

شبکهی عصبی پیچشی یا به اختصار CNN که به آن شبکهی عصبی کانولوشنی نیز گفته میشود، نوعی از شبکههای عصبی است که عموماً برای یادگیری بر روی مجموعه دادههای بصری (مانند تصاویر و عکسها) استفاده میشود. از لحاظ مفهوم این شبکهها مانند شبکههای عصبی ساده هستند یعنی از فازهای پیشخور (feed forward) و پسانتشار خطا (back propagation of error) استفاده میکنند ولی از لحاظ معماری تفاوتهایی با شبکههای عصبی ساده دارند. این شبکهها در دستهی یادگیری عمیق قرار میگیرند زیرا لایههای موجود در این شبکهها، زیاد است.
فرض کنید میخواهیم سیستمی هوشمند توسعه دهیم که با مشاهدهی یک تصویر، بتواند حدس بزند این تصویر، تصویرِ یک مرد است یا یک زن. برای این کار نیاز است تا تعدادِ زیادی تصویرِ مرد و زن را به همراه برچسب (label) به یک الگوریتمِ یادگیری ماشین بدهیم تا این الگوریتم بتواند پس از یادگیری از مجموعهی دادهی آموزشی، تصاویرِ جدید را برچسبزنی کند.
این کار با الگوریتمهای کلاسیک و سادهی یادگیری ماشین نیز قابل انجام است ولی امکان دارد این الگوریتمها، دقت بالایی نداشته باشند و با زیاد شدن تصاویر و تعداد پیکسلهای هر تصویر، بیشبرازش (overfit) رخ دهد. برای همین میتوانیم به سراغ یادگیری عمیق و شبکههای عصبی پیچشی برویم که برای حل همین مشکلات بر روی تصاویر ایجاد شده است. یک معماریِ ساده در شبکههای عصبی کانولوشنی برای حلِ مسئلهی تشخیص مرد/زن از تصاویر، به صورت زیر است:
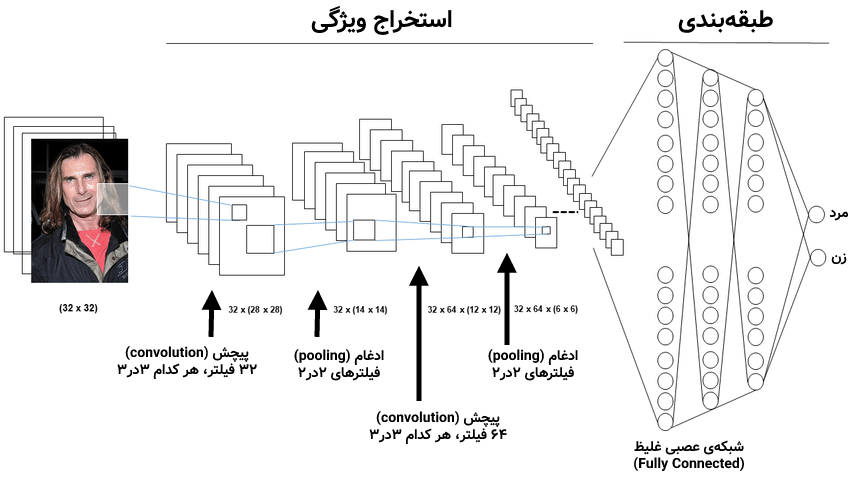
در معماری CNN در شکلِ بالا، سه عنصر وجود دارد. پیچش (convolution) یا کانولوشن، ادغام (pooling) و شبکهی عصبی غلیظ (fully connected) که در ترکیب با یکدیگر این معماری را تشکیل میدهند. اجازه بدهید یکی یکی به سراغ این بخشها برویم و هر کدام را توضیح دهیم.
