

پروژههای مختلف صنعتی، هر کدام روشها و فرآیندهای خاص خود را دارند. برای مثال در فرآیند مهندسی ساخت و تولید یک نرم افزار، میتوان از روشهای گوناگونی مانند روش آبشاری، روش حلقوی یا روش چابک استفاده کرد. برای اجرای فرآیندهای دادهکاوی نیز، روشهای مختلفی تولید شده است که یکی از محبوبترین آنها روش «فرآیند استاندارد صنعتی متقاطع» است که مخفف شده و لاتینِ آن به CRISP معروف است.
روش کریسپ (CRISP) برای اجرای پروژههای دادهکاوی در صنعت به کار گرفته میشود و دارای مراحل زیر است:
۱. فهم کسب و کار (Business Understanding)
در این مرحله، یک متخصص علم داده بایستی کسب و کاری که میخواهد بر روی آن پروژه دادهکاوی انجام دهد را به خوبی بشناسد. در مرحلهی فهم کسب و کار، بایستی زوایای مختلف آن کسب و کار، محدودیتها، شرایط موجود و اهداف آن کسب و کار از پروژه یا پروژههای جاری را بررسی نمود. این مرحله ذهن متخصص علم داده را برای کار بر روی پروژه آماده میکند و به او اجازه میدهد تا با شناخت بیشتر و بهتر به سراغ مراحل بعدی برود. در این مرحله، یک متخصص علم داده میتواند تا حدودی به کسب و کارِ موجود مسلط شده و فهم خود را از آن کسب و کار تا حد ممکن بالا ببرد.
۲. فهم دادهها (Data Understanding)
در مرحلهی فهم دادهها، متخصص علم داده، به سراغ دادههای موجود کسب و کار رفته آن را برای شروع پروژه بررسی میکند. در این مرحله، عملیاتی مانند «آنالیز اکتشافی دادهها – EDA» و ساخت گزارشهای اولیه از دادهها میتواند بسیار کمک کننده باشد. با فهم دادهها و درک ابعاد و ویژگیهای مختلف آن، میتوان ایدههای مختلف را مطرح کرد و ساختار اصلی پروژه را تعیین نمود. در این مرحله میتوان کیفیت دادهها را نیز ارزیابی کرد و در صورت نامناسب بودن دادهها، با مشورت و مشارکت قسمتهای مختلف کسب و کار، این دادهها را بهبود بخشید.
۳. آمادهسازی دادهها (Data Preparation)
بعد از فهم کسب و کار و فهم دادهها، حال میتوان دادهها را آمادهی تحلیل و مدلسازی کرد. اگر دورهی پیش پردازش دادهها را در چیستیو مطالعه کرده باشید، احتمالاً به سادگی میتوانید این مرحله را درک کنید. در این مرحله، دادههای کثیف، تمیز میشوند و دادهها به صورت ساختاری، برای مرحلهی بعدی آمادهسازی میشوند. در این مرحله همچنین میتوان مجموعه دادههای مختلف را با یکدیگر ترکیب کرد تا به مجموعه دادهی بهتر و با کیفیتتری رسید.
۴. مُدلسازی (Modeling)
بسته به اینکه مسئلهی شما چه نوع مسئلهایست در این مرحله بایستی از الگوریتمها و روشهای مخصوص به خود استفاده کنید. مثلاً اگر مسئلهی شما طبقهبندی دادههاست، بایستی از الگوریتمهای طبقهبندی برای یادگیری استفاده کنید و یا اگر مسئلهی شما در دستهی خوشهبندی قرار میگیرد، میتوانید یکی از الگوریتمهای خوشهبندی را برای پروژهی خود مورد استفاده قرار دهید. البته در یک پروژهی دادهکاوی، ممکن است مسائل مختلف و ترکیبی وجود داشته باشد که نیاز به عملیات پیچیدهتری جهت مدل سازی دارند.
۵. ارزیابی (Evaluation)
چیزی که قابل ارزیابی نباشد، بهبود پیدا نمیکند. اگر در مراحل قبلی دادهها را آماده کردید و مدلی ساختید، بایستی بتوانید مدلِ خود را ارزیابی کنید. این ارزیابی بستگی به مدلِ انتخابی دارد. برای مثال اگر مسئلهی شما طبقهبندی بود، میتوانید از روشهای ارزیابی الگوریتمهای طبقهبندی استفاده کنید. طبیعتاً اگر مدلِ شما به اندازهی کافی کیفیت نداشت، بهتر است به مراحل قبلی بازگرید و مدل یا دادهها یا روشهای آمادهسازی دادههایتان را بهبود بخشیده و مجدداً ارزیابی را انجام دهید.
