

ایدهی جنگل، در بین الگوریتمهای دادهکاوی و یادگیریماشین ایدهی مرسومی است. برای مثال الگوریتمِ جنگلِ تصادفی (Random Forest) را از دورهی الگوریتمهای طبقهبندی به یاد بیاورید. ایدهی اصلی در الگوریتمهایی که با نام جنگل شناخته میشوند این است که این الگوریتمها از تعدادی درخت (مانند درختِ تصمیم-Decision Tree) استفاده میکنند و با کمکِ این درختان به یک جمعبندیِ کلی میرسند. در الگوریتمِ جنگلِ تصادفی، دیدیم که این ایدهی کلی، به این صورت بود که میتوانست طبقهبندی (Classification) را بر روی مجموعهی داده انجام دهد.
اما ایدهی الگوریتمِ جنگلِ ایزوله یا همان Isolation Forest کمی فرق میکند. این الگوریتم که برای به دست آوردنِ دادههای پَرت به وجود آمده است میتواند دادههایی را که از دادههای دیگر جدا (و تنها) هستند شناسایی کرده و به عنوان دادههای پَرت (Outliers) علامت بزند.
برای شروع، شکل زیر را نگاه کنید (این شکل، دادههای افراد مختلف است که بر اساس قد و وزن بر روی یک تصویرِ دو بُعدی نگاشت شده اند-حتماً درسِ ویژگی یا بُعد چیست را خوانده باشید):
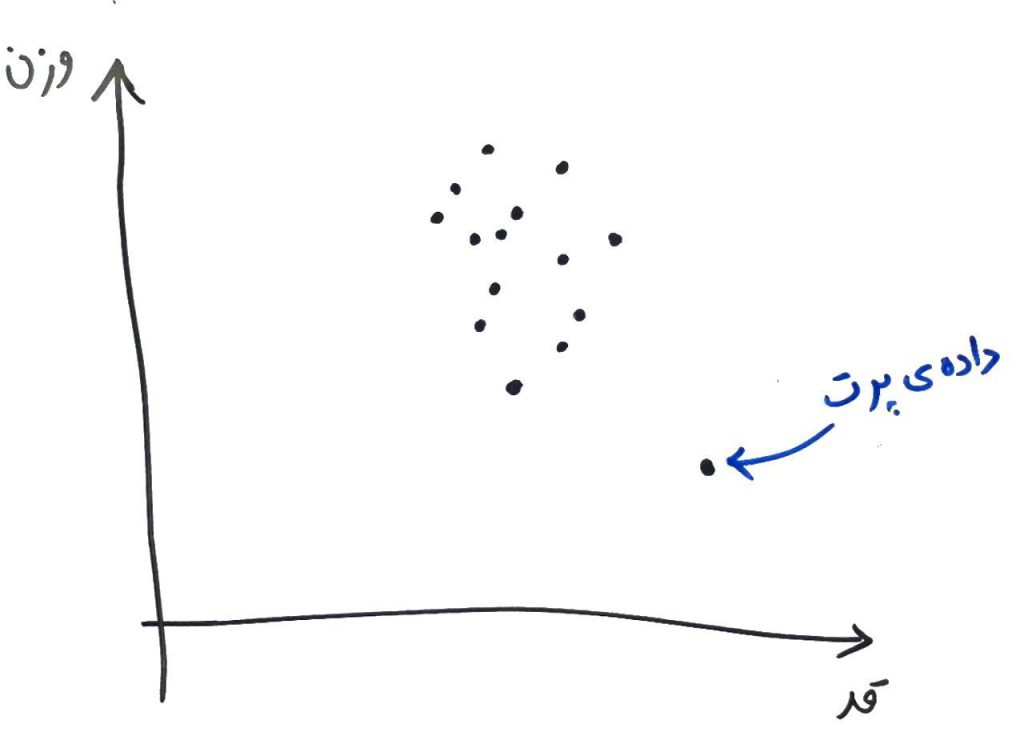
الگوریتمِ جنگلِ ایزوله (Isolation Forest) یک ویژگی (یک بُعد) را به صورت تصادفی انتخاب میکند و سپس یک مقدارِ تصادفی بین کمینه (Minimum) و بیشینهی (Maximum) آن انتخاب کرده و با یک خطِ جداساز آن بُعد را جدا میکند. چیزی مانندِ شکل زیر:
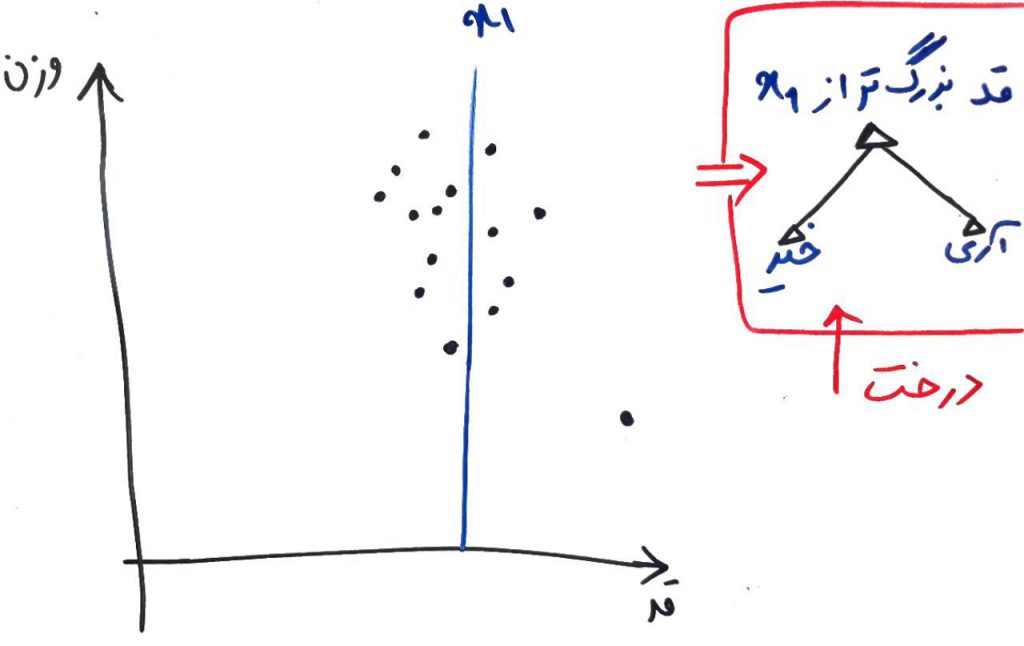
همانطور که میبینید این جداساز به صورتِ تصادفی، ویژگیِ قد را انتخاب کرده و با یک خطِ تصادفی (در اینجا خط x1)، این ویژگی را به دو قسمت تبدیل کرد. با این کار میتوان یک درختِ دودویی ساخت که برای جداکردنِ دادهها مطابقِ خطِ x1 کار میکند. درخت ایجاد شدهی فرضی را در سمت راست تصویر بالا میبینید. این درخت در ریشه، دادهها را به دو قسمت تقسیم میکند، دادههایی که از نظرِ قد بزرگتر از x1 هستند و دادههایی که از نظرِ ویژگیِ قد کوچکتر از x1 هستند.
