نزدیک و متصل به هم در یک خوشه قرار گیرند. این نوع نگاه به دادهها را میتوان یکی از مزایای اصلیِ روشِ خوشهبندیِ طیفی یا همان Spectral Clustering دانست.
از آن جایی که ساخت این الگوریتم نیاز به یک سری پیشزمینهها دارد، طبق رسمی که در چیستـIO داشته ایم، اجازه بدهید یک نمای کلی از نحو ساخت خوشه ها در این الگوریتم بگوییم که ممکن از برای بسیاری از دانشجویان نامفهوم به نظر برسد:
این الگوریتم ابتدا یک ماتریس وابستگی (Affinity Matrix) میسازد و با ساختِ این ماتریسِ وابستگی، در واقع مسئلهی ما به یک گرافْ تبدیل میشود که اجزای به هم متصلِ گرافْ تشکیلِ یک خوشه را با هم میدهند. در واقع در این گراف، یال هایی که در یک عناصر آنها در یک خوشه هستند وزن زیادی دارند، و برعکس یال هایی که عناصرِ آنها در یک خوشه نیستند، وزن کمتری را دارند. بعد از آن لاپلاسینِ گراف را ایجاد کرده بردارهای ویژه را برای آن انتخاب میکنیم. در آخر با الگوریتمی مانند KMeans از میانِ بردارهای ویژه میتوان به خوشهبندیهای مورد نظر دست پیدا کرد. البته در نهایت این الگوریتم نیز نیاز به گرفتن تعدادِ موردِ انتظار خوشهها از کاربر دارد ولی در شرایطی و با استفاده از فاصلهی بین بردارهای ویژه، میتوان تعداد بهینه را برای تعداد خوشهها انتخاب کرد. به این کار به اصطلاح Rounding میگویند.

سلام .اگر براتون امکان داره این الگوریتم را هم مثل درسهای قبلی به صورت جامع تر و با ذکر مثال توضیح بدید..مرسی
با سلام ضمن تشکر از زحمات بی ذریغ شما…ممنون میشم اگر یک مبحث اولیه راجب تمامی روشهای موجود خوشه بندی و طبقه بندی داده ها و کاربرد هر یک وجود داشته باشه تا فرد با توجه به نیاز سنجی کلاسترینگ روی مبحث کاربردی مد نظر خودش فوکوس کند. برای روشن تر شدن خواسته مثالی عنوان میکنم: مثلا من میخوام بدونم چه روش طبقه بندی برای داده هایی مثل مغز مناسب است؟ اصلا باید به دنبال روشهای ساختاریافته باشم یا روشهای غیر ساختاری؟و پاسخگویی به این قبیل سوالات کاربردی کیفیت کار را مسلما بسیار بالاتر میبره. سپاس از بذل توجه شما
با سلام
از نظر شما خوشه بند مناسب برای داده عای متنی چیست؟ فرض کنید عبارات اسمی موجود در متن شناسایی شده اند و دنبال خوشه بند مناسبی برای عبارات اسمی هم مرجع هستیم
با تشکر
سلام لطفا میشه توضیح خوشه بندی فازی هم بذارید؟
میشه توضیح و مثالی در خصوص فرا ابتکاری ریسک طیفی بزنید
بسیار ممنون خواهم شد
مطالب جالب بود .ار رحمات شما متشکرم