۶. پیادهسازی و انتشار (Deploy)
در نهایت، بایستی نرم افزاری توسعه دهید تا کاربران بتوانند از زحمات شما استفاده کنند. این مرحله، معمولاً با کمک مهندسین نرم افزار و برنامه نویسان انجام میشود.
دیاگرام کلی روش کریسپ (CRISP) به صورت زیر است:
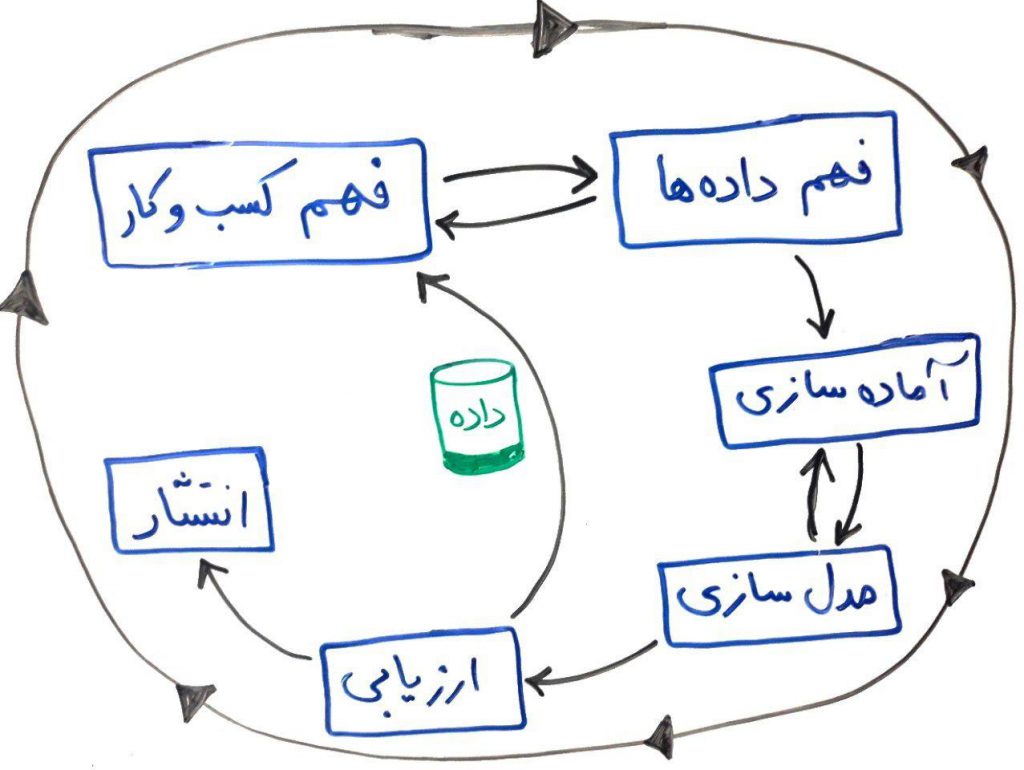
همانطور که مشاهده میکنید این فرآیند به صورت چرخشی و تکراری انجام میشود. برای مثال اگر در مرحلهی «فهم داده» دچار مشکلی شدید به عقب برمیگردید و «کسب و کار را واکاوی» میکنید و یا اگر «مدلسازی» خوبی انجام ندادید، به عقب برگشته و در مرحلهی «آمادهسازی دادهها» تجدید نظر میکنید. و یا اگر مدل شما بعد از «ارزیابی»، کیفیت مناسبی نداشت میتوانید به مرحلهی اول برگشته و دوباره از «فهم کسب و کار» شروع کنید.
