

در درسهای قبل این دوره، با انواع الگوریتمهای طبقهبندی آشنا شدیم و دیدیم که چگونه میتوان با استفاده از این الگوریتمها، الگوهای مختلف و طبقههای متناظر آنها را در یک مجموعهی داده، شناسایی کرد. در این درس به سراغ یکی دیگر از الگوریتمهای طبقهبندی (Classification) میرویم که رگرسیون لجستیک یا همان Logistic Regression نام دارد. این الگوریتم بر خلاف اسمش، جزو الگوریتمهای طبقهبندی قرار میگیرد و معمولاً آن را یک الگوریتم رگرسیون نمیدانند.
رگرسیون لجستیک (Logistic Regression) میتواند بین دو طبقه تمایز قائل شود. به همین دلیل نام لجستیک را به خود گرفته است. برای مثال فرض کنید میخواهید نرمافزاری بنویسید که بتواند یک پیامک را در طبقهی تبلیغاتی یا عادی طبقهبندی کند. در این حالت میتوانید از این الگوریتم طبقهبندی استفاده کنید.
فرض کنید میخواهید سیستمی طراحی کنید که این سیستم توانایی تشخیص پیامکهای تبلیغاتی را از پیامکهای عادی دارد. فرض کنید در اینجا فقط یک ویژگی را در نظر میگیریم و آن تعداد کاراکترهای یک پیامک است. یعنی متغیر مستقل، تعداد کاراکترهای پیامک بوده و متغیر وابسته (برچسب)، تبلیغاتی بودن یا عادی بودنِ یک پیامک است. چیزی مانند شکل زیر:
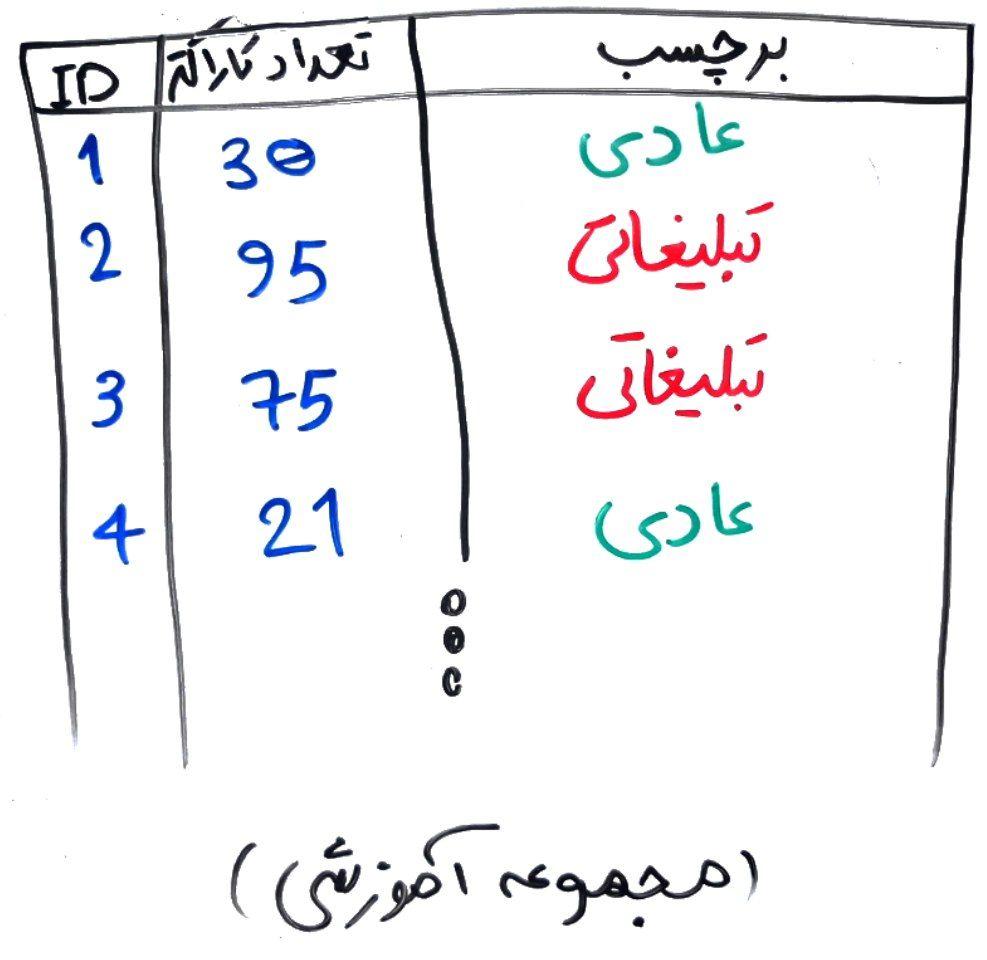
حال برای درک الگوریتم رگرسیون لجستیک، ابتدا دو مفهوم ساده را با یکدیگر فرا میگیریم. ابتدا معادلهی خط. این معادله را از ریاضیات پایه دبیرستان به یاد دارید و میدانید که به صورت زیر تعریف میشود:

در اینجا چون فقط یک متغیر (یک بُعد) – که همان تعداد کاراکترها (count) است – داریم، یک ضریب موجود است. حتماً میدانید در مسائل واقعی تعداد بسیار بیشتری از متغیرها (بُعدها) را درا ختیار داریم و فرمول به جال خط، یک صفحه یا اَبَر صفحه میشود.
