

مسائلِ حوزهی طبقهبندی (که پایهی آن آمار و ریاضیات هستند) یک خروجیِ موردِ انتظار دارند و آن این است که بتوانیم برچسبها را با دقت بالا شناسایی و از همدیگر تفکیک کنیم. احتمالاً در درس شبکههای عصبی با مفهومِ خطِ جداساز برای سگ و گربه آشنا شدهاید. اجازه بدهید یک بارِ دیگر این تصویر را با هم مرورِ کوتاهی داشته باشیم (برای درک اولیه این تصویر درس شبکه عصبی MLP را از اینجا بخوانید):
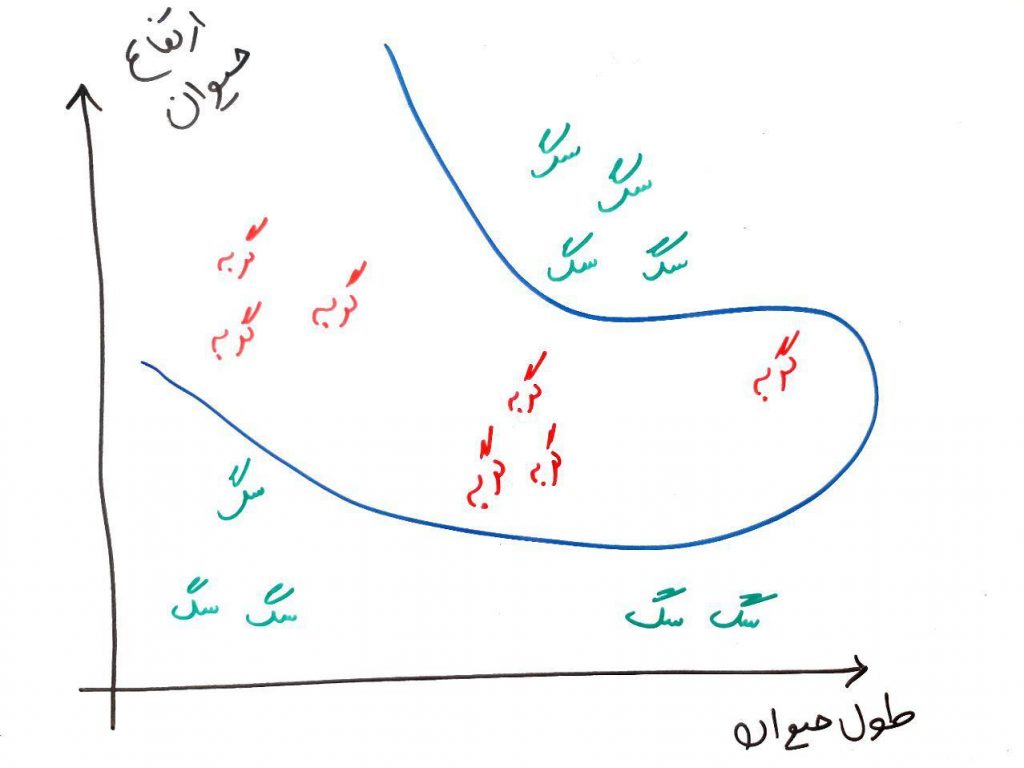
در تصویر بالا، با یک الگوریتم طبقهبندی (مهم نیست چه طبقهبندی)، توانستیم یک خط ساده رسم کنیم که این خط میتواند یک تمایز بین سگ و گربه را نشان دهد. در واقع فضای داخلیِ این خط گربهها و فضای خارجیِ این خط سگها را نشان می دهند. حال فرض کنید این خطِ جدا کننده (خطِ طبقهبند) به صورت زیر بود:
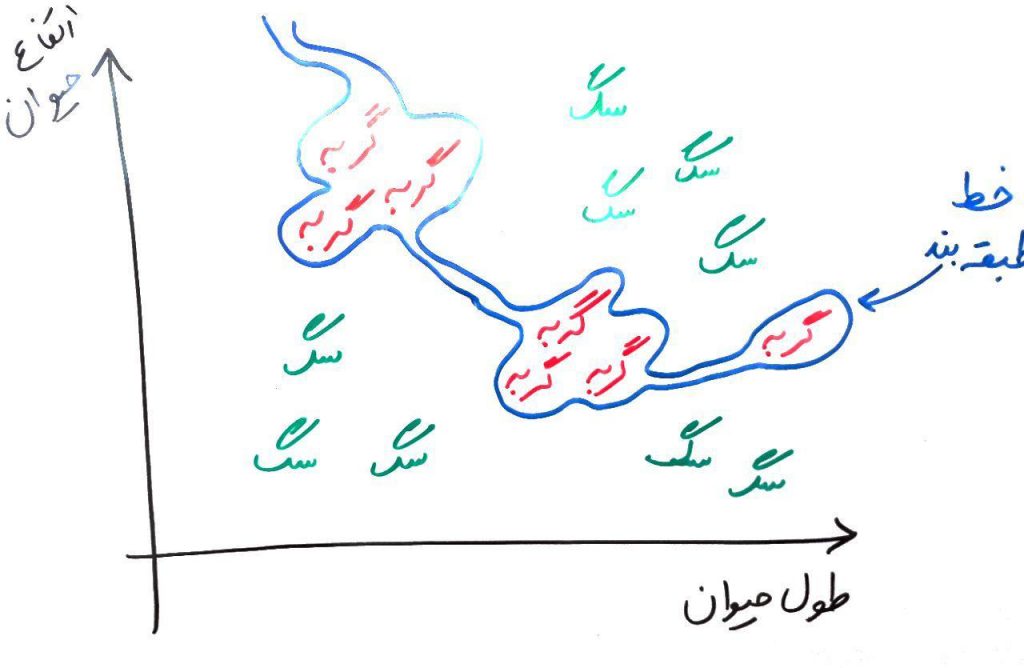
در اینجا، خطِ طبقه بند دارای پیچیدگی (complexity) زیادی است. از درسِ قبل به یاد دارید که معنیِ این خطِ پیچیده این است که طبقهبندی که این خط را رسم کرده، بسیار overfit شده است. یعنی کاملاً بر روی دادههای آموزشیِ موجود، درست عمل میکند ولی اگر یک یا چند دادهی جدید ببیند، نمیتواند به درستی این دادهی جدید را طبقهبندی کند (برچسب بزند). یعنی خطای بالایی در طبقهبندی دارد. این مدلِ پیچیده (خطِ پیچیده) خطای طبقهبندی را بالا میبرد (اگر چه که بر روی دادههای آموزشیِ موجود خوب عمل میکند). برای مثال شکل زیر را نگاه کنید:
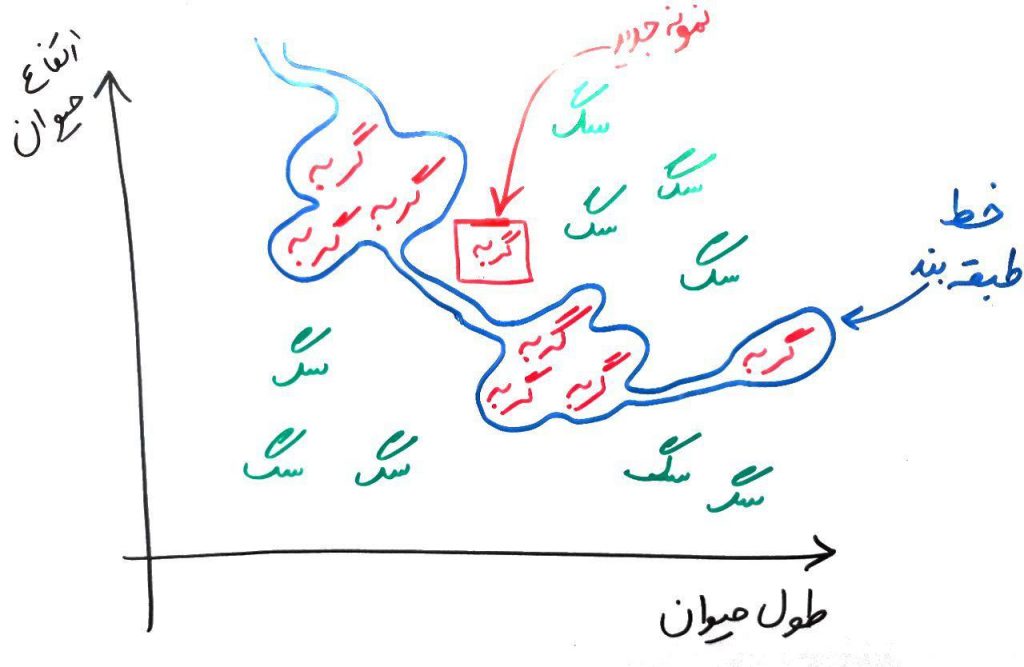
در این شکل یک نمونه گربه جدید (که در مربع آورده شده است) را با طول و ارتفاعِ مشخص در تصویر مشاهده میکنید. ولی چون، خطِ طبقهبند بسیار پیچیده و در واقع overfit شده بود، این طبقهبند به اشتباه این گربه را در دسته سگها (در فضای بیرونیِ خط) قرار می دهد. در اصطلاح اینجا variance بالایی داریم به این معنی که خطِ طبقهبند دارای پیچیدگیِ بالایی بوده و در عینِ حال که میتواند طبقهبندی را بر روی دادههای آموزشیِ موجود بسیار درست انجام دهد، ولی اگر یک دادهی جدید (مانند نمونه گربهی جدید در شکل بالا) را مشاهده کند، ممکن است خطای زیادی داشته باشد.
حال فرض کنید خط تفکیک کننده برای یک الگوریتم طبقهبندی چیزی مانند شکل زیر باشد:
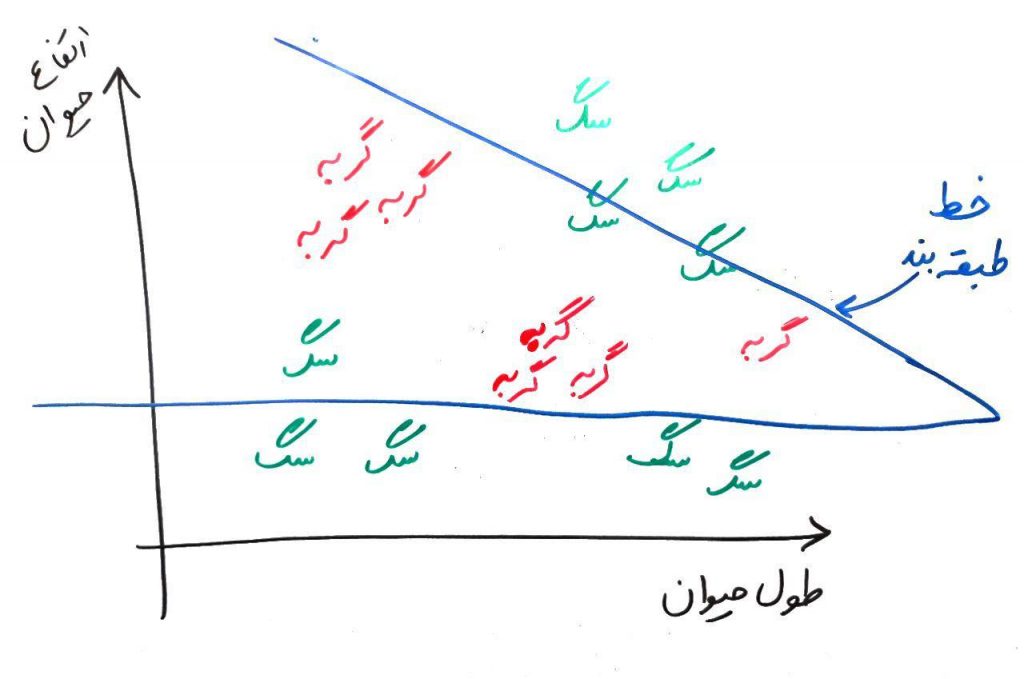
در اینجا خط بسیار ساده رسم شده است. همان طور که میبینید، این خط ساده بر روی دادههای آموزشی (دادههای موجود) نیز خطا دارد (مثلاً یک سگ را به اشتباه در دستهی گربهها قرار داده است) ولی به هر حال نسبت به دادههای جدید، خطای خیلی بالایی نخواهد داشت. یعنی هم بر روی دادههای آموزشی و هم بر روی دادههای جدید یک خطای نسبی دارد. در این جا مقدار bias زیادی داریم یعنی خطِ سادهی ما، چه در دادههای آموزشی و چه در دادههای جدید یک خطای نسبی دارد. با توجه به درس قبل، میدانیم که در اینجا underfitting رخ داده است.
پس تا به اینجای کار فهمیدیم که bias بالا سادگیِ زیادِ طبقهبند را در نتیجه دارد و variance بالا نیز پیچیدگیِ بیش از حد را برای ما به همراه دارد. حال به مفهومی به اسم تعادلِ بین bias و variance که به Bias and Variance Tradeoff مشهور است میرسیم. در واقع این مفهوم به ما میگوید که باید یک تعادلِ معقولی بین bias و variance یعنی بین سادگیِ زیادِ طبقهبند و پیچیدگیِ زیادِ آن برقرار شود تا یک الگوریتم طبقهبندی خوب داشته باشیم. برای درک این مفهوم شکل زیر را نگاه کنید:
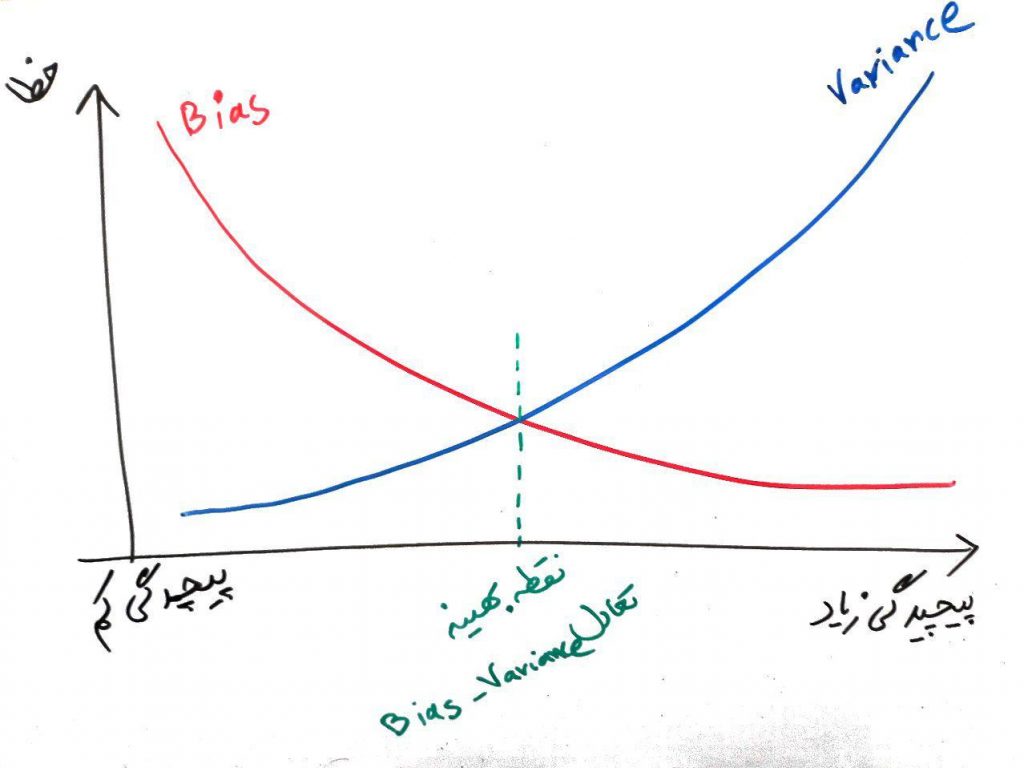
تفسیر شکل بالا ساده است. با زیاد شدن پیچیدگیِ یک مُدل (مثلا یک الگوریتمِ طبقهبندی که از دادهها یادگیری را انجام داده باشد)، Variance زیاد می شود (خط آبی) و با کم شدن پیچیدگی Bias زیاد می رود (خط قرمز). و زیاد شدن هر دو باعث بالا رفتن مقدار خطای کل میشود (محور عمودی). همان طور که میبینید در نقطه سبز رنگ (که یک پیچیدگی معقول دارد) مقدار bias و variance در حد معقول و نرمالی قرار میگیرد. از یک طبقهبند خوب انتظار میرود مدلی بسازد که یک پیچیدگی معقول (در نقطهای نزدیک به نقطه سبز) به دست بیاورد. یعنی نه زیاد پیچیده باشد و نه زیاد ساده. مانندِ این است که بگوییم یک معلم (در حال تدریس) نباید زیاد مسئلهی درس را پیچیده کند چون دانشجو چیزِ خاصی یاد نمیگیرد و ممکن است گیج شود و همچنین نباید زیاد مسئله را ساده کند چون آن وقت خیلی چیزهایی که دانشجو باید یاد بگیرد در سادهسازی از بین میرود.
برای رسیدن به این نقطه سبز راهکارهای مختلفی وجود دارد. یکی از آنها این است که دادههای آموزشیِ خود را به دو بخش آموزش و تست تقسیم کنیم. طبقهبند را بر اساس بخش دادههای آموزشی بسازید و بعد از آن یک ارزیابی با توجه به دادههای جدا شدهی بخشِ تست انجام دهید تا بتوانید بفهمید که آیا bias یا variance رخ داده است یا خیر. در ادامهی دورهی طبقهبندی بیشتر به این موارد پرداخته و در مورد آنها صحبت میکنیم.

- ۱ » الگوریتم K نزدیک ترین همسایه (KNN)
- ۲ » درخت های تصمیم جهت طبقهبندی (Decision Trees)
- ۳ » الگوریتم درخت تصمیم ID3 و ساختار Entropy و Gain
- ۴ » آشنایی با مفهوم Overfitting و Underfitting در طبقهبندی
- ۵ » آشنایی با مفهوم Bias و Variance در طبقهبندی
- ۶ » الگوریتم طبقهبندی درخت تصمیم C4.5
- ۷ » الگوریتم طبقه بند درخت تصمیم CART
- ۸ » طبقه بند ترکیبی (Ensemble Classifier) و مبحث Bagging و Boosting
- ۹ » الگوریتم جنگل تصادفی (Random Forest)
- ۱۰ » رگرسیون لجستیک (Logistic Regression)
- ۱۱ » مسائل طبقهبندی دودویی (binary)، چند کلاسه (Multi Class)، چند برچسبه (Multi Label) و تفاوت آنها
- ۱۲ » روش «یک در مقابل همه (One vs. All)» برای طبقهبندی دادههای چند کلاسه
- ۱۳ » روش «یک در مقابل یک (One vs. One)» در طبقهبندی
- ۱۴ » مدلهای احتمالی در مقابل مدلهای قطعی در طبقهبندی دادهها
- ۱۵ » ماتریس اغتشاش (Confusion Matrix) و معیار دقت (Accuracy)
- ۱۶ » معیار صحت (Precision)، پوشش (Recall) و معیار F
- ۱۷ » معیار کاپا (Kappa) برای ارزیابی طبقهبندیهای چندکلاسه
سلام
در شبکه عصبی مصنوعی درس داده کاوی نقش bias چیه؟
سلام
از توضیحات مختصر و در عین حال بسیار مفید و مفهومی که در مورد تک تک مباحث ارائه دادید بسیار سپاسگزارم.
این توضیحات باعث شد خیلی از نقاط تاریکی که در مورد چگونگی عملکرد این روشها وجود داشت برطرف بشن.
عالی بود.مچکرم از شما
عالی توضیح دادین ممنون.
عالی بود. در مورد کلاسه بندی چند کلاسه اگر مطلبی و منبعی هست لطفا معرفی کنید
سلام از توضیحات ساده و قابل فهم و جامع شما بسیار سپاسگزارم. توضیحات شما باعث برطرف شدن بسیاری از ابهامات من شد.
خدا خیرتون بده براتون آرزوی سلامتی و سربلندی در کار و زندگیتون را از خدا میخوام.
چقدر خوب توضیح میدین. هر بار که هر درس رو میخونم با خودم میگم خدا خیرتون بده…
هر چقدر تشکر کنم کمه….
بسیار خوب استفاده کردیم از مطالب قابل فهم شما
عااالی بود توضیحاتتون.
خیلی ممنونم.
محشر بود!!
یه استاد پروازی خنگ از تهران اومد چند میلیون گرفت +۱روز کامل اینا رو توضیح داد ،هیچی نفهمیدم.
الان متوجه شدم.
سلام
منظور از نقطه معقول و نرمال بایاس و واریانس چیه؟
منظورم اینه که هنوز خیلی درست درکش نمیکنم که بر اساس چه پارامتر هایی تغییر میکنه
آیا نقطه ی بهینه بایاس و واریانس همیشه یکجا قرار میگیره؟