

فرض کنید مدیرِ یک مجموعه هستید و میخواهید با توجه به ویژگیهای یکی از کارکنانِ خود، وظیفهای را به او محول کنید (مثلاً او را مدیرِ یک پروژه کنید). ولی این شخص تا به حال پروژهای برای شما انجام نداده است. برای اینکار ویژگیهای مختلفی از کارکنانِ قبلیِ خود را جمعآوری کرده و آنها را در جدولی مانندِ جدول زیر رسم میکنید:
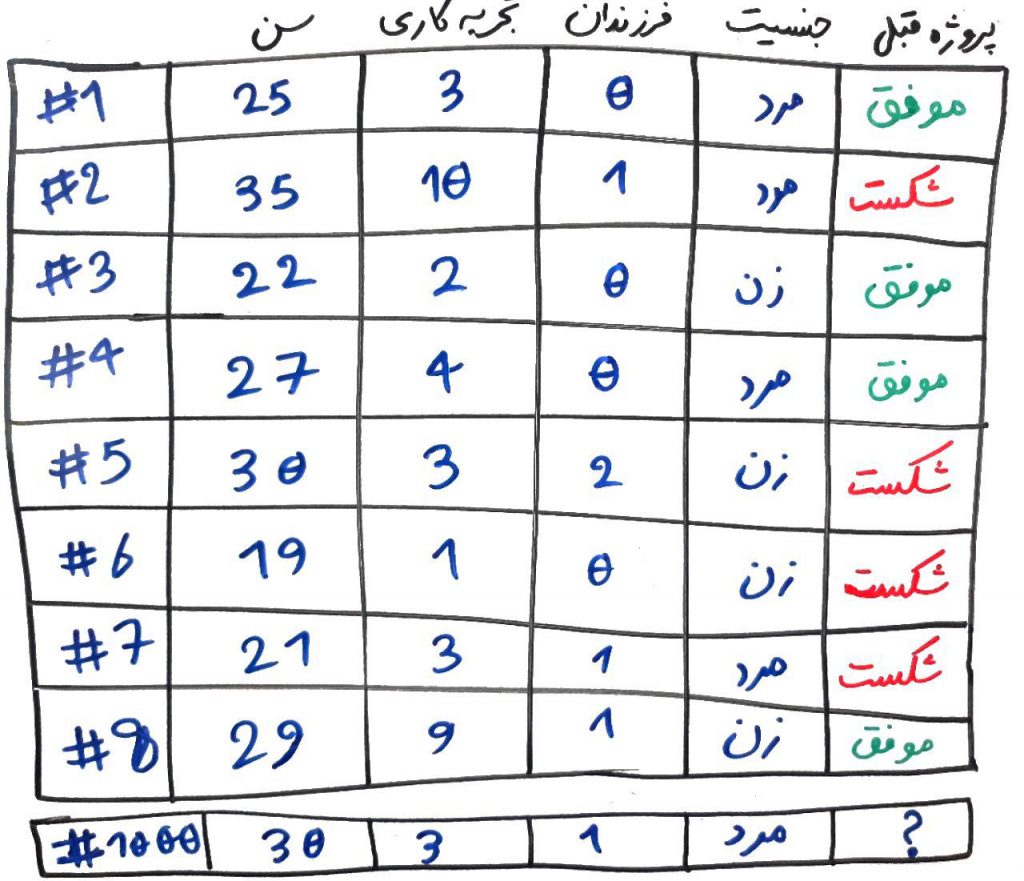
همانطور که میبینید، ویژگیهایی مانندِ سن، تعداد سالِ تجربه کاری، تعداد فرزندان و جنسیت را گردآوری میکنید و ستونِ آخر هم برچسب یا طبقه است و به این معناست که این شخص توانسته آخرین پروژهی کاریِ خود را موفقیت به پایان برساند یا خیر؟ در واقع شما میخواهید با توجه به ویژگیهای این کارکنان، نوعی یادگیری را بر روی دادهها انجام داده و ببینید که فردِ شمارهی ۱۰۰۰ که فردِ جدیدی هست و تا به حال پروژهای انجام نداده، آیا میتواند از عهدهی این پروژه برآید یا خیر؟ (حتماً میدانید که این یک مثالِ طبقهبندی است)
در مثالِ بالا، ۴ ویژگیِ مختلف داریم که امیدواریم در تصمیمگیریِ نهایی تاثیر داشته باشند. نگاهی به ویژگیِ جنسیت بیندازید. دقیقاً ۲نفر از مردان و ۲نفر از زنان آخرین پروژهی خود را با موفقیت پشت سر گذاشتهاند و ۲نفر از مردان و ۲نفر از زنان نتوانستهاند در آخرین پروژهی خود موفقیت باشند. نتیجه این است که جنسیت در انجامِ موفق پروژه نقشی نداشته اشت. به عبارتِ دیگر، ویژگیِ جنسیت، اطلاعاتِ خاصی به ما نمیدهد و الگوریتمِ طبقهبندی نیز نمیتواند از آن اطلاعاتی کسب کند. در واقع این ویژگی دارای ارزش کمی است و بهتر است از میانِ ویژگیها کنار گذاشته شود (در مورد اطلاعات و ارزش اطلاعاتیِ یک ویژگی در درسِ آنتروپی صحبت کردیم). پس در اینجا تعداد ویژگیهای ما میتواند از ۴ به ۳ کاهش پیدا کند.
