

در دروس قبلی از دورهی جاری با دادههای پرت (Outliers) و چندین الگوریتم جهت شناسایی این دادهها آشنا شدیم. این الگوریتمها معمولاً دادههایی را به عنوانِ دادهی پَرت انتخاب میکنند که آن داده، جدا از دادههای دیگر باشد یا به نوعی جدا از دادههای دیگر رفتار کنند. اگر درس ویژگی یا همان بُعد و درس دادههایی با ابعادِ بالا را خوانده باشید، متوجه میشوید که برخی از مجموعهی دادهها در ابعادِ بسیار زیادی قرار دارند. برای مثال ممکن است یک مجموعهی دادهی تصویری، ۱میلیون ویژگی (بُعد) داشته باشد که این، کار را برای الگوریتمهای مختلف در دادهکاوی سخت میکند. برای شناسایی دادههای پرت در این دست از مسائل که ابعاد زیادی دارند، میتوان از الگوریتمهایی مانند ABOD که در این درس به آن میپردازیم استفاده کرد.
حتماً از درس ویژگی یا بُعد چیست یاد گرفتهاید که چگونه میتوان دادهها را بر روی چند بُعد نگاشت کرد. فرض کنید دادههای ما مانند شکل زیر شامل تعدادی از دانشآموزان در مقطع سوم دبستان باشد که بر اساس قد و وزن بر روی محور مختصاتِ دوبُعدی رسم شدهاند. ما میخواهیم الگوریتمی بسازیم که نقطهی A که یک دادهی پرت (یک دانشآموز دارای ویژگیِ غیر طبیعی از لحاظ قد و وزن متناسب با همکلاسیهای خود) هست را شناسایی کنیم. این شخص قد خیلی بلندی دارد و وزن آن به نسبت قدش، نرمال نیست:
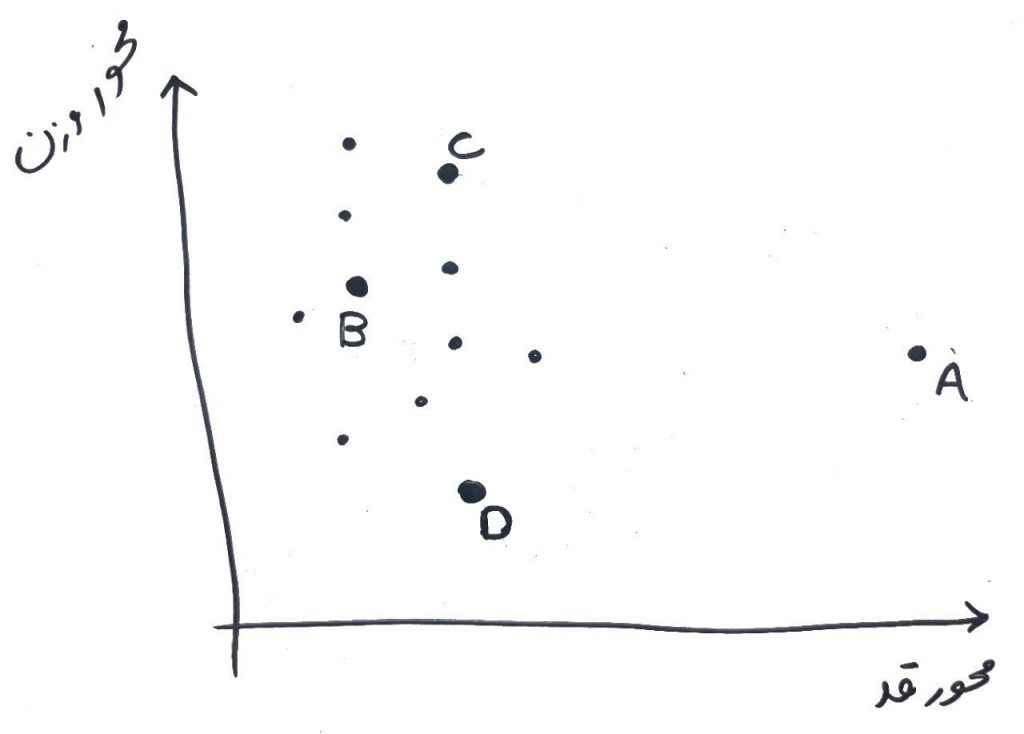