پیچش یا کانولوشن (Convolution)
به صورت ریاضی، پیچش یا کانولوشن به جمعِ ضربِ نظیر به نظیر دو ماتریس گفته میشود. اما به صورت کاربردی و شهودی، پیچش یا همان کانولوشن باعثِ اعمال یک فیلتر بر روی تصاویر میشود. برای مثال اگر ماتریس اول را یک تصویر فرض کنیم، با اعمال یک تابع کانولوشن، در واقع یک فیلتر بر روی تصویر اعمال کردهایم. چیزی مانند شکل زیر:
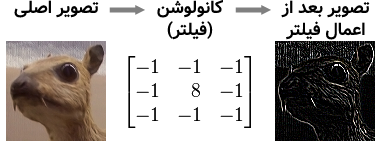
شکل بالا یک فیلتر لبهیاب (edge detector) است که لبههای اشیای موجود در تصویر را شناسایی میکند. برای اعمال این فیلتر بر روی تصویر کافیست ماتریس کانولوشن (فیلتر) را بر روی مقادیر موجود در پیکسلهای تصویر ضرب کرده با یکدیگر جمع کنیم. توجه کنید که این کار بایستی بر روی تمامی پیکسلهای تصویر اصلی انجام شود. در شکل زیر این موضوع قابل مشاهده است:
در تصویر متحرک بالا مشاهده میشود که یک کانولوشن (فیلتر) ۳در۳ بر روی تصویر سمت چپ اعمال شده و نتیجه یک تصویر جدید در سمت راست خواهد شد. توجه کنید که ماتریسِ فیلتر در شکل بالا ۹ پیکسل را میتواند پوشش دهد و هر کدام از مقادیر آن بایستی در پیسکلها ضرب شده و نتیجه با هم جمع شود تا یک پیکسل از تصویر فیلتر شده (شکل سمت راست) ایجاد شود. در شکل زیر این موضوع را مشاهده میکنید:
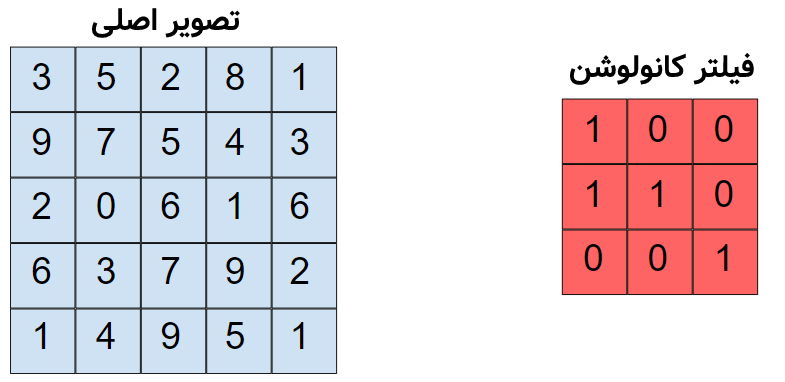
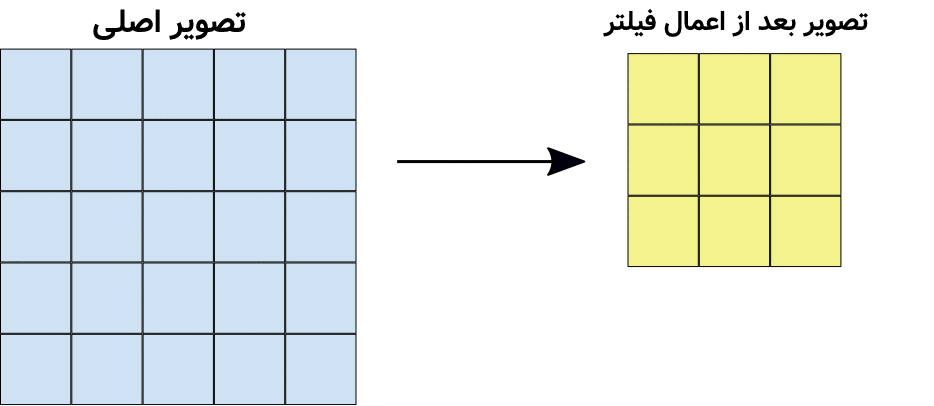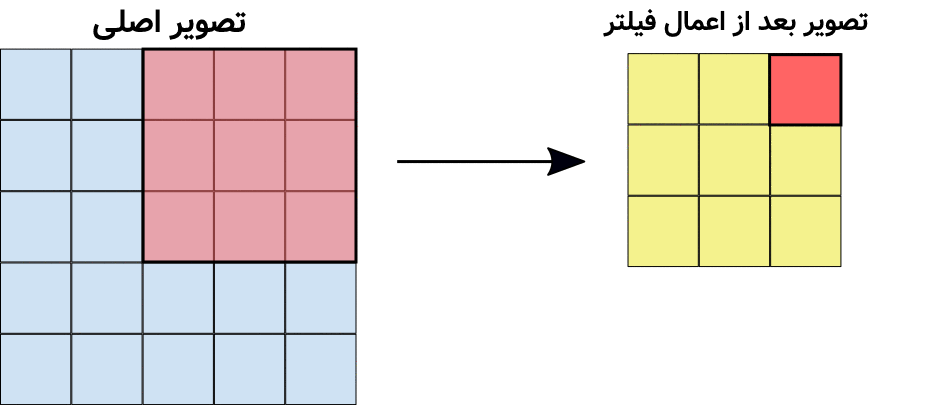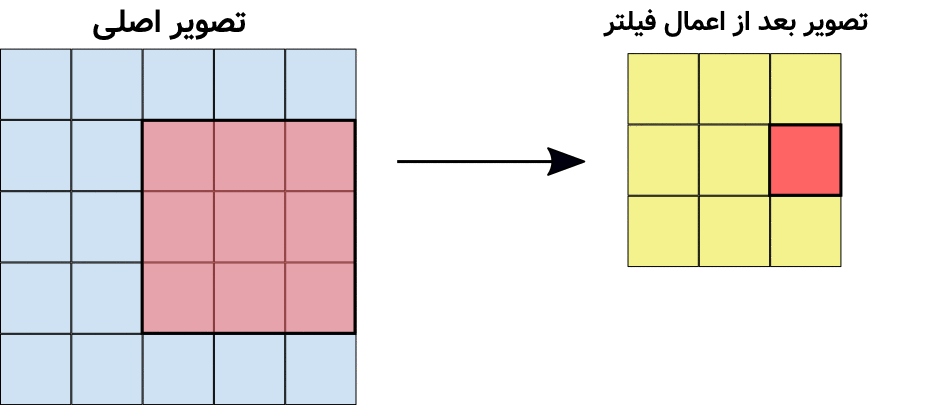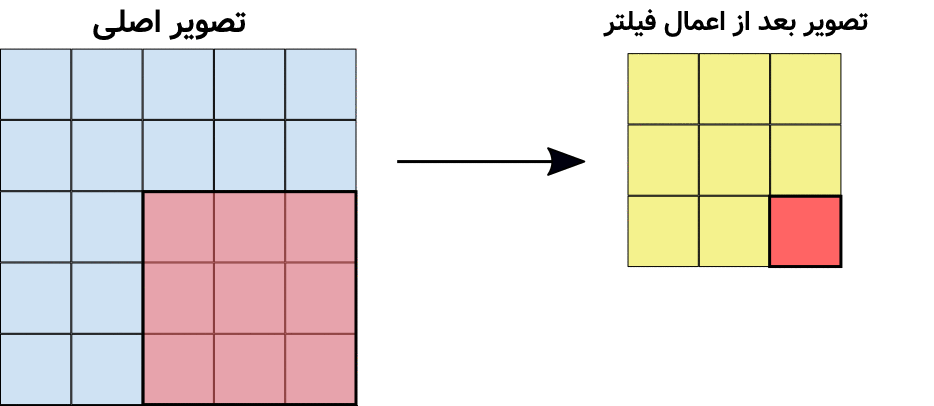
در شکل بالا، تصویر اصلی دارای پیکسلهایی است. فعلاً فرض کنید تصویر سیاه سفید بوده و هر کدام از اعداد داخل پیکسلها میزان روشنایی آن پیکسل را نماش میشود. میخواهیم فیلتر کانولوشنِ سمت چپ را بر روی این تصویر اعمال کنیم:
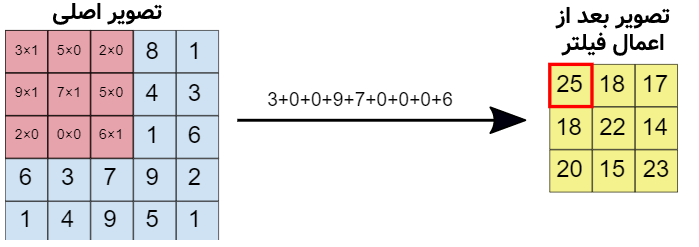
در شکل بالا، فیلتر کانولوشنی را بر روی ۹ پیکسلِ سمت چپ بالای تصویرِ اصلی اعمال کردهایم. حال باید این فیلتر کانولوشنی را مانند تصویر متحرکی که در بالاتر نمایش دادیم، بر روی تصویر اصلی به مقدار یک پیکسل یک پیکسل جابهجا کنیم تا بتوانیم تمامی پیکسلها را یکی یکی در تصویر فیلتر شدهی سمت چپ بسازیم. البته در عمل میتوانیم به جای یک پیکسل یک پیسکل، پرش را n پیکسلی انجام دهیم (به این پارامتر stride گفته میشود). همچنین میتوان به اندازه یک یا چند پیکسل دور تصویر اصلی حاشیهی سیاه اضافه کرد تا گوشههای تصویر به خوبی دیده شوند که ما در این مثال این کارها را انجام ندادهایم.