مشاهده میکنید، با یک نگاه توانستیم آن ویژگیای که ارزش مناسبی نداشت (در اینجا جنسیت) را پیدا کنیم. اما با بزرگتر شدنِ مجموعهی داده و تعدادِ ویژگیها، نمیتوان این کار را بدون استفاده از روشهای آماری و الگوریتمهای مخصوص به آن انجام داد. برای همین در این موارد میتوان از الگوریتمهای کاهشِ ویژگی استفاده کرد و تعداد ویژگیها یا همان ابعاد را کاهش داد. به این الگوریتمهای در اصطلاح الگوریتمهای کاهشِ ابعاد یا dimensionality reduction نیز میگویند.
البته اینطور نیست که فقط به خاطرِ پایین بودنِ ارزشِ یک ویژگی بخواهیم آن را کنار بگذاریم. در بعضی از موارد تعدادِ ویژگیهای مجموعهی داده بسیار زیاد است و الگوریتمهای دادهکاوی (مانند طبقهبندی یا خوشهبندی) در ابعادِ زیاد دچار خطا میشوند و یا سرعت انجامِ عملیات در آنها کاهش پیدا میکند. همچنین در بعضی از موارد میخواهیم با کاهشِ تعداد ابعاد، آنها را در یک نمودار یا چارت رسم کنیم. برای همین بایستی دادهها را به تعداد ۲ یا ۳ بُعد تبدیل کرده تا قابل نمایش باشند.
الگوریتمهای مختلفی برای کاهش ابعاد وجود دارد. در موردِ الگوریتم PCA در دورهی جبر خطی صحبت کردیم. این الگوریتم میتواند دادهها به ابعاد کوچکتر تبدیل کند. همچنین الگوریتمهایی مانند chi2 نیز میتوانند با شناساییِ ویژگیها ارزشمند، آنها را از ویژگیهای غیرِ ارزشمند جدا کرده و به نوعی کاهش ابعاد انجام دهند.

- ۱ » پیش پردازش دادهها (Data Preprocessing) چیست؟
- ۲ » بررسی یکپارچگی دادهها (Data Integrity)
- ۳ » نرمال کردن دادهها (Data Normalization) و انواع آن
- ۴ » تبدیل دادهها (Data Transformation) به فُرمت قالب فهم برای الگوریتم دادهکاوی
- ۵ » دادههای گمشده (Missing Values) و راهکارهای مقابله با آنها
- ۶ » تشخیص دادههای پرت و دارای نویز (Noise) و راهکار مقابله با آنها
- ۷ » انتخاب ویژگی (Feature Section) و کاهش ابعاد
- ۸ » انتخاب نمونه (Instance Selection) در پیش پردازش دادهها
شما بينظريد ساده و كاملا قابل فهمه توضيحاتتون
با سلام خیلی عالی توضیح دادین، لطفا اگه امکانش هست در مورد انواع الگوریتم ها و توضیح هر کدوم هم توضیح بدین
سلام ممنون از اطلاعات مفیدتون
لطفا انتخاب ویژگی مبتنی بر فیلتر بهره ی اطلاعاتی را هم به مطالبتون اضاف کنید.
سلام و عرض ادب
امکانش هست راهنمایی بفرمایید چگونه میتونم مطالب ساده برای درک الگوریتم NCA پیدا کنم.
هر مطلبی رو که خوندم متوجه اصل موضوع نمیشم.
خیلی خیلی ممنونم
باید در تایتل بنویسید feature selection