حال دوباره الگوریتم، یک ویژگی (بُعد) تصادفی را انتخاب میکند. و دوباره خطی برای جداسازیِ آن ویژگی به صورت تصادفی میکشد. در شکلِ زیر ۳بار اینکار را انجام دادیم تا درخت کمی توسعه یابد:
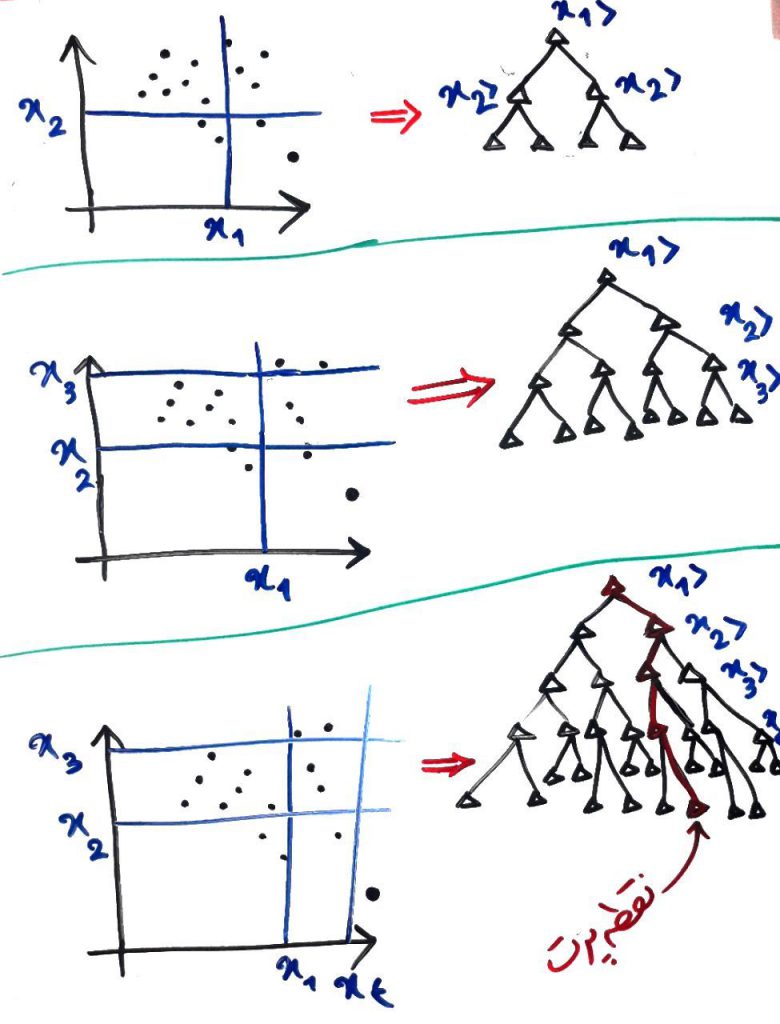
در شکلهای بالا هر بار، یک ویژگی به صورتِ تصادفی انتخاب شد و آن ویژگی با یک خطِ جداکننده، به قسمتهای مختلفی تقسیم شد تا درختِ نظیر به صورت درختهای سمت راستِ آن تولید شود. در آخرین شکل مشاهده میکنید که نقطهی پرت (پایین سمت چپ) به صورت یک نقطهی جدا (ایزوله) تنها مانده است. در واقع ما آنقدر این تقسیمبندی را انجام دادیم تا بلاخره یک نقطه، تنهای تنها، در یکی از محوطهها پیدا شد. درختِ متناظرِ سمت راست را نگاه کنید. این درخت دربارهی نقطهی پرت به پایان (برگ) رسیده است و دیگر نمیتوان آن را ادامه داد. البته یک درخت را میتوان اینقدر ادامه داد که تمامی تقاط بلاخره در یک محوطهی ایزوله (تنها) شوند. این نقطهی پرت همانطور که میبینید از x1بزرگتر، از x2کوچکتر، از x3کوچکتر و از x4بزرگتر است (با خطِ قرمز رنگ بر روی درختِ آخر نمایان است). در واقع ما اینقدر ویژگیِ تصادفی انتخاب و تقسیم میکنیم که نقاط به صورتِ تنها در یک خانه قرار بگیرند (اگر درسِ ویژگی و بُعد را خوانده باشید میدانید که معمولاً ابعاد بسیار بیشتر از ۲تا است). پس برای به دست آوردن نقاط تنها بایستی درخت را خیلی بیشتر از این ادامه دهیم. در اینجاست که به ایدهی اصلیِ جنگلِ ایزوله (Isolation Forest) میرسیم.
با روشِ تقسیمبندیِ درختها در جنگلِ ایزوله، دادههای پَرت، سریعتر از سایرِ نقاط (دادهها) تنها (ایزوله) میشوند.
اگر بخواهیم از منظرِ درخت بگوییم، دادههای پَرت به ریشه (بالای) درخت نزدیکتر هستند زیرا این درختها، نقاطِ ایزوله را زودتر از سایرین پیدا میکنند و آنها را ایزوله (تنها) میکنند.
مانندِ این است که یک شیر به دنبال دستهای از گاوها باشد. این شیر معمولاً گاوهایی را که تنها باشند زودتر شناسایی و شکار میکند زیرا گاوهایی که با هم یک جمعیت را تشکیل داده باشند، سختتر قابل شکار هستند!