الگوریتم ABOD که مخفف Angle Base Outlier Detection (شناسایی دادههای پرت بر اساس زاویه) هست، به اینگونه عمل میکند که برای هر نقطه در فضا (یعنی هر نمونه در شکلِ بالا) زاویهی آن نمونه را با بقیهی نمونهها اندازهگیری میکند. اگر اختلاف این زاویههای اندازهگیری شده برای یک نقطه زیاد بود، به این معنی است که این داده در میان دادههای دیگر قرار دارد و نمیتواند دادهی پرت باشد ولی اگر اختلاف زاویهها برای این نقطه با نقاط دیگر با هم کم باشد، این داده احتمالاً یک دادهی پرت است. برای فهم دقیقتر به شکل زیر نگاه کنید:
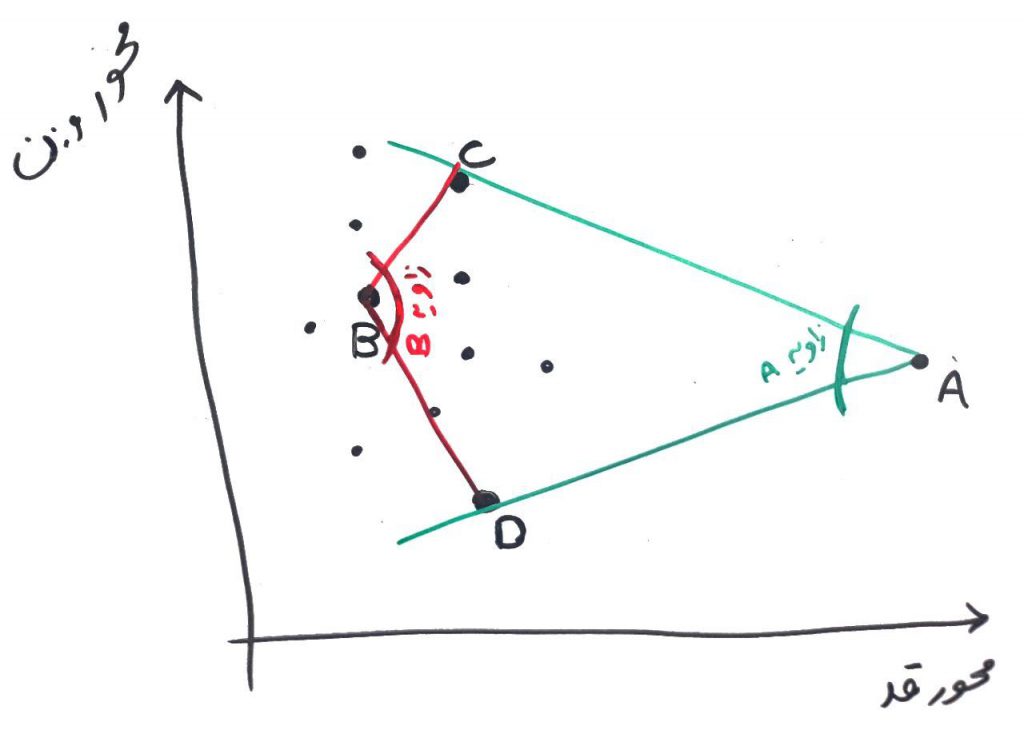
همانطور که میبینید دادهی A یک دادهی پرت است در حالیکه دادهی B اینگونه نیست و دادهی نرمال در میانِ دادههای دیگر است. زاویهی بین A که با خط سبز نشان داده شده است را نگاه کنید. الان زاویهی A با توجه به نقاط C و D اندازهگیری شده است. همانطور که میبینید این زاویه کم است. حالا اگر زاویهی نقطهی A را با همهی نقاطِ دیگر (به صورت زوجِ دوتایی-مثلا A با CوD) اندازهگیری کنیم، متوجه میشویم که معمولاً زاویهی همهی آنها نزدیک به هم هستند (چون نقطهی A دورتر از بقیهی نقاط است). اما نقطهی B فرق میکند. همانطور که میبینید زاویهی این نقطه با توجه به نقاط دیگر خیلی تفاوت میکند. در بعضی جاها خیلی کم میشود و بعضی جاها خیلی زیاد (تفاوت زاویهی ایجاد شده توسط B را با نقاط DوC و بقیهی نقاط مشاهده کنید). به این ترتیب میتوان تشخیص داده که نقطهی B در میانِ دادهها قرار دارد ولی نقطهی A با دادههای دیگر فاصلهی زیادی ایجاد کرده است. اینگونه است که میتوان نمونهی A را به عنوانِ یک نمونه دادهی پرت شناسایی کرد.
