

فرض کنید در یک فروشگاهِ زنجیرهای کار میکنید و مسئولیتِ جمعآوری دادهها به شما مُحوّل شده است. برای سادگی فرض کنید جداولِ زیر را برای پایگاهدادهی خود دارید:
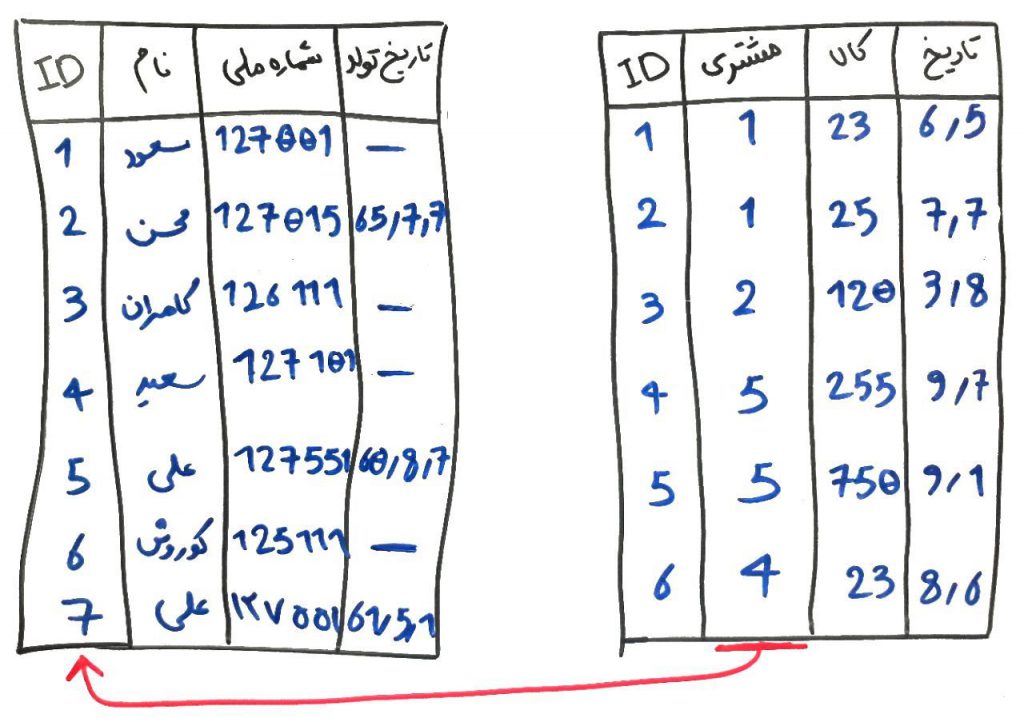
دو جدول که یکی خریدها را نمایش میدهد و یکی مشتریان را. طبیعتاً بایستی هر خرید توسطِ یک مشتری انجام شود. یعنی نمیتوانید خریدی داشته باشید که هیچ مشتریای نداشته باشد! اینجا به یکی از مثالهای یکپارچگی داده میرسیم. در واقع در این مثال برای اینکه دادههای شما یکپارچه باشد، در جدولِ خریدها، تمامِ آنها بایستی یک شناسهی مشتری را داشته باشند. در غیر این صورت یکپارچگی دادهها دچار مشکل میشود. پس یک شخص که کارِ یکپارچهسازی دادهها را انجام میدهد بایستی به همچین نکاتی توجه داشته باشد.
مورد دیگری که باعث نقضِ یکپارچگی در مثالِ بالا میشود، وجود چندبارهی یک مشتری است. مثلا مشتریِ شماره ۵ و ۷ دقیقا یک نفر هستند که به اشتباه (توسط اپراتور) دو بار در سیستم درج شدهاند (با دو تاریخ تولدِ متفاوت). ممکن است نرمافزاری که عملیاتِ درج را انجام میدهد، جلوی درجِ تکراری را نگرفته باشد و یا مانند مثال بالا، شمارهی ملیِ این مشتری، یکبار با کاراکترهای فارسی و یکبار با کاراکترهای انگلیسی وارد شده باشد. در مثالِ بالا، تاریخ تولد نیز نامعتبر است و این احتمالاً نشان میدهد که مشتریان خودشان تاریخِ تولد را هر چه میخواستند وارد کردهاند. همانطور که حدس میزنید این دست از دادهها و مسائل اینچنینی، میتوانند باعث کثیف شدنِ دادهها شوند و تاثیر منفی بر روی الگوریتمهای دادهکاوی در مرحلهی بعد از پیش پردازش و به تبعِ آن، نتایج و تحلیلهای حاصل داشته باشند. مانند مثال بالا، از یک متخصص علوم داده انتظار میرود که در تعاملی که با بخشهای مختلفِ یک سازمان دارد، بتواند عدم یکپارچگی یا همان Integration را در دادهها کشف کند و راهحلی برای آن پیدا کند. مثلاً در نمونهی بالا، میتوان تمامِ اعدادِ شماره ملی را به انگلیسی تبدیل کرد و در صورت وجود تکرار در شماره ملی مشتریان، یکی از آن رکوردها (سطرها) را نگه داشت و دومی را پاک کرد. البته توجه داشته باشید که خریدهای آن مشتریِ تکراریِ پاک شده نیز بایستی به سطرِ باقیمانده تبدیل شود.

- ۱ » پیش پردازش دادهها (Data Preprocessing) چیست؟
- ۲ » بررسی یکپارچگی دادهها (Data Integrity)
- ۳ » نرمال کردن دادهها (Data Normalization) و انواع آن
- ۴ » تبدیل دادهها (Data Transformation) به فُرمت قالب فهم برای الگوریتم دادهکاوی
- ۵ » دادههای گمشده (Missing Values) و راهکارهای مقابله با آنها
- ۶ » تشخیص دادههای پرت و دارای نویز (Noise) و راهکار مقابله با آنها
- ۷ » انتخاب ویژگی (Feature Section) و کاهش ابعاد
- ۸ » انتخاب نمونه (Instance Selection) در پیش پردازش دادهها