برای درک بیشتر، در ادامه مثالی کوتاه در حوزهی بانکداری مبتنی بر روش کریسپ (CRISP) میآورم. فرض کنید میخواهید «فرآیند صلاحیت وام دادن» به متقاضیان وام را در یک بانک، به صورت هوشمند انجام دهید. این مثال را در درس طبقهبندی دادهها نیز آوردهام. در مرحلهی اول به سراغ شناخت حوزهی بانک، فرآیندهای موجود در بانک جهت اخذ وام و ویژگیهای مختلف وام گیرنده و محل اعتبار وام میروید. بعد از آن به سراغ دادههای موجود رفته و دادهها را بررسی میکنید. برای مثال ممکن است متوجه شوید که در دادهها کم و کاستی وجود دارد. مثلاً برخی از متقاضیان وام سن خود را به درستی وارد نکردهاند. ولی تصویر شناسنامهی آنها موجود است. میتوانید از تصویر شناسنامهی آنها سن را استخراج کنید (که خود یک پروژهی دیگر است) و یا کلاً ویژگی سن را از میان دادهها حذف کنید. بعد از آن به سراغ پیش پردازش بر روی دادهها میروید و دادهها را تمیز میکنید. سپس مدل طبقهبندی را بر روی این دادهها میسازید تا الگوریتم یاد بگیرد که به چه اشخاصی وام بدهد و به چه اشخاصی وام ندهد (با توجه به ویژگیها یا ابعاد آنها). بعد از آن مدل را با استفاده از معیارهای مختلف ارزیابی میکنید و در صورتی که کیفیت ارزیابی خوب بود، با کمک برنامه نویسان نرم افزاری منتشر میکنید که میتواند ورودی را از یک منبع داده بخواند، و بر اساس آن تشخیص دهد که آیا شخصِ جدیدِ متقاضی وام، صلاحیت دریافت وام را دارد یا خیر. در کل این فرآیند را نیز میتوانید همواره بهبود بخشید و دوباره از اول بازنگری را بر روی مراحل مختلف انجام داده و نسخههای جدیدتر نرم افزار را منتشر کنید.

- ۱ » دادهکاوی (Data mining) چیست؟
- ۲ » یادگیری ماشین (Machine Learning) چیست؟
- ۳ » تفاوت هوش مصنوعی، یادگیری ماشین، دادهکاوی، یادگیری عمیق و علم داده
- ۴ » طبقهبندی (Classification) چیست؟
- ۵ » خوشهبندی (Clustering) چیست؟
- ۶ » تفاوت طبقهبندی (Classification) و خوشهبندی (Clustering)
- ۷ » منظور از دادههای آموزشی (Training Sets) در طبقهبندی چیست؟
- ۸ » سیستم توصیه گر (Recommendation System) چیست؟
- ۹ » کاربرد دادهکاوی و یادگیری ماشین در پردازش متن (Text Processing)
- ۱۰ » معرفی چند نرم افزار کاربردی برای عملیات دادهکاوی
- ۱۱ » ویژگی (Feature) یا همان بُعد (Dimension) در دادهکاوی چیست؟
- ۱۲ » بررسی چند الگوریتم یادگیری ماشین (Machine Learning)
- ۱۳ » یادگیری دستهای (Batch Learning) و یادگیری برخط (Online Learning)
- ۱۴ » یادگیری فعال (Active Learning) در یادگیری ماشین
- ۱۵ » انتخاب ویژگی (Feature Selection) چیست؟
- ۱۶ » تفاوت داده ساختاریافته (Structured) با غیرساختاریافته (Unstructured) چیست؟
- ۱۷ » منظور از متغیر وابسته (Dependent) و مستقل (Independent)
- ۱۸ » مجموعه دادههایی با ابعاد زیاد (High Dimensional)
- ۱۹ » مجموعه دادهی نامتوازن (Imbalance) چیست؟
- ۲۰ » فرآیند کریسپ (CRISP) جهت انجام پروژههای دادهکاوی
- ۲۱ » رانش یا گذار در دادهها (Data Drift)
عالی بود موفق باشید همیشه
مثل همیشه عالی و روان
سلام عالی بود
مطالب بسیار عالی و با بیان قابل فهم برای سطوح مختلف کاربران مطرح شده اند
با سلام.
بسیار کاربردی بود. در عین اینکه وارد مباحث فنی نشدید بسیار مدبرانه کل داده کاوی رو آموزش دادید. نه اینکه با خوندن این مجموعه مطالب داده کاو بشویم ولی با خوندن این مجموعه کاملا متوجه می شوین که داده کاوی چیه و چه کاربردی داره.
از بابت زحماتی که کشیدید تشکر می کنم
مطالبی کلیدی که با زبانی ساده بیان شده و به فهم موضوع بسیار کمک میکنه ، ممنون از نویسنده و تیم تولید کننده
بسیار عالی و قابل فهم. سپاس