

در درسِ گذشته در مورد تِستهای آماری و ایدهی کلیِ آنها در تشخیصِ دادههای پَرت سخن گفتیم. به صورت خلاصه گفتیم این تستهای آماری (Statistical Tests) فرض میکنند دادهها از یک توزیعِ احتمالی-مثلا یک الگوی مشخص مانند گوسی- پیروی کرده و سپس آن دادههایی را که از این الگو (توزیعِ احتمالی) پیروی نکنند به عنوانِ دادهی پَرت در نظر میگیرند. در این درس میخواهیم z-score که یکی از این روشها است-و به نظر معروفترین روش هم میرسد- را با یکدیگر یاد بگیریم.
اجازه بدهید اینبار یکراست به سراغِ فرمول z-score در یک مجموعهی داده برویم:
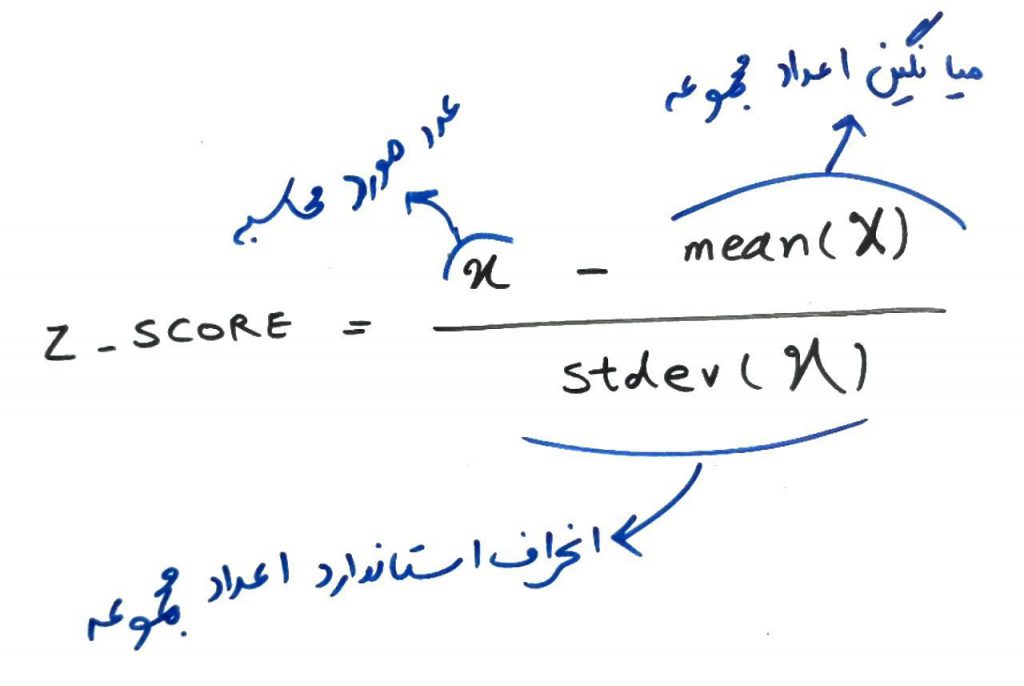
فرمول ساده است. برای اینکه z-score را برای یک عدد در یک مجموعه محاسبه کنیم، باید آن عدد را منهای میانگینِ آن مجموعه کرده و سپس بر انحراف استاندار (انحراف معیار یا همان Standard Deviation) تقسیم کنیم. در واقع z-score باعث میشود که هر کدام از عناصرِ مجموعهی داده، به یک عددِ دیگر تبدیل شوند که میانگینِ آن اعدادِ تبدیل شده صفر (۰) و انحراف استاندارد آنها یک (۱) است. اجازه بدهید دوباره بگوییم: اعدادِ مجموعهی قبلی به اعدادی تبدیل میشوند که میانگینِ آنها ۰ است و انحرافِ معیارِ آن ۱.