برای محاسبهی دادههای پرت در الگوریتم ABOD برای هر نقطه (نمونه) یک امتیاز حساب میشود و به آن ABOF میگویند که مخفف Angle Base Outlier Factor میباشد. نحوهی محاسبهی ABOF به اینصورت است که مثلاً نقطهی A انتخاب شده و برای تمامی نقاطِ باقی ماندهی دیگر، یک سهضعلی با نقطهی A رسم میکنیم و زاویهی بین نقطهی A را با دو نقطهی دیگر محاسبه میکنیم. این کار را برای تمامی زوج نقطههای موجود (به جز خودِ A) محاسبه میکنیم. مانند شکل زیر (برخی از زاویهها برای A و B رسم شدهاند):
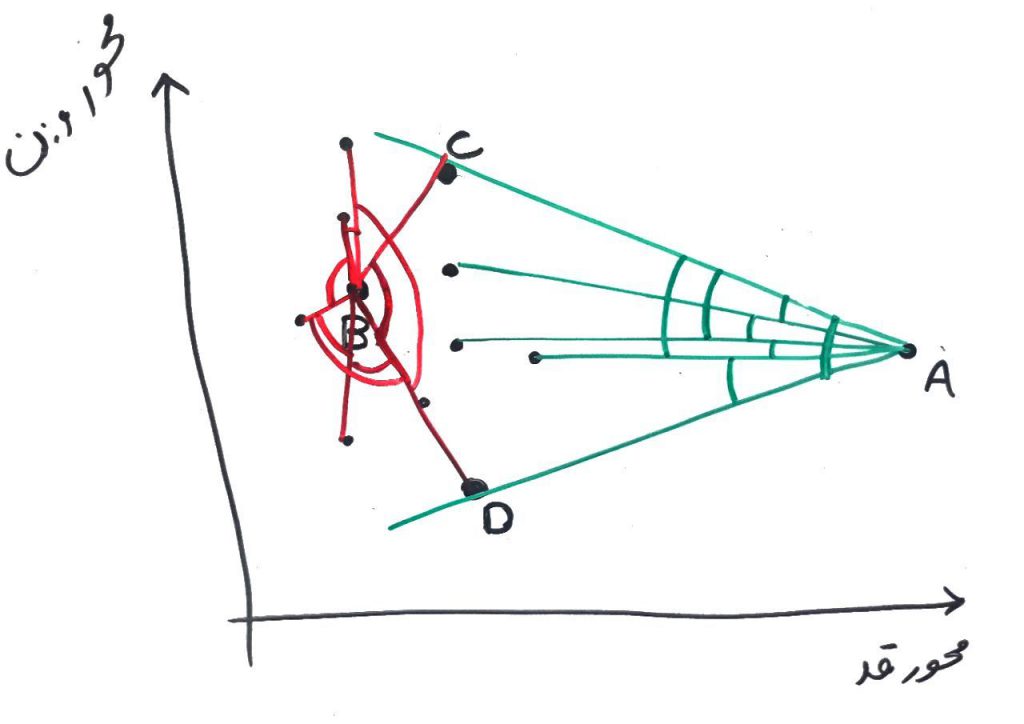
البته در الگوریتم ABOD هر چقدر فاصلهی بین نقاطِ تشکیل دهندهی زاویه با نقطهی A بیشتر باشد، یک وزنِ کمتر به آنها خواهیم داد که این کار به تشخیص دادهی پرت در ناحیهی دورتر نیز کمک میکند. به این صورت امتیاز ABOF برای یک نقطه محاسبه میشود.
در نهایت با محاسبهی ABOF برای تمامی نقاط، میتوانیم نقاطِ (نمونهها) پرت را پیدا کنیم. مقدار کمتر برای این فاکتور (ABOF) برای هر نمونه نشان دهندهی کم بودن میزان واریانس بین تمامیِ زوج نمونهها با نمونهی مورد نظر است. یعنی مثلاً در شکلِ بالا، نقطهای مانندِ A به احتمال بیشتری دادهی پرت است زیرا زاویهای که این نقطه با بقیهی نقاط تشکیل میدهد، تقریباً نزدیک به هم هستند. ولی مثلاً نقطهی B را مشاهده کنید، این نقطه زاویههایی با اندازههای مختلف (بعضی کوچک و بعضی بزرگ) را با نقاط دیگر تشکیل میدهد، یعنی زاویههای تشکیل شده در نقطهی B واریانس زیادی دارد و به تبع آن ABOF بالایی هم پیدا میکند، پس این نقطه نمیتواند یک دادهی پرت باشد.
یکی از مزایای الگوریتم ABOD این است که نیاز به پارامترهای اولیه توسط کاربر ندارد. در واقع این الگوریتم Parameter Free میباشد.

- ۱ » کاربرد یافتن دادههای پرت (Outlier Detection) در دادهکاوی
- ۲ » تستهای آماری (Statistical Test) جهت تشخیص دادههای پرت
- ۳ » محاسبهی دادههای پَرت با استفاده از z-score
- ۴ » الگوریتم جنگل ایزوله (Isolation Forest) جهت تشخیص دادههای پرت
- ۵ » کاربرد الگوریتم DBSCAN در تشخیص دادههای پَرت (Outliers)
- ۶ » الگوریتم ABOD جهت تشخیص دادههای پرت از طریق زاویه
سلام و با سپاس از مطالب شیواتون در این مبحث داده های پرت