

تستهای آماری، از سادهترین و در عین حال پرکاربردترین آزمایشات، جهت تشخیصِ یک دادهی پَرت میباشد. فرض کنید شما معلم هستید و معمولاً انتظار دارید ۵۰درصد دانشجویان در یکی از کلاسهایتان نمرهی بالای ۱۵ بگیرند، ۴۰درصد از آنها نمرهای بین ۱۲ تا ۱۵ گرفته و ۱۰درصد آنها هم نمرهای بین ۱۰ تا ۱۲ بگیرند. پس در واقع شما انتظار ندارید که دانشآموزی، مثلاً نمرهی ۳از شما گرفته باشد. اگر چنین باشد، انتظارِ شما برآورده نشده و این دانشآموز یک نمرهی غیر طبیعی به دست آورده است و بایستی بررسی شود که چرا این نمره را آورده است. در واقع این دانشآموز اینجا یک دادهی پَرت بوده است زیرا انتظار شما را برآورده نکرده است.
تستهای آماری یا همان Statistical Tests نیز به همین صورت هستند. آنها یک فرض بر روی دادهها دارند و همچنین انتظار دارند که دادهها از یک توزیع احتمالی (Probability Distribution) پیروی کنند و هر کس از این توزیع احتمالی پیروی نکرد، دادهی پَرت شناخته میشود.
احتمالاً برای برخی از دانشجویان، توزیعهای احتمالی کمی سردرگمکننده باشد. پس اجازه بدهید ابتدا ببینیم توزیعهای احتمالی چیست؟ برای فهمِ بهتر، یکی از توزیعها به نامِ توزیع گوسی یا همان توزیع نرمال را شرح میدهیم. این کار را قبلاً در درس خوشهبندی با Gaussian Mixture Model نیز انجام دادیم.
در آمار و احتمالات، وقتی یک مجموعهی داده در اختیار دارید، بعضاً فرض بر این است که این مجموعهی داده از یک توزیعِ آماری پیروی میکند. مثلا فرض کنید در یک کلاسِ ۴۰نفره هستید، که هر کدام از دانشجویانِ این کلاس، یک قدِ مشخص (به سانتیمتر) دارند. نمودار زیر نشان میدهد که از نظرِ قد در بازههای مختلف، چند نفر (تعداد) وجود دارند. شکل زیر را نگاه کنید:
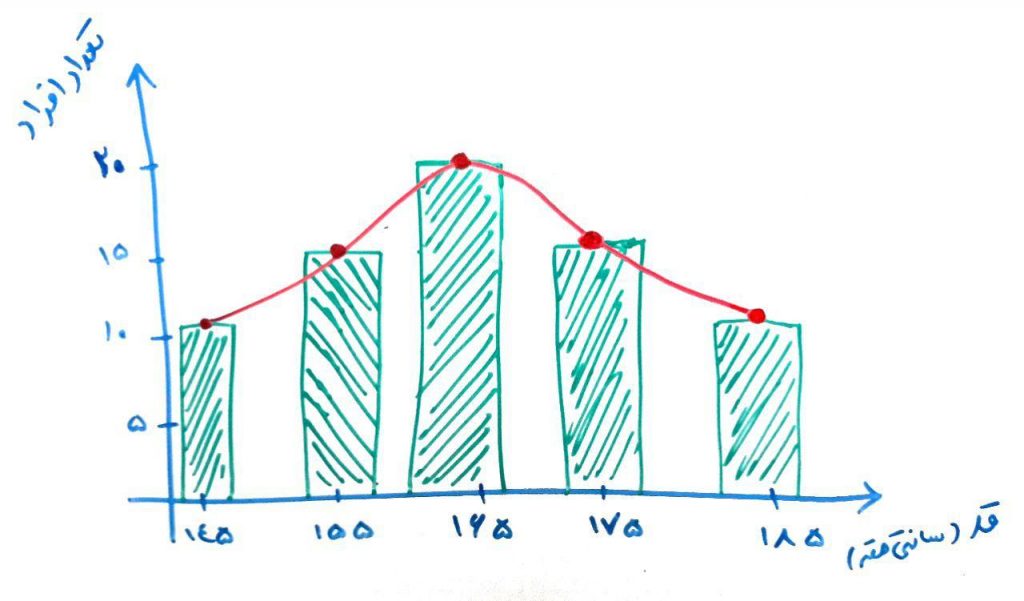
برای مثال، تعدادِ ۲۰نفر، قدی در محدودهی ۱۶۵سانتیمتر دارند و به همین صورت برای بقیهی قدها میتوانید تعداد مشخص را مشاهده کنید. این یک نوع توزیع گوسی (Gaussian Distribution) است. به این معنی که یک عدد مانند ۱۶۵وجود دارد که بیشترین تعداد از آن قد در بین دادههای ما موجود است و هر چه از این قدِ ۱۶۵سانتیمتری فاصله بگیریم، تعدادِ افراد در بازههای دیگر کم و کمتر میشود (تا جایی که به صفر برسد-مثلاً تعدادِ افرادی که قد ۳۰۰سانتیمتر یا ۱۰ سانتیمتر داشته باشند صفر است). اگر توزیعِ گوسی را در نظر داشته باشیم، این توزیع انتظار دارد که دادههای موجود در مجموعهی داده، از این قانون پیروی کنند. دوباره شکلِ بالا را نگاه کنید، اگر شخصی (دادهای) وجود داشت که مثلاً ۲۳۰سانتیمتر بود، همانطور که در تصویر بالا مشخص است، یک حالت غیرِطبیعی به وجود میآمد و در واقع انتظارِ توزیعِ گوسی را برآورده نمیکرد. پس این داده یک دادهی پَرت شناخته میشد.