حال سوالی که مطرح میشود این است که اعدادِ داخل فیلترهای کانولوشنی را چگونه باید تنظیم کنیم؟ پاسخ این است که این اعداد توسط الگویتم در هنگام آموزش، یاد گرفته میشوند. در واقع این اعداد داخل فیلترهای کانولوشنی، مانند وزنهایی هستند که در هنگام آموزش با استفاده از همان روش پسانتشار خطا در شبکههای عصبی آپدیت میشوند.
حال یک بار دیگر به معماری اصلی شبکهای که در ابتدای درس ارائه داده بودیم نگاه کنید:
در معماری گفته شده در بالا، همانطور که مشاهده میکنید در مرحلهی اول تعداد ۳۲ فیلتر (کانولوشن) مختلف بر روی تصویر اعمال شده است که هر فیلتر یک تصویر جدید از تصویر ورودی ایجاد میکند و در اینجا ۳۲ تصویرِ فیلتر شده از تصویر ورودی ایجاد میشود. توجه کنید که ابعاد و تعداد فیلترها به عنوان پارامتر به الگوریتم داده میشود و مقادیر موجود در این فیلترها توسط خود الگوریتم در هنگام آموزش تغییر پیدا کرده و بهینه میشوند.
بعد از کانولوشن نیز میتوانیم یک تابع فعالسازی مانند ReLU را بر روی مقادیر خروجی هر کدام از فیلترها اعمال کنیم. این کار در یادگیری شبکههای عصبی میتواند کمک کننده باشد.
ادغام (Pooling)
در شبکههای CNN معمولاً بعد از لایهی پیچش یا همان کانولوشن، یک مرحله ادغام (pooling) بر روی هر کدام از تصاویر فیلتر شده اجرا میشود. این کار به این دلیل است که مقادیر زائد و دارای اطلاعاتِ کم که ممکن است توسط عملیات کانولوشن در تصویر ایجاد شده باشد از بین برود و اطلاعاتِ سادهتر و مفیدتری به لایههای بعدی ارسال شود.
ادغام حالات مختلفی دارند که یکی از معروفترین آنها «ادغام بیشینه» یا «max pooling» است. در این ادغام، مقدار بیشینه از تعدادی از پیکسلها انتخاب شده و بقیه حذف میشوند.