برای درکِ بهتر، شکل زیر که شامل یک مجموعه هست را در نظر بگیرید:
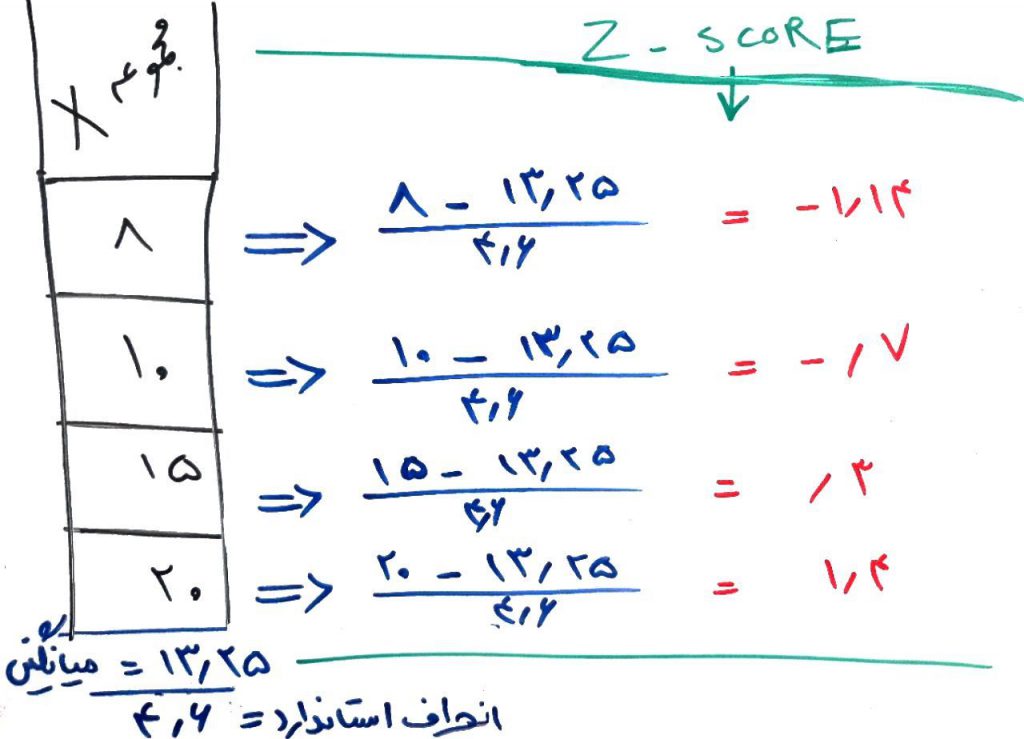
همانطور که میبینید یک مجموعهی داده داریم شامل ۴عنصر. فرض کنید اینها سنِ افرادِ مختلف هستند که در یک مجموعهی داده در کنار هم قرار گرفتهاند. میانگین این اعداد برابر ۱۳/۲۵ شده است و انحراف استاندارد آن برابر ۴/۶ است. در سمتِ راستِ تصویر با اعمالِ فرمولِ z-score هر عدد را به عددی که خروجیِ z-score میداد تغییر دادیم. اگر میانگینِ اعدادِ سمتِ راست را محاسبه کنید میبینید که عددِ صفر (۰) میشود. انحراف استانداردِ آنها نیز برابرِ یک (۱) میشود.