برای درکِ بهتر دوباره شکل اولِ این درس را ببینید. فرض کنید در شکل زیر میخواهیم نقطهی وسطی را ایزوله (تنها) کنیم (با توجه به خاصیت تصادفی بودن انتخاب ویژگی و انتخابِ خطِ جداکننده). مشاهده میکنید که نیاز است تا خطهای زیاد (و به تبعِ آن توسعهی بیشتر درخت) کشیده شود تا بتوان یک نقطه که در مرکز یا در جایی شلوغ قرار دارد را به عنوانِ نقطهی ایزوله از بقیه جدا کرد. در واقع هر چقدر یک داده، بیشتر پَرت باشد، زودتر توسطِ درختها پیدا میشود.
برای تولیدِ جنگل بایستی چند درخت (مثلا ۱۰۰۰درخت) ساخته شود و هر درخت مشخص میکند که کدام نقاط زودتر ایزوله شدند (دادهی پَرت هستند)، و جنگلِ ایزوله هم با توجه به این درختها و تصمیماتشان، تصمیمِ نهایی را گرفته و به هر نقطه (به صورت میانگین) یک امتیاز بین ۰ تا ۱ میدهد. هر چقدر این امتیاز به ۱نزدیکتر باشد، این نقطه به احتمال بیشتری، دادهی پَرت است. این امتیاز بر اساس فرمول زیر محاسبه میشود:
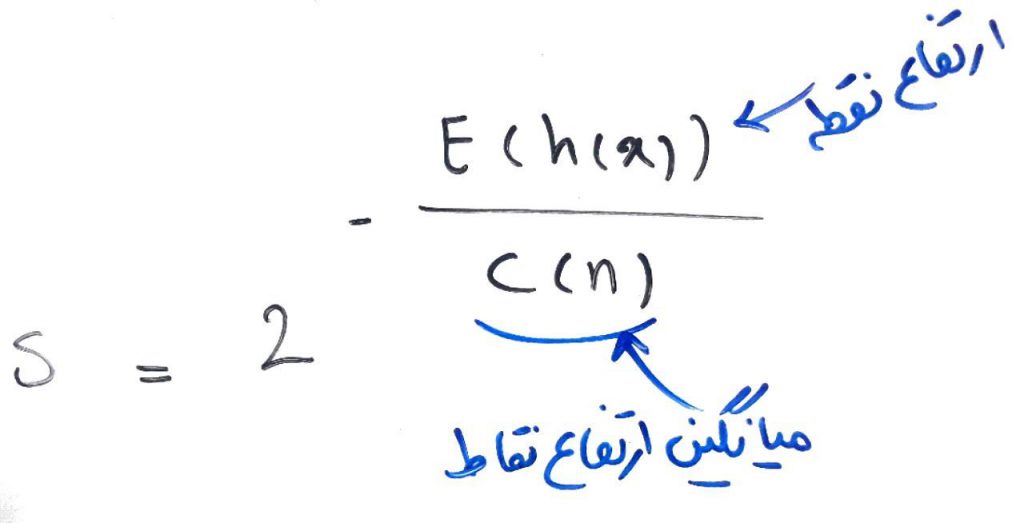
در واقع هر چقدر یک نقطه در درختهای مختلف، زودتر ایزوله (تنها) شود، صورتِ کسر کوچکتر شده و در نتیجه امتیازِ آن به یک (۱) نزدیکتر میشود.

- ۱ » کاربرد یافتن دادههای پرت (Outlier Detection) در دادهکاوی
- ۲ » تستهای آماری (Statistical Test) جهت تشخیص دادههای پرت
- ۳ » محاسبهی دادههای پَرت با استفاده از z-score
- ۴ » الگوریتم جنگل ایزوله (Isolation Forest) جهت تشخیص دادههای پرت
- ۵ » کاربرد الگوریتم DBSCAN در تشخیص دادههای پَرت (Outliers)
- ۶ » الگوریتم ABOD جهت تشخیص دادههای پرت از طریق زاویه
متشکرم از توضیح شفاف و قابل فهم
تو فرمول نباید میانگین ارتفاع نقاط همون صورت کسر باشه؟