

آقای راس کوینلند (پیشنهاد دهندهی الگوریتمِ ID3)، بعد از اینکه به نقاط ضعفِ این الگوریتم پیبرد، در مدتِ کوتاهی الگوریتمِ بعدی خود یعنی C4.5 را طراحی کرد. از نقاطِ ضعف الگوریتم ID3 که در C4.5 رفع شده است میتوان به موارد زیر اشاره کرد:
۱. الگوریتم C4.5 میتواند مقادیر گسسته یا پیوسته را در ویژگیها درک کند. در درسِ آشنایی با الگوریتم ID3 این نکته را گفتیم که الگوریتمِ ID3 اولیه نمیتواند تفاوتِ مقادیرِ عددیِ پیوسته را درک کند. برای مثال نمیتواند تفاوت بین معدلها را درک کند. ولی الگوریتمِ C4.5 میتواند این کار را انجام دهد و مقادیرِ پیوسته را هم درک کرده و بر اساس آن درخت تصمیم را بسازد. مثلاً همان درخت مثالِ درسِ ID3 را مشاهده کنید:
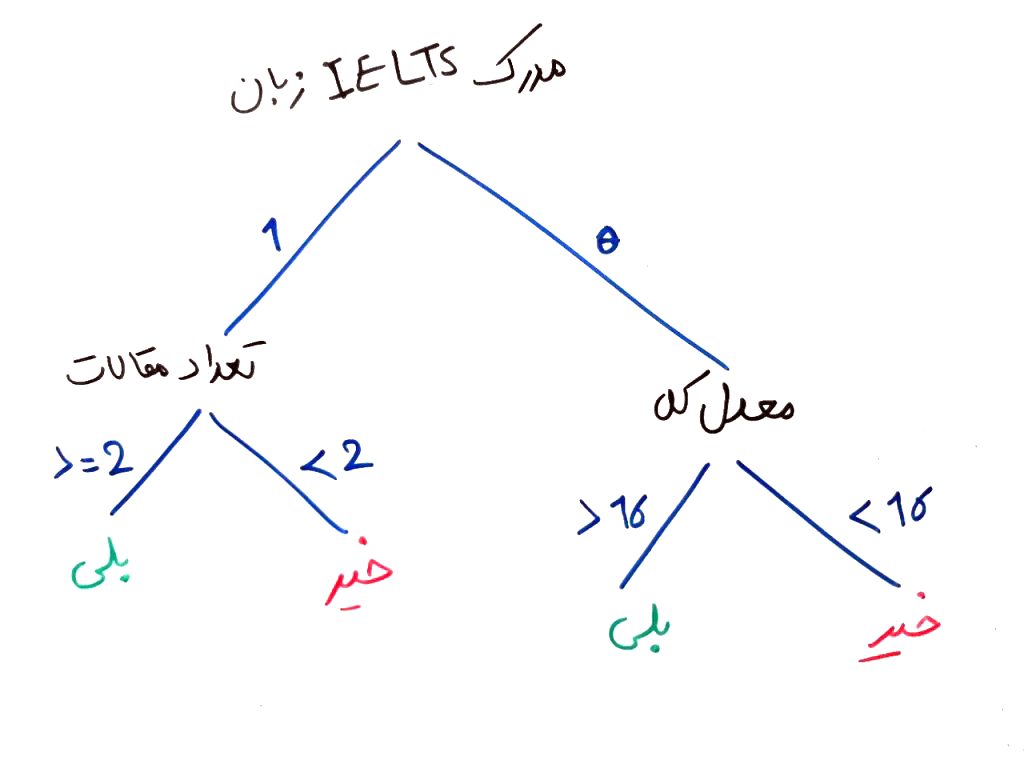
الگوریتمِ ID3 نمیتواند یک همچین درختی را با مقادیر پیوسته بسازد زیرا ساختِ این درخت نیازمندِ این است که الگوریتم بتواند تعدادِ مقالات و معدلِ کل را به صورت پیوسته و عددی همراه با یک حدِ آستانهی مشخص (۲ برای تعداد مقالات و ۱۶ برای معدل) پیدا کند و بر اساس آن شاخههای زیر درختهای چپ و راست را بسازد. ولی این کار توسطِ الگوریتم C4.5 قابل انجام است. (منظور از مقادیر پیوسته مثلاً اعدادی است که پشت سرِ هم میآیند و منظور از مقادیر گسسته مثلاً مرد یا زن بودن است)
