

اگر درسِ مدلهای ترکیبی در طبقهبندی را خوانده باشید، درکِ الگوریتمِ جنگلِ تصادفی برای شما بسیار ساده خواهد بود. همانطور که در درسِ مدلهای ترکیبی (ensemble) برای الگوریتمهای طبقهبندی گفتیم، الگوریتمهای Ensemble از الگوریتمهای طبقهبندیِ ساده و ضعیفتر جهتِ تصمیمگیری استفاده میکنند. برای یادآوری شکل زیر را آوردهایم:
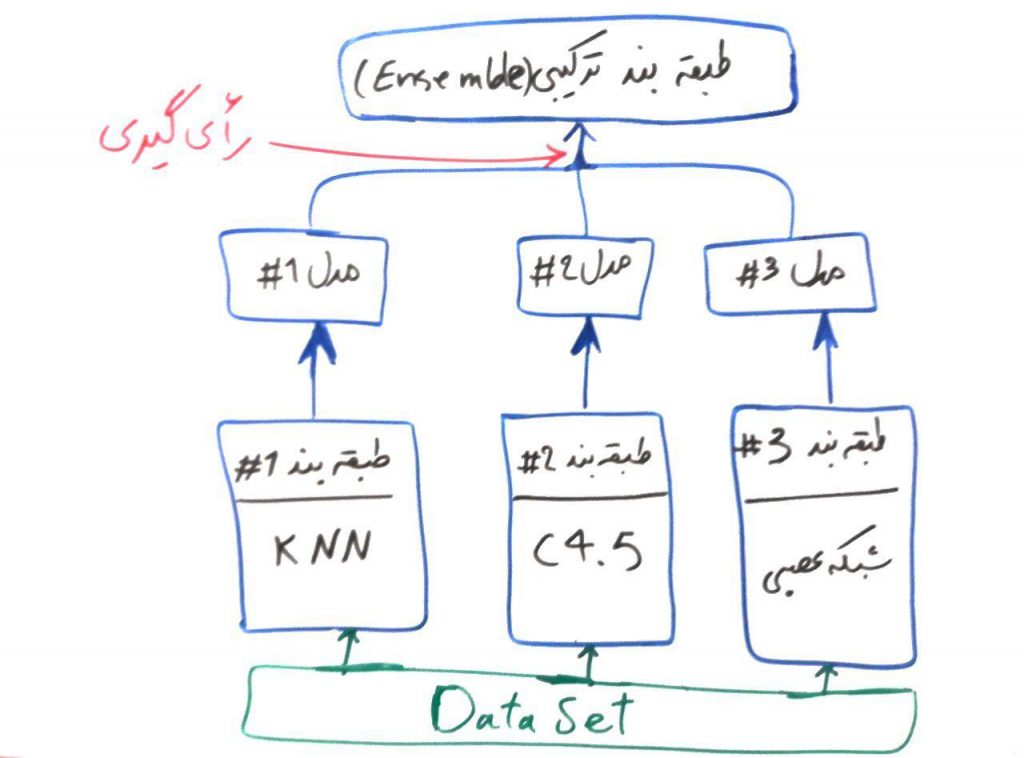
الگوریتمِ جنگلِ تصادفی یا همان Random Forest هم یک الگوریتمِ ترکیبی (ensemble) بوده که از درختهای تصمیم، برای الگوریتمهای ساده و ضعیفِ خود استفاده میکند. حتما درس درختهای تصمیم (decision trees) را مطالعه کردهاید و میدانید که یک الگوریتمِ درختِ تصمیم، میتواند به راحتی عملیاتِ طبقهبندی را بر روی دادهها انجام دهد. حال در الگوریتمِ جنگل تصادفی از چندین درختِ تصمیم (برای مثال ۱۰۰ درخت تصمیم) استفاده میشود. در واقع مجموعهای از درختهای تصمیم، با هم یک جنگل را تولید میکنند و این جنگل میتواند تصمیمهای بهتری را (نسبت به یک درخت) اتخاذ نماید.
در الگوریتم جنگل تصادفی به هر کدام از درختها، یک زیرمجموعهای از دادهها تزریق میشود. برای مثال اگر مجموعه دادهی شما دارای ۱۰۰۰ سطر (یعنی ۱۰۰۰ نمونه) و ۵۰ ستون (یعنی ۵۰ ویژگی) بود (درس ویژگیها و ابعاد را خوانده باشید)، الگوریتمِ جنگلِ تصادفی به هر کدام از درختها، ۱۰۰ سطر و ۲۰ ستون، که به صورت تصادفی انتخاب شدهاند و زیر مجموعهای از مجموعهی دادهها هست، میدهد. این درختها با همین دیتاستِ زیر مجموعه، میتوانند تصمیم بگیرند و مدلِ طبقهبندِ خود را بسازند. برای نمونه شکل زیر را در نظر بگیرید:
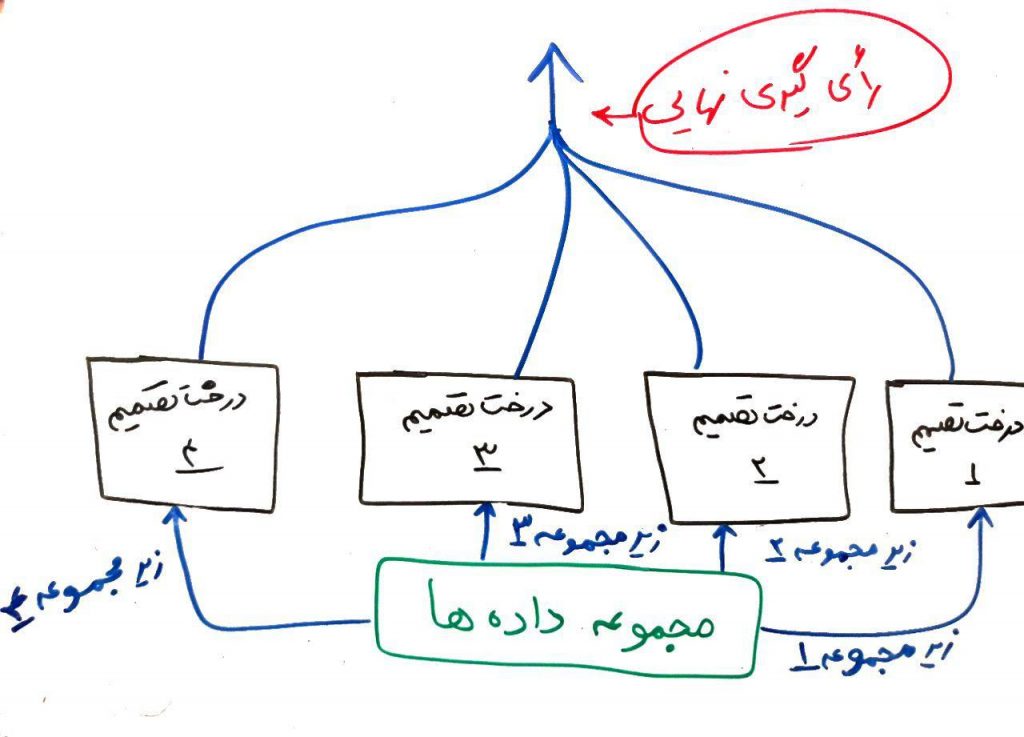
همانطور که مشاهده میکنید، مجموعهای از درختهای تصمیم وجود دارند که به هر کدام از آنها یک زیر مجموعهای از دادهها تزریق میشود. هر کدام از الگوریتمها عملیاتِ یادگیری را انجام میدهند. در هنگام پیشبینی، یعنی وقتی که یک سری دادهی جدید به الگوریتم، جهت پیشبینی داده میشود، هر کدام از این الگوریتمهای یادگرفته شده، یک نتیجه را پیشبینی میکنند. الگوریتمِ جنگلِ تصادفی در نهایت، میتواند با استفاده از رایگیری، آن طبقهای را که بیشترین رای را آورده است انتخاب کرده و به عنوانِ طبقهی نهایی جهت انجامِ عملیات طبقهبندی قرار دهد.

- ۱ » الگوریتم K نزدیک ترین همسایه (KNN)
- ۲ » درخت های تصمیم جهت طبقهبندی (Decision Trees)
- ۳ » الگوریتم درخت تصمیم ID3 و ساختار Entropy و Gain
- ۴ » آشنایی با مفهوم Overfitting و Underfitting در طبقهبندی
- ۵ » آشنایی با مفهوم Bias و Variance در طبقهبندی
- ۶ » الگوریتم طبقهبندی درخت تصمیم C4.5
- ۷ » الگوریتم طبقه بند درخت تصمیم CART
- ۸ » طبقه بند ترکیبی (Ensemble Classifier) و مبحث Bagging و Boosting
- ۹ » الگوریتم جنگل تصادفی (Random Forest)
- ۱۰ » رگرسیون لجستیک (Logistic Regression)
- ۱۱ » مسائل طبقهبندی دودویی (binary)، چند کلاسه (Multi Class)، چند برچسبه (Multi Label) و تفاوت آنها
- ۱۲ » روش «یک در مقابل همه (One vs. All)» برای طبقهبندی دادههای چند کلاسه
- ۱۳ » روش «یک در مقابل یک (One vs. One)» در طبقهبندی
- ۱۴ » مدلهای احتمالی در مقابل مدلهای قطعی در طبقهبندی دادهها
- ۱۵ » ماتریس اغتشاش (Confusion Matrix) و معیار دقت (Accuracy)
- ۱۶ » معیار صحت (Precision)، پوشش (Recall) و معیار F
- ۱۷ » معیار کاپا (Kappa) برای ارزیابی طبقهبندیهای چندکلاسه
با سلام خدمت آقای مهندس کاویانی من مطالب زیادی در خصوص داده کاوی مطالعه کرده بودم ولی هیچ کدام به روانی و سادگی و جذابی مقالات شما نبودمن با مطالعه مجموعه مقالات شما درک روشنی از داده کاوی پیدا کردم
از اینکه وقت گرانبهایتان را جهت ،اشتراک گذاری دانش خود قرار می دهید بسیار بسیار سپاسگذارم
سوالاتی داشتم از حضورتان :
۱- اگر ما بخواهیم روی یه دیتا ست کار مدلسازی را انجام بدهیم چگونه تشخیص بدهیم که باید از چه الگوریتم داده کاوی استفاده کنیم؟
۲- وسوال دوم اینکه آیا میشه روی یک دیتا ست که شامل ویژگی برچسب یا کلاس هست از الگوریتم های خوشه بندی استفاده کنیم بجای الگوریتم های طبقه بندی؟همیشه سلامت و پایدار باشید
سلام خدمت شما. لطف دارید
۱. برای اینکار روشهای مختلفی هست. یکی اینکه تجربه دادهها و الگوریتمهای مختلف را به دست بیاورید و الگوریتم مناسب را انتخاب کنید. روش دیگر استفاده از مدل Grid Search است که کار اصلی آن بدین صورت است که چندین الگوریتم مختلف را با پارامترهای متفاوت بر روی دادهها آزمایش میکند و سرانجام بهترین الگوریتم را با پارامترهای بهینه برای دادههای شما انتخاب میکند
۲. بله، طبیعتا انجام میشه. فقط ستون برچسب را باید نادیده بگیرید
سلام
از مطالب خوبتون متشکرم ولی اگه میشه پیاده سازی این الگوریتم ها را در زبان های برنامه نویسی مثل پایتون هم اموزش بدهید
تقریباً تمام این الگوریتم ها در کتابخانه ی sk-learn در پایتون وجود دارد ولی استفاده ی بهینه از این الگوریتم ها واقعاً کار سختی است اگه میشه در پایان هر اموزش یه مثال نوشته شده با زبان پایتون بگزارید
سلام و درود
من هم از مطالب بسیار مفید سایت تان که با زبانی قابل فهم نوشته شده اند بسیار متشکرم. لطفا در صورت امکان پس از هر آموزش، یک مثال در زبان پایتون اجرا کنید. خیلی ممنون
مطالب بسیار عالی ، روان و مفید بودند.
اگر این مطالب به همراه بخش های ریاضی برای بهتر درک شدن بودند خیلی جالب می شد.
با تشکر
سلام خیلی قشنگ و روان توضیح داده شده خیلی راحت متوجه شدم. فقط اگر بخوام اینو توو پایان نامه استفاده کنم باید منبع ارایه بدم. میشه راهنمایی کنید مقاله یا کتابی برای منبع؟
یه سوال دارم
برنامه ای بنويسيد كه دو دسته داده A و B هر يك حاوي تعدادي داده دو مولفه اي )قابل نمايش بصورت دو بعدي(
را نمايش دهد. براي توليد دادگان، مي بايست بردار ميانگين و ماتريس كواريانس را به همراه تعداد دادگان در هر
دسته از كاربر دريافت و دادگان را مطابق توزيع نرمالي با آن ميانگين و واريانس، توليد و بصورت گرافيكي نمايش
دهد.
عالی بود.
عالی بود
سلام آقای مهندس.
مطلبی که بیان کردید در مورد جنگل تصادفی بسیار شیوا و روان بود. متشکرم.
سوالی که دارم اینست که چه موقع باید از این الگوریتم استفاده کنیم؟ یعنی این الگوریتم چه ویژگی متفاوت و برجسته ای نسبت به سایر الگوریتمهای موجود دارد؟ البته من از این الگوریتم می خواهم در پیش بینی استفاده کنم. اما پیش بینی را به روشهای دیگر هم می توان انجام داد. مثل فازی، الگوریتم ژنتیک، کلونی مورچگان و …
وجه تمایز مهم این الگوریتم با سایر