البته توجه داشته باشید که توزیع گوسی (Gussian) فقط یک نوع-و شاید معروفترین نوع- توزیعهای احتمالی باشد. توزیعهای احتمالیِ بسیار زیادِ دیگری هم وجود دارند که در دورهای جدا به آنها خواهیم پرداخت.
حالا احتمالاً متوجه شدید که در تستهای آماری نیز به همین صورت رفتار میشود. این تستها ابتدا یک فرض برای یک توزیع احتمالی در نظر میگیرد و بعد از آن، دادههایی را که از این فرض تبعیت نکنند، به عنوانِ یک دادهی پَرت حساب میکنند. برای روشنتر شدن موضوع، تصویر زیر را مشاهده کنید:
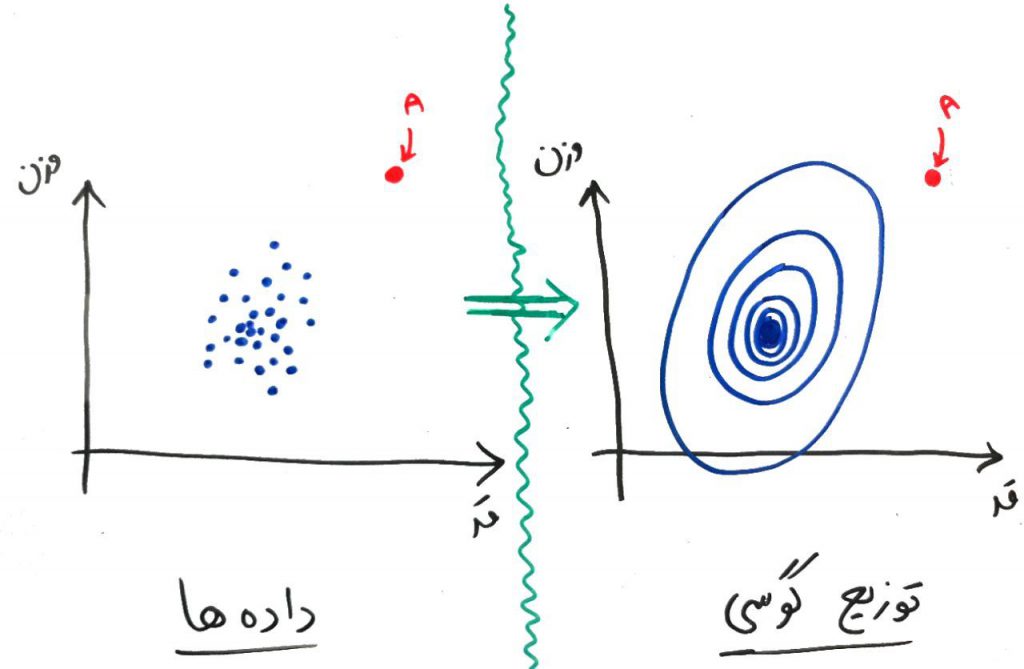
این تصویر دادههای مربوط به قد و وزن دانشجویانِ مختلفِ یک کلاس است (درسِ ویژگی چیست را خوانده باشید). همانطور که میبینید، دادهها از یک توزیعِ گوسی (Gaussian) در دو بُعد تبعیت میکنند. ولی دادهی A را نگاه کنید. این داده به نوعی خارج از این توزیعِ گوسی قرار دارد. پس با این کار میتوان یک داده را به عنوان دادهی پَرت در نظر گرفت چون موردِ انتظارِ توزیع گوسی رفتار نکرده است.
در درسِ بعدی به یکی از الگوریتمها معروف که از توزیع گوسی برای تشخیص دادههای پَرت استفاده میکند میپردازیم.

- ۱ » کاربرد یافتن دادههای پرت (Outlier Detection) در دادهکاوی
- ۲ » تستهای آماری (Statistical Test) جهت تشخیص دادههای پرت
- ۳ » محاسبهی دادههای پَرت با استفاده از z-score
- ۴ » الگوریتم جنگل ایزوله (Isolation Forest) جهت تشخیص دادههای پرت
- ۵ » کاربرد الگوریتم DBSCAN در تشخیص دادههای پَرت (Outliers)
- ۶ » الگوریتم ABOD جهت تشخیص دادههای پرت از طریق زاویه