۲. الگوریتمِ C4.5 قادر است تا مقادیری که موجود نیستند را هم تحمل کند. برای مثال تصویر زیر را که مانند جدول درس ID3 بود نگاه کنید:
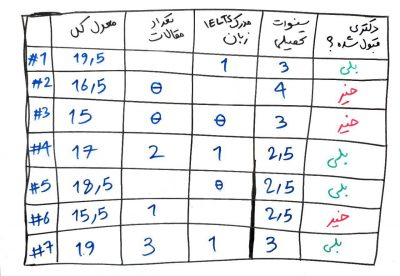
در تصویر بالا مشاهده میکنید که تعدادی از دادهها وجود ندارند. به این دادهها، مقادیرِ ناموجود (missing values) نیز میگویند. مثلاً فرد شمارهی ۱، تعدادِ مقالات نامعلومی دارد، یعنی در این مجموعه داده نتوانستهایم تعدادِ مقالاتِ فرد ۱ را به دست بیاوریم. الگوریتم C4.5 میتواند این مقادیر را تحمل کند و با وجود مقادیری که ناموجود است، درخت تصمیم خود را بسازد. در حالی که الگوریتمی مانند ID3 و بسیاری دیگر از الگوریتمهای طبقهبندی نمیتوانند با مقادیر ناموجود، مدلِ خود را بسازند.
۳. سومین موردی که باعث بهینه شدن الگوریتم C4.5 نسبت به ID3 میشود، عملیاتِ هرس کردن (prunning) جهت جلوگیری از overfitting است. الگوریتمهایی مانند ID3 به خاطر اینکه سعی دارند تا حد امکان شاخه و برگ داشته باشند (تا به نتیجه مورد نظر برسند) با احتمال بالاتری دارای پیچیدگی در ساخت مدل میشوند (بحث bias و variance را مطالعه داشته باشید) و این پیچیدگی در بسیاری از موارد الگوریتم را دچار overfitting و خطای بالا میکند. اما با عملیات هرس کردن درخت که در الگوریتم C4.5 انجام میشود، میتوان مدل را به یک نقطه بهینه رساند که زیاد پیچیده نباشد (و البته زیاد هم ساده نباشد) و overfitting یا underfitting رخ ندهد.