تا اینجا فقط در موردِ z-score صحبت کردیم. حال چگونه دادههای پَرت را با استفاده از خروجیِ z-score محاسبه کنیم؟ اگر درسِ قبل را خوانده باشید، در آنجا گفتیم که مدلهای تستِ آماری یک فرض در موردِ دادهها دارند. z-score هم فرض میکند که دادهها یک توزیع گوسی (مانند درسِ قبل) دارند. z-score با تبدیلِ دادهها و فرضِ اینکه دادهها یک توزیع گوسی یا همان نرمال با میانگینِ ۰ و انحرافِ استانداردِ ۱ دارند، آنها را میشناسد. باز هم مثالِ درسِ قبل را اینجا میآوریم. فرض کنید در یک کلاسِ ۴۰نفره هستید، که هر کدام از دانشجویانِ این کلاس، یک قدِ مشخص (به سانتیمتر) دارند. نمودار زیر نشان میدهد که از نظرِ قد در بازههای مختلف، چند نفر (تعداد) وجود دارند. شکل زیر را نگاه کنید:
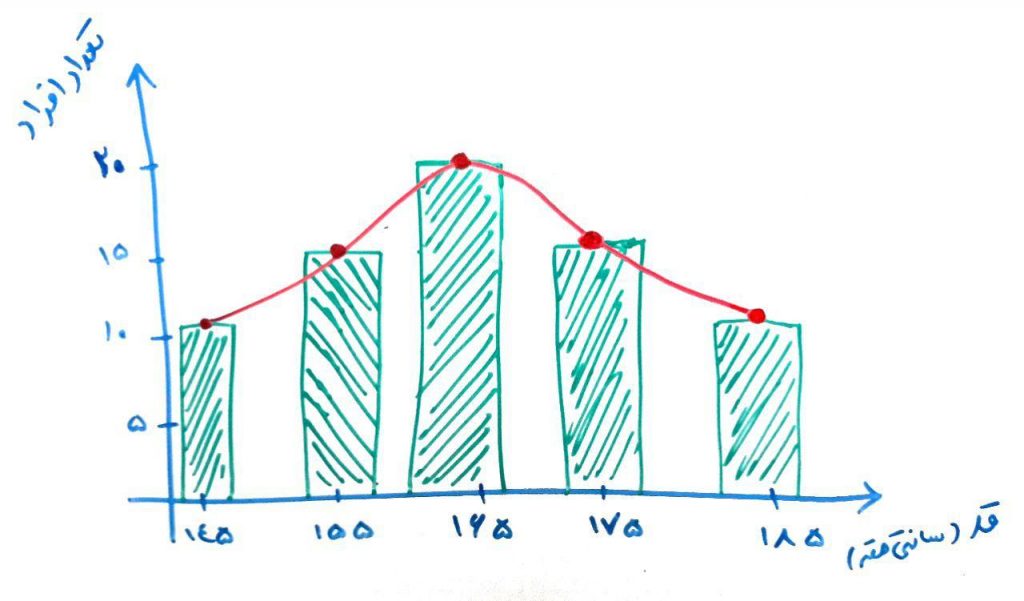
برای مثال، تعدادِ ۲۰نفر، قدی در محدودهی ۱۶۵سانتیمتر دارند و به همین صورت برای بقیهی قدها میتوانید تعداد مشخص را مشاهده کنید. این یک نوع توزیع گوسی (Gaussian Distribution) است. اگر اعدادِ مجموعهی ۴۰نفرهی کلاس را با z-score به بازهای دیگر تغییر دهیم چیزی مانندِ شکل زیر میشود:
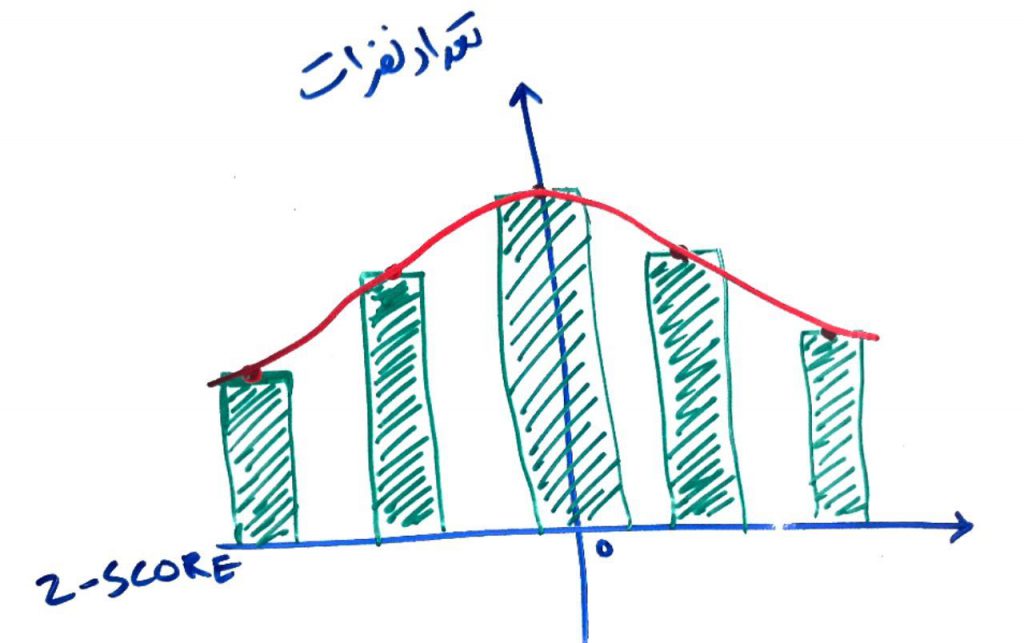