بعد از تابع خط، به تابع تعیین احتمال سیگموید (Sigmoid) که احتمال وقوع یک رخداد را برای ما تعیین میکند میرسیم (متغیر x از خروجیِ معادلهی خطِ بالا به دست میآید):
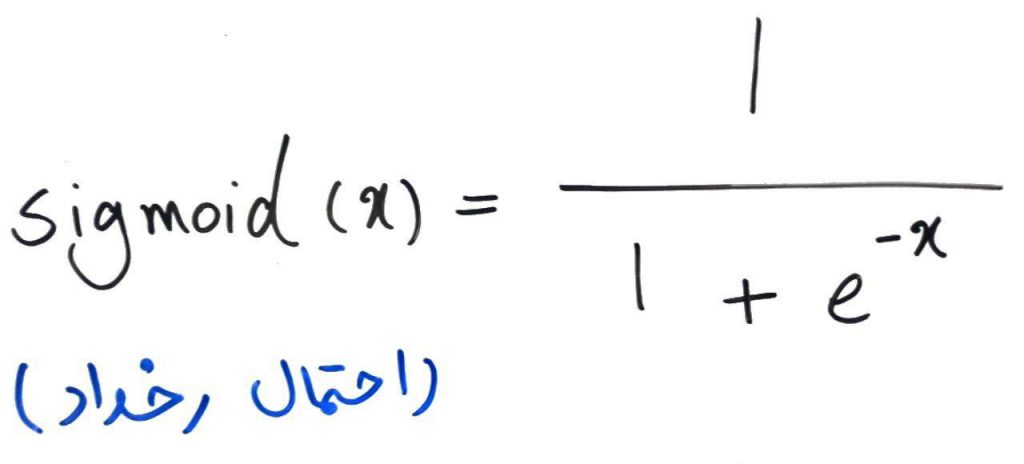
با استفاده از این دو تابع (خط و سیگموید) میتوانید خطوطی مورب رسم کنید تا بر روی دادههای شما به صورت مناسب قرار بگیرند. در واقع با کم و زیاد کردن پارامترهای مختلف و سعی و خطا (که معمولاً توسط الگوریتمهایی مانند کاهش گرادیان (Gradient Descend) یا بیشینهسازیِ شباهت (Maximum Likelihood) انجام میشود) میتوانید این خط مورب را بر روی دادههای خود، تطبیق دهید. برای مثال شکل زیر را برای همان مثال پیامک تبلیغاتی/عادی در نظر بگیرید:
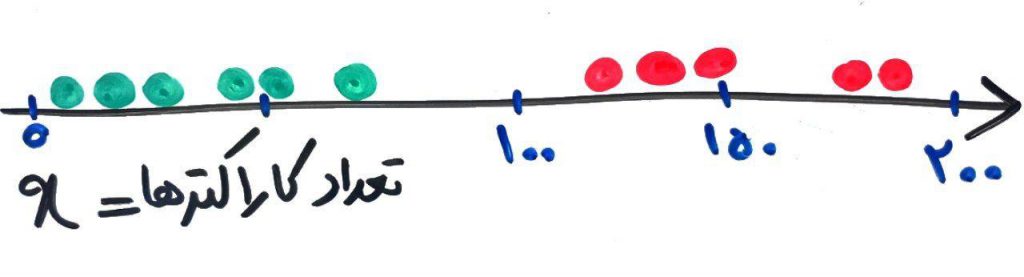
همانطور که گفتیم ما فقط یک متغیر – یک ویژگی – داریم (یعنی دادههای ما یک بُعدی است). فرض کنید نقاط سبز، پیامکهایی هستند که بایستی جزو دستهی عادی طبقهبندی شده و نقاط قرمز، پیامکهای تبلیغاتی هستند. با انتخابِ مناسبِ پارامترهای خط و سپس تابع سیگموید میتوانیم دادهها را به گونهای مدل کنیم، که بر روی خطِ منحنیِ زیر قرار بگیرند:
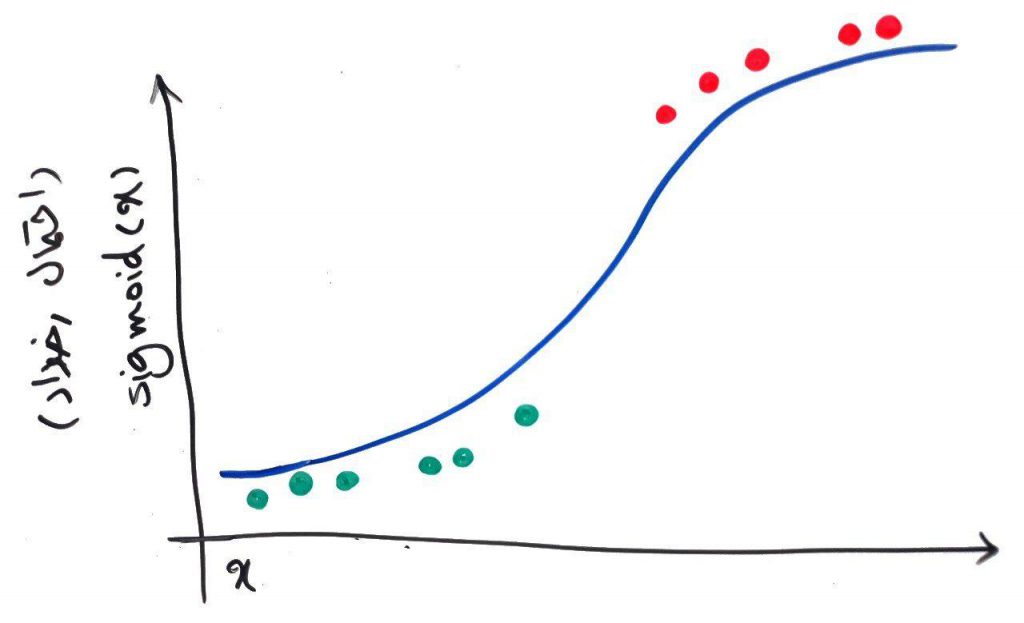
محور افقی، همان متغیر ماست، و محور عمودی خروجیِ تابع سیگموید (Sigmoid) است. همانطور که میبینید، خط و تابع سیگموید توانستهاند به خوبی بر روی دادهها تطبیق پیدا کنند. برای درک بهتر، فرض کنید پارامترها و معادلهی خطِ متناظر به این پیامکها به صورت زیر باشد و این پارامترها بر اساس االگوریتم کاهش گرادیان، بهترین پارامترهای پیدا شده باشند:
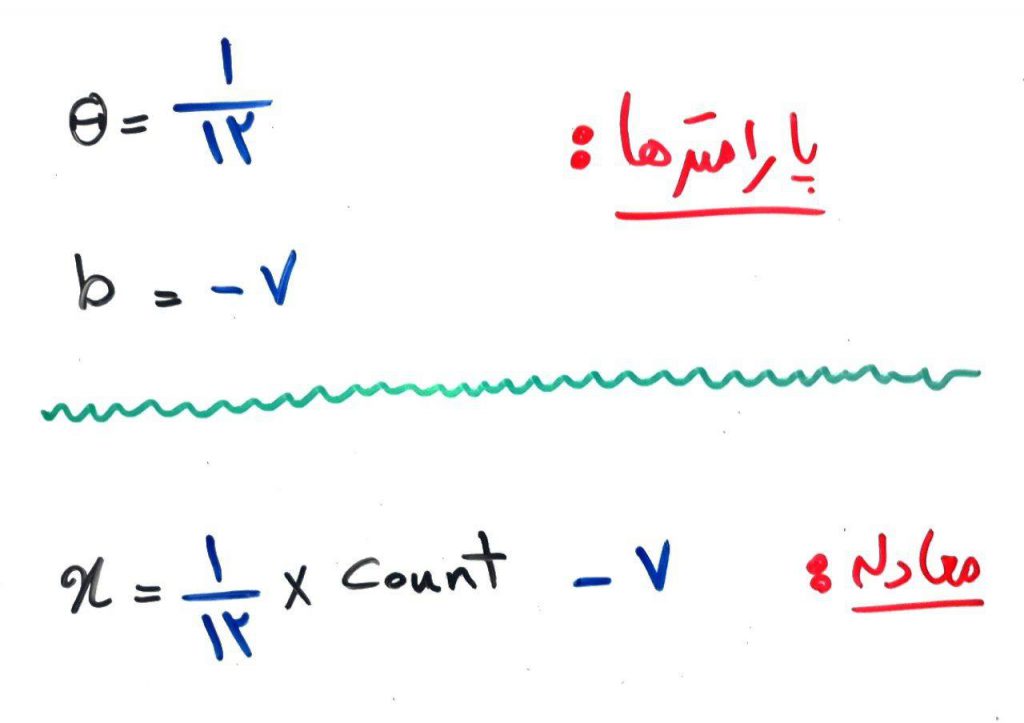
حال فرض کنید، دو پیامک با ویژگیهای زیر میآید. یکی از آنها ۶۰ کاراکتر دارد و دیگری ۱۲۰ کاراکتر. مطابق فرمولِ خط با پارامترهای بالا و تابع سیگموید که بعد از آن اعمال میشود، نتیجه برای این دو پیامک به صورت زیر است:

همانطور که میبینید پیامک اولی به احتمال ۱۱ درصد تبلیغاتی است ولی پیامک دومی به احتمال ۹۵ درصد تبلیغاتی است. نرمافزار میتواند تصمیم بگیرد که پیامکهایی که با احتمالی بیشتر از ۵۰ درصد توسط رگرسیون لجستیک، تبلیغاتی در نظر گرفته میشوند را به عنوان پیامک تبلیغاتی تشخیص داده و مثلاً برای آن صدای زنگ موبایل را به صدا در نیاورد.
حتماً توجه دارید که در مثال بالا، میتوانیم به جای یک متغیر چندین متغیر دیگر را نیز اضافه کنیم. حتی میتوانیم متن پیامک را با استفاده از TF-IDF به ویژگیها (ابعاد مسئله) تبدیل کرده و فضا را به جای یک فضای یک متغیره (یک بُعدی)، به فضایی با ابعاد بالاتر تبدیل کنیم. با تبدیل این فضای یک بُعدی به فضایی با ابعاد بالاتر، معادلهی خط نیز به معادلهی صفحه یا اَبَر صفحه (Hyper Plane) تبدیل میشود، ولی راه حل مسئله تفاوتی با مثال بالا نمیکند.

- ۱ » الگوریتم K نزدیک ترین همسایه (KNN)
- ۲ » درخت های تصمیم جهت طبقهبندی (Decision Trees)
- ۳ » الگوریتم درخت تصمیم ID3 و ساختار Entropy و Gain
- ۴ » آشنایی با مفهوم Overfitting و Underfitting در طبقهبندی
- ۵ » آشنایی با مفهوم Bias و Variance در طبقهبندی
- ۶ » الگوریتم طبقهبندی درخت تصمیم C4.5
- ۷ » الگوریتم طبقه بند درخت تصمیم CART
- ۸ » طبقه بند ترکیبی (Ensemble Classifier) و مبحث Bagging و Boosting
- ۹ » الگوریتم جنگل تصادفی (Random Forest)
- ۱۰ » رگرسیون لجستیک (Logistic Regression)
- ۱۱ » مسائل طبقهبندی دودویی (binary)، چند کلاسه (Multi Class)، چند برچسبه (Multi Label) و تفاوت آنها
- ۱۲ » روش «یک در مقابل همه (One vs. All)» برای طبقهبندی دادههای چند کلاسه
- ۱۳ » روش «یک در مقابل یک (One vs. One)» در طبقهبندی
- ۱۴ » مدلهای احتمالی در مقابل مدلهای قطعی در طبقهبندی دادهها
- ۱۵ » ماتریس اغتشاش (Confusion Matrix) و معیار دقت (Accuracy)
- ۱۶ » معیار صحت (Precision)، پوشش (Recall) و معیار F
- ۱۷ » معیار کاپا (Kappa) برای ارزیابی طبقهبندیهای چندکلاسه
ذکر این نکته هم خیلی لازم بود که بگید:
رگرسیون لجستیک فقط واسه طبقه بندی داده هایی بدرد میخوره که به صورت خطی تفکیک پذیر باشند.
واسه دسته بندی غیر خطی مناسب نیستند.
سلام. تشکر از زحماتتون. ببخشید الان تعریف خود رگرسیون لجستیک چی شد؟ من متوجه نشدم. خط و سیگموپید با هم میشن رگرسیون لجستیک؟
بسیار کاربردی بود
من توی خیلی از سایتها گشته بودم
ولی با خوندن آموزش شما، تازه متوجه شدم این الگوریتم به صورت کلی چطور کار میکنه
متشکرم مهندس