۴. مورد چهارم که میتواند الگوریتم C4.5 را از بسیاری دیگر از الگوریتمها متمایز کند بحثِ وزندهی (weighting) به ویژگیها است. اجازه بدهید به مثال اشاره شده در درس الگوریتم ID3 برگردیم. شما میخواهید یک طبقهبند بسازید تا از روی مدلِ ساخته شده پیشبینی کند که آیا یک شخص میتواند در مقطع دکتری قبول شود یا خیر؟ مانند تصویر:
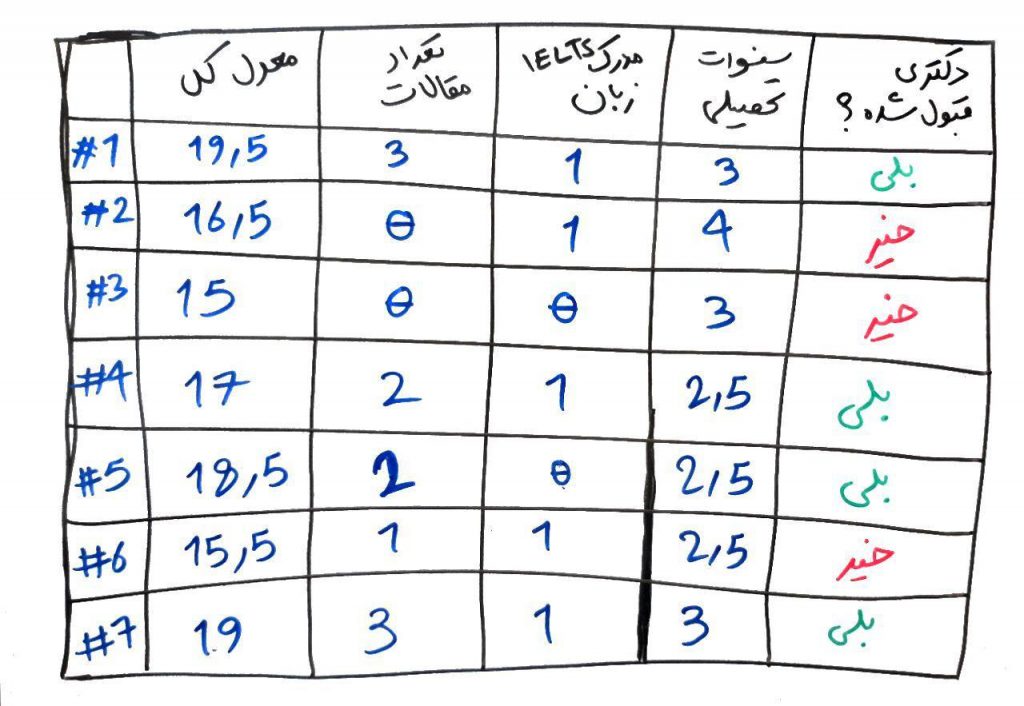
حال فرض کنید، شما به عنون رئیسِ دانشکده (با توجه به تجربهی بالای خود) میخواهید وزنِ ویژگیِ تعداد مقالات را بیشتر کنید. یعنی به این نتیجه رسیدهاید که این ویژگی میتواند اثر بیشتری در انتخاب یک شخص در مقطع دکتری داشته باشد. الگوریتم C4.5 این قابلیت را دارد که وزنهای مختلف و غیر یکسانی را به برخی از ویژگیها بدهد.
در دروس آینده بیشتر به الگوریتم C4.5 میپردازیم و این الگوریتم را دقیقتر مورد بررسی قرار خواهیم داد.

- ۱ » الگوریتم K نزدیک ترین همسایه (KNN)
- ۲ » درخت های تصمیم جهت طبقهبندی (Decision Trees)
- ۳ » الگوریتم درخت تصمیم ID3 و ساختار Entropy و Gain
- ۴ » آشنایی با مفهوم Overfitting و Underfitting در طبقهبندی
- ۵ » آشنایی با مفهوم Bias و Variance در طبقهبندی
- ۶ » الگوریتم طبقهبندی درخت تصمیم C4.5
- ۷ » الگوریتم طبقه بند درخت تصمیم CART
- ۸ » طبقه بند ترکیبی (Ensemble Classifier) و مبحث Bagging و Boosting
- ۹ » الگوریتم جنگل تصادفی (Random Forest)
- ۱۰ » رگرسیون لجستیک (Logistic Regression)
- ۱۱ » مسائل طبقهبندی دودویی (binary)، چند کلاسه (Multi Class)، چند برچسبه (Multi Label) و تفاوت آنها
- ۱۲ » روش «یک در مقابل همه (One vs. All)» برای طبقهبندی دادههای چند کلاسه
- ۱۳ » روش «یک در مقابل یک (One vs. One)» در طبقهبندی
- ۱۴ » مدلهای احتمالی در مقابل مدلهای قطعی در طبقهبندی دادهها
- ۱۵ » ماتریس اغتشاش (Confusion Matrix) و معیار دقت (Accuracy)
- ۱۶ » معیار صحت (Precision)، پوشش (Recall) و معیار F
- ۱۷ » معیار کاپا (Kappa) برای ارزیابی طبقهبندیهای چندکلاسه
سلام.یک الگوریتم جدید هست در وکا که آپدیت شده الگوریتم c4.5 به نام PART میشه دربارش یکم توضیح بدین؟
ممنون
با سلام
بله
حتما در مورد آن الگوریتم هم توضیحاتی خواهم نوشت
با تشکر از توجه شما
باسلام
واحد انتروپی وبهره اطلاعت چیه ؟؟؟؟در جایی خوندم که bits.ایا درست هست ؟؟؟؟
سلام تو نرم افزار وکا الگوریتم j 4.8 بعد از اینکه دیتا رو لود میکنم فعال نمیشه
دلیلش چیه؟!
سلام
متاسفانه این نرمافزار را کار نکردم
سلام.
بله درست هست چونکه مبنای لوگاریتم در فرمول آنتروپی ۲ هست و بهره اطلاعات هم به همین صورت.
سلام
الگوریتم c5 هم میشه توضیح بدید؟
چه فرق هایی با c4.5 داره؟
با سلام و تشکر از توجه شما
در درسی جداگانه به زودی درباره الگوریتم C5 نیز صحبت خواهیم کرد
آیا میشه تعداد شاخه؟و زیر شاخه را مشخص کرد؟و تعدادشان چقدر است؟ آیا برای همه پروژهها ثابت است؟
اقا داداش دمت گرم یک دونه مثال با c4.5 حل کن ما ببینیم تعریفی فایده نداره استاد ما هر ترم سوال میده من نیاز دارم فقط تعریف و تفاوت پیدا کردم مثال حل شده بگو
تروخدا کمک کنید
sidereza2015@gmail.com
سلام ممنون از سایت خوبتون .
چرا هیچ مثال عددی حل شد با پابتون ندارید ؟؟
البته میشه در این پست به این موضوع هم توجه داشته که ID3 که بر اساس information gain عمل میکنه اکثر به دنبال این هست که خصیصه هایی رو بسط بده که حاوی برچسب های متعدد هست برای مثال اگر در دیتابیس مان یک کلید بیرونی مثلا ID داشته باشیم چونکه آنتروپی این خصیصه به تنهایی صفر میشه پس Gain این خصیصه ماکسیسمم میگردد و درخت به تعداد مقادیر این خصیصه افراز میگردد ولی این طور افراز کردن برای ما مفید نیست و الگوریتم C4.5 سعی میکنه با استفاده از GainRation یک خصیصه از این بایاس جلوگیری کنه.
البته میشه در این پست به این موضوع هم توجه داشته که ID3 که بر اساس information gain عمل میکنه اکثر به دنبال این هست که خصیصه هایی رو بسط بده که حاوی برچسب های متعدد هست برای مثال اگر در دیتابیس مان یک کلید بیرونی مثلا ID داشته باشیم چونکه آنتروپی این خصیصه به تنهایی صفر میشه پس Gain این خصیصه ماکسیسمم میگردد و درخت به تعداد مقادیر این خصیصه افراز میگردد ولی این طور افراز کردن برای ما مفید نیست و الگوریتم C4.5 سعی میکنه با استفاده از GainRation یک خصیصه از این بایاس جلوگیری کنه.
سلام وقت بخیر. استاد یک دنیا تشکر بابت دوره بسیار خوب در سایت سون لرن واقعا تدریس بی نظیری داشتید. میخواستم بدونم ممکن هست در مورد الگوریتم quest توضیح بدید؟ تو یه مقاله ای مطالعه میکردم نفهمیدم دقیقا چی هست. با تشکر از زحمات ارزنده شما