

اگر درسِ مدلهای ترکیبی در طبقهبندی را خوانده باشید، درکِ الگوریتمِ جنگلِ تصادفی برای شما بسیار ساده خواهد بود. همانطور که در درسِ مدلهای ترکیبی (ensemble) برای الگوریتمهای طبقهبندی گفتیم، الگوریتمهای Ensemble از الگوریتمهای طبقهبندیِ ساده و ضعیفتر جهتِ تصمیمگیری استفاده میکنند. برای یادآوری شکل زیر را آوردهایم:
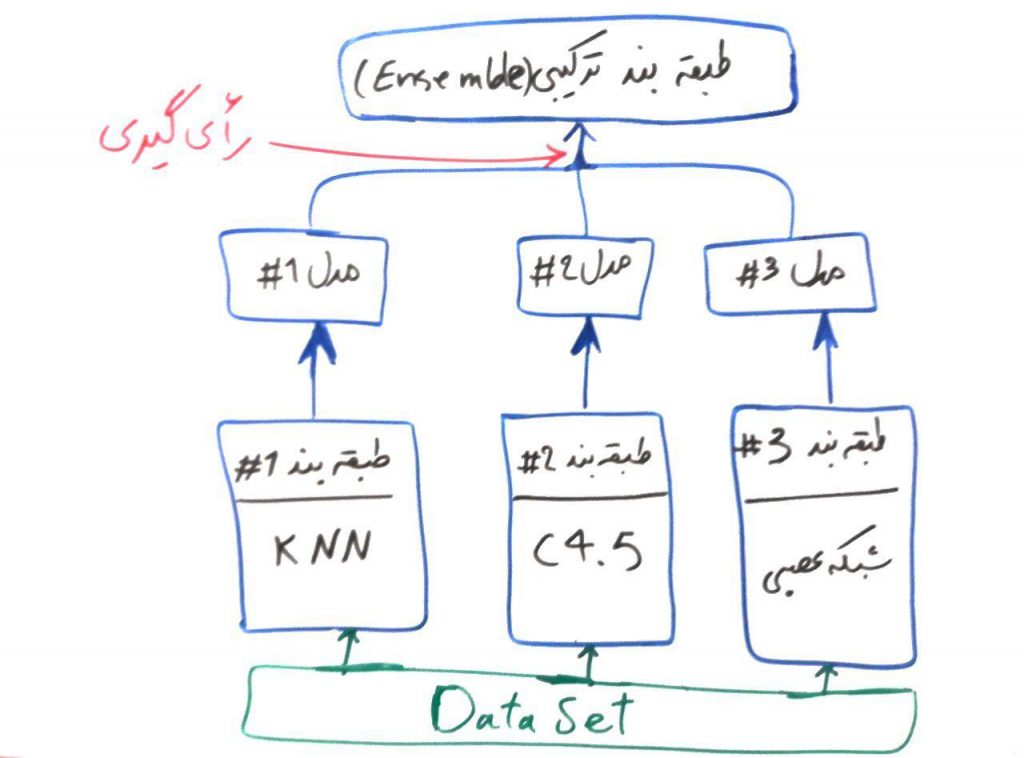
الگوریتمِ جنگلِ تصادفی یا همان Random Forest هم یک الگوریتمِ ترکیبی (ensemble) بوده که از درختهای تصمیم، برای الگوریتمهای ساده و ضعیفِ خود استفاده میکند. حتما درس درختهای تصمیم (decision trees) را مطالعه کردهاید و میدانید که یک الگوریتمِ درختِ تصمیم، میتواند به راحتی عملیاتِ طبقهبندی را بر روی دادهها انجام دهد. حال در الگوریتمِ جنگل تصادفی از چندین درختِ تصمیم (برای مثال ۱۰۰ درخت تصمیم) استفاده میشود. در واقع مجموعهای از درختهای تصمیم، با هم یک جنگل را تولید میکنند و این جنگل میتواند تصمیمهای بهتری را (نسبت به یک درخت) اتخاذ نماید.
در الگوریتم جنگل تصادفی به هر کدام از درختها، یک زیرمجموعهای از دادهها تزریق میشود. برای مثال اگر مجموعه دادهی شما دارای ۱۰۰۰ سطر (یعنی ۱۰۰۰ نمونه) و ۵۰ ستون (یعنی ۵۰ ویژگی) بود (درس ویژگیها و ابعاد را خوانده باشید)، الگوریتمِ جنگلِ تصادفی به هر کدام از درختها، ۱۰۰ سطر و ۲۰ ستون، که به صورت تصادفی انتخاب شدهاند و زیر مجموعهای از مجموعهی دادهها هست، میدهد. این درختها با همین دیتاستِ زیر مجموعه، میتوانند تصمیم بگیرند و مدلِ طبقهبندِ خود را بسازند. برای نمونه شکل زیر را در نظر بگیرید:
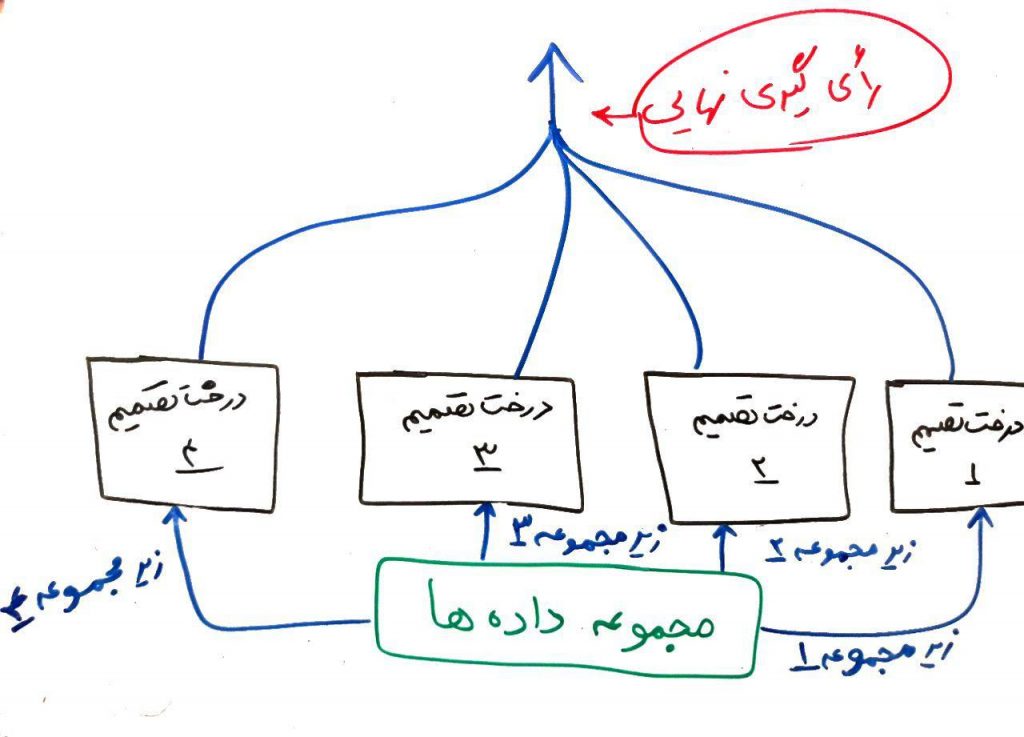
همانطور که مشاهده میکنید، مجموعهای از درختهای تصمیم وجود دارند که به هر کدام از آنها یک زیر مجموعهای از دادهها تزریق میشود. هر کدام از الگوریتمها عملیاتِ یادگیری را انجام میدهند. در هنگام پیشبینی، یعنی وقتی که یک سری دادهی جدید به الگوریتم، جهت پیشبینی داده میشود، هر کدام از این الگوریتمهای یادگرفته شده، یک نتیجه را پیشبینی میکنند. الگوریتمِ جنگلِ تصادفی در نهایت، میتواند با استفاده از رایگیری، آن طبقهای را که بیشترین رای را آورده است انتخاب کرده و به عنوانِ طبقهی نهایی جهت انجامِ عملیات طبقهبندی قرار دهد.

- ۱ » الگوریتم K نزدیک ترین همسایه (KNN)
- ۲ » درخت های تصمیم جهت طبقهبندی (Decision Trees)
- ۳ » الگوریتم درخت تصمیم ID3 و ساختار Entropy و Gain
- ۴ » آشنایی با مفهوم Overfitting و Underfitting در طبقهبندی
- ۵ » آشنایی با مفهوم Bias و Variance در طبقهبندی
- ۶ » الگوریتم طبقهبندی درخت تصمیم C4.5
- ۷ » الگوریتم طبقه بند درخت تصمیم CART
- ۸ » طبقه بند ترکیبی (Ensemble Classifier) و مبحث Bagging و Boosting
- ۹ » الگوریتم جنگل تصادفی (Random Forest)
- ۱۰ » رگرسیون لجستیک (Logistic Regression)
- ۱۱ » مسائل طبقهبندی دودویی (binary)، چند کلاسه (Multi Class)، چند برچسبه (Multi Label) و تفاوت آنها
- ۱۲ » روش «یک در مقابل همه (One vs. All)» برای طبقهبندی دادههای چند کلاسه
- ۱۳ » روش «یک در مقابل یک (One vs. One)» در طبقهبندی
- ۱۴ » مدلهای احتمالی در مقابل مدلهای قطعی در طبقهبندی دادهها
- ۱۵ » ماتریس اغتشاش (Confusion Matrix) و معیار دقت (Accuracy)
- ۱۶ » معیار صحت (Precision)، پوشش (Recall) و معیار F
- ۱۷ » معیار کاپا (Kappa) برای ارزیابی طبقهبندیهای چندکلاسه
با سلام و عرض ادب
واقعا ممنونم از این آموزش رسا. خیلی خوب فهمیدم و استفاده نمودم.
امیدوارم درهای علم و دانش بر روی جنابعالی بیش از این گشوده شود.
اقا لینک مطلبو من پیدا نکردم.میشه راهنماییم کنید؟
خیلی ممنونم بابت توضیحاتتون
یک سوال
اگه تو انتخاب ۱۰۰ نمونه و ۲۰ ویژگی بصورت تصادفی، ویژگیهای انتخابی از اهمیت کمتری برخوردار باشند در جواب مشکل بوجود نمیاد؟
چون درخت تصمیم از مهترین ویژگی شرو به تشکیل شدن میکنه
بله ممکنه یه همچین مشکلاتی به وجود بیاد
ولی در کل این مشکلات با استفاده از تعداد بالایی درخت و استفاده از روش انتخاب تصادفی ویژگیها که در درخت تصمیم داریم، از بین میرود
سلام ممنونم بابت مطالب مفیدتون من میخوام مفهوم و عملکرد tree bagger و out of bag رو بدونم میشه لطفا تعاریفش رو داخل سایتتون قرار بدین، تشکر
مطالبتون خیلی ساده و روان توضیح داده شده
تشکر فراوان
ممنون از توضیحات بسیار خوبتون که فهم مطالب رو برامون آسون میکنه خداقوت