همانطور که میبینید میانگینِ ۰ و انحراف استانداردِ ۱ در این نمودار مشخص است. حال برای اینکه دادههای پَرت را تشخیص بدهیم میتوانیم از مجموعهی داده، آنهایی که امتیازِ z-score آنها بیشتر از ۳ و کمتر از ۳- باشد را از بینِ دادهها حذف کنیم. معمولاً برای تشخیص دادههای پَرت از طریق z-score عددِ ۳ و ۳- یا چیزی در همین بازه را قرار میدهند (که این نیز پایهی آماری در توزیعِ گوسی دارد). مثلا اگر قدِ شخصی ۲۵۰ بود، احتملاً با تبدیل z-score این عدد به عددی مانندِ ۴ تبدیل میشود و چون بزرگتر از ۳ بود، شخص با قدِ ۲۵۰سانتیمتر از بین دادهها حذف میشد. اگر بخواهیم از روی شکل توضیح دهیم، یک سری دادهها که در گوشهی توزیع گوسی قرار میگیرند، حذف میشوند:
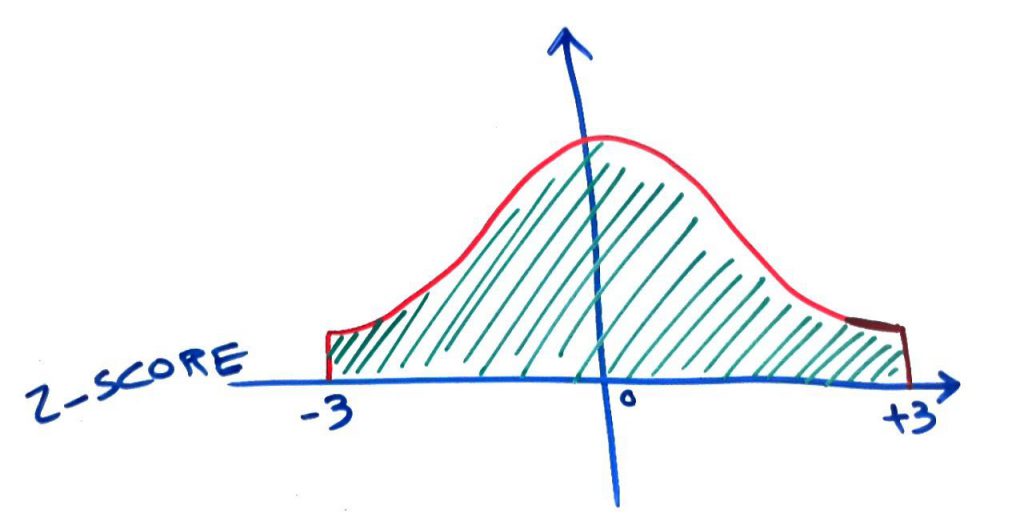
در تصویرِ بالا مشاهده میکنید که اعدادِ در بازهی ۳- و ۳+ نگهداشته شده اند و آنهایی که بیشتر یا کمتر از این بازه بودهاند، از بین رفتهاند. به این ترتیب z-score میتواند دادههای پَرت یا همان outliers را شناسایی و حذف کند.

- ۱ » کاربرد یافتن دادههای پرت (Outlier Detection) در دادهکاوی
- ۲ » تستهای آماری (Statistical Test) جهت تشخیص دادههای پرت
- ۳ » محاسبهی دادههای پَرت با استفاده از z-score
- ۴ » الگوریتم جنگل ایزوله (Isolation Forest) جهت تشخیص دادههای پرت
- ۵ » کاربرد الگوریتم DBSCAN در تشخیص دادههای پَرت (Outliers)
- ۶ » الگوریتم ABOD جهت تشخیص دادههای پرت از طریق زاویه