برای مثال در معماری بالا یک ادغام بیشیهی ۲در۲ بر روی تصاویرِ فیلترشده بعد از لایهی کانولوشن اجرا شده است. چیزی شبیه به شکل زیر:
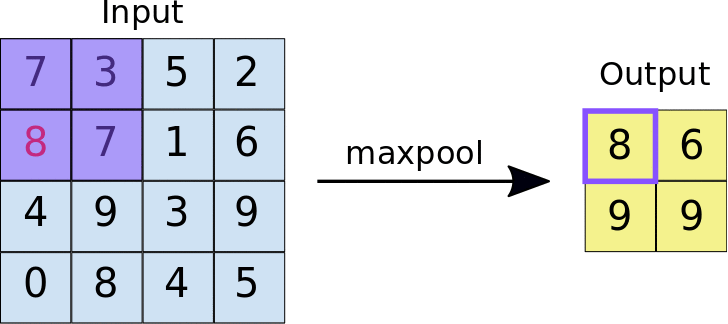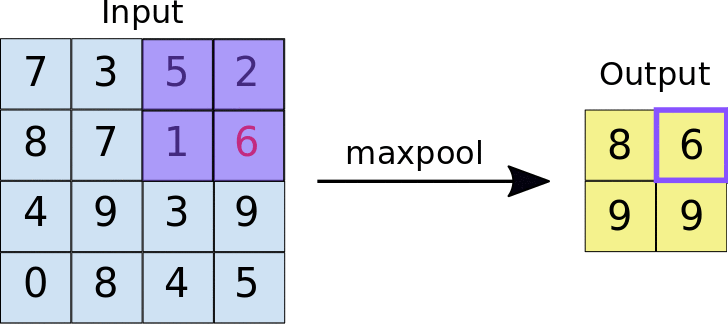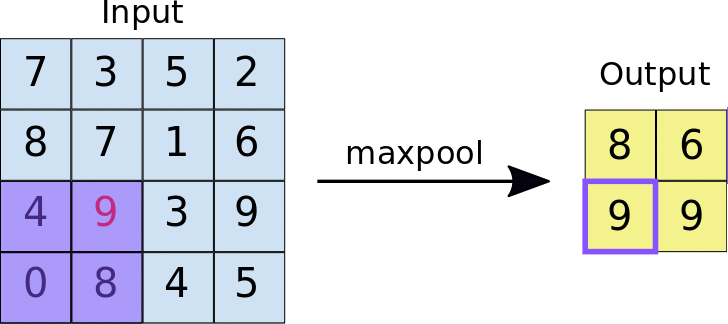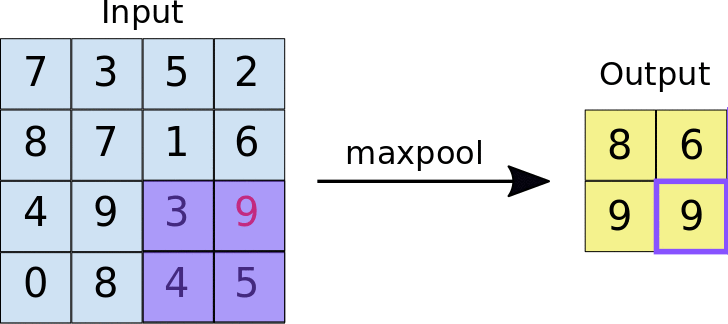
همانطور که میبینید خروجی بعد از اعمال max pool تصویر کوچکتری میشود و این خود میتواند تعداد وزنهای الگوریتم را در مراحل بعدی کاهش داده و سرعت آموزش را افزایش دهد.
روشهای ادغام دیگر مانند «ادغام میانگین» یا همان «average pooling» نیز وجود دارد. در ادغام میانگین، میانگینِ مقادیر پیکسلها در یک محدودهی خاص محاسبه شده و به جای آنها قرار میگیرد.
ادغام یا همان pooling وزنی برای یادگیری ندارد و فقط با انتخاب مقادیر بااهمیت بعد از لایهی کانولوشن میتوان به سرعت و دقت یادگیری در الگوریتم کمک کند.
حال بار دیگر به معماری شبکه نگاهی بیندازید:
بعد از ادغام بار دیگر یک پیچش با ۶۴ فیلتر بر روی تصاویری که از خروجیِ ادغام به دست آمدهاند اعمال شده است. یعنی تا به اینجا ۳۲ تصویر داشتیم که با این پیچش به ۶۴ تصویرِ فیلتر شده افزایش پیدا میکند. بعد از آن مجددا یک ادغام ۲در۲ برای کاهش اثرات احتمالی مخرب کانولوشنِ دومی اعلام کرده و در این مرحله، قسمت اول الگوریتم به پایان میرسد.
شبکه عصبی غلیظ (Fully Connected)
این شبکه یک شبکهی عصبی ساده است که تمامی نورونهای لایهی قبل با وزنها به نورونهای لایهی بعدی متصل شدهاند. در دروهی آشنایی با شبکههای عصبی در مورد این شبکهها صحبت کردیم. به این شبکهها غلیظ (dense) میگویند زیرا تمامی نورونهای لایهی قبلی به تمامی نورونهای لایهی بعدی با وزنها متصل شدهاند. ورودی این شبکه تمامیِ پیکسلهایی است که توسط لایهی ادغامِ آخر ایجاد شدهاند. در واقع بعد از لایهی ادغامِ آخر، تمامی پیکسلهای تمامی تصاویرِ فیلتر و ادغام شده از یک نمونه را، پشت سر هم به ترتیب قرار میدهیم و هر کدام به یک نورون ورودی از شبکهی عصبی غلیظ متصل میشوند.
این شبکهی عصبی غلیظ با وزنها یادگیری را انجام داده و در خروجی، برای مثال در صورت مرد بودنِ تصویرِ ورودی، نورون مربوط به مرد را عدد بالاتری میدهد. برعکسِ همین کار بروی یک تصویر مربوط به جنس زن انجام میشود. در لایهی خروجیِ شبکهی غلیظ نیز میتوان از softmax استفاده کرد.
پس اگر بخواهیم یک بار کل فرآیند شبکههای عصبی کانولوشنی یا همان CNNها را مرور کنیم به این صورت است که یک ورودی (عموماً تصویر) را گرفته، فیلترها و ادغامهای مختلفی بر روی آن انجام میدهد و در نهایت تصاویری که با فیلترهای متعدد بر روی یک ورودی ساخته شده است را به یک شبکهی عصبی غلیظِ تزریق میکند و با این آپدیت کردن وزنها در لایههای کانولوشن و شبکهی عصبی غلیظ یادگیری را انجام میدهد.
بعد از فرآیند یادگیری، کافیست وزنها و معماری شبکه ذخیره شود تا تصاویرِ جدید بتوانند توسط این الگوریتم تشخیص دادهشوند.
برای درک بهتر نیز میتوانید نحوهی عملکرد یک CNN را با معماری نزدیک به شبکهی گفته شده در بالا مشاهده کنید. این الگوریتم بر روی دادههای CFAR10 یادگیری را برای تشخیص اشیای مختلف در یک تصویر انجام میدهد:
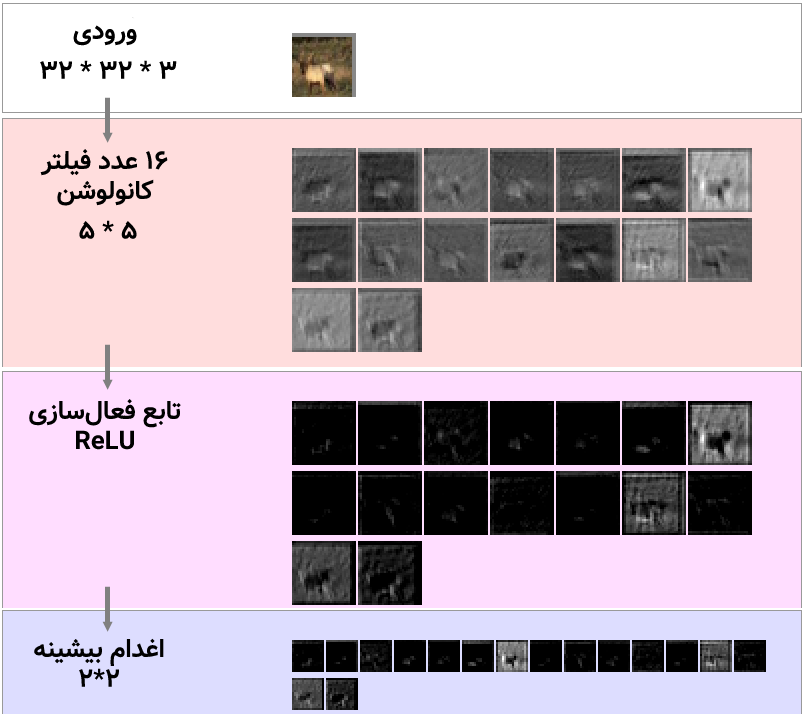
در شکل بالا یک تصویر گوزن وارد CNN شده است و این شبکه بعد از ۱۶ عدد کانولوشن و تابع فعالسازی ReLU، تصاویر فیلتر شده را ادغام بیشینه (max pooling) میکند. سپس خروجی این ادغام، که تصاویر کوچکتری هستند به لایههای بعدی داده میشود:

مشاهده میشود که دو مرتبه یک کانولوشن ۱۶ عددی، تابعفعالسازی و پس از آن ادغام انجام میشود. تصاویر کوچکتر شده و خروجی به مرحلهی بعدی داده میشود:

باز هم کانولوشن ولی اینبار ۲۰ عدد، تابع فعالسازی و ادغام بر روی خروجی قبلی انجام میشود تا تصاویرِ نهایی بسیار کوچک شده و آماده تزریق به مرحلهی نهایی یعنی همان شبکههای عصبی غلیظ باشند:
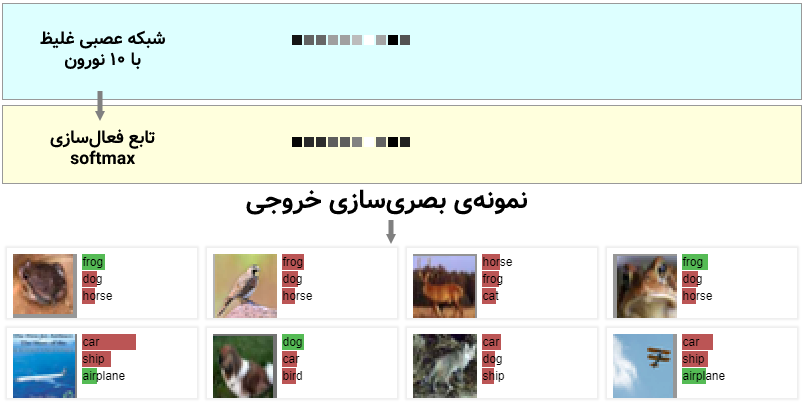
مشاهده میشود که در نهایت با یک شبکهی عصبی غلیظ (fully connected) و سپس تابع فعالسازی softmax، میتوان خروجی مورد نظر را تولید کرد و یا با محاسبهی خطا و پسانتشار آن، وزنها را در شبکه آپدیت نمود.
این آزمایش را میتوانید در وبسایت دانشگاه استنفورد به صورت آنلاین نیز انجام دهید و در هنگام آموزش، وزنها و خروجیها را مشاهده نمایید.
همچنین در ویدیوی زیر یک نمونهی ساده برای یادگیریِ انواع تصاویر با یک معماری چند لایهی CNN را مشاهده میکنید:
شبکههای عصبی کانولوشنی کاربرد انواع مختلف و معماریهای متفاوتی دارند. این شبکهها معمولاً نیاز به دادههای فراوان برای یادگیری داشته و علاوه بر تصاویر با استفاده از تکینکهایی میتوان آنها را بر روی متون یا دیگر انواع داده ها استفاده کرد.

- ۱ » یادگیری عمیق (Deep Learning) چیست؟
- ۲ » تفاوت یادگیری عمیق (Deep Learning) با یادگیری ماشین کلاسیک
- ۳ » تفاوت شبکههای عصبی (Neural Networks) با یادگیری عمیق (Deep Learning) چیست؟
- ۴ » مشکل محوشدگی گرادیان (Gradient Vanishing) در شبکههای عصبی عمیق
- ۵ » مشکل انفجار گرادیان (Exploding Gradients) در شبکههای عصبی عمیق
- ۶ » توابع فعالسازی (Activation Functions) در شبکههای عصبی عمیق
- ۷ » شبکه عصبی پیچشی (Convolutional Neural Network) در یادگیری عمیق
- ۸ » شبکه عصبی بازگشتی (Recurrent Neural Network)
- ۹ » انواع شبکههای عصبی بازگشتی (RNN) و کاربرد آنها
- ۱۰ » شبکه عصبی بازگشتی با حافظهی طولانی کوتاه مدت (LSTM)
- ۱۱ » شبکه عصبی واحد بازگشتی دروازهدار (GRU)
- ۱۲ » شبکههای عصبی عمیق توالی به توالی (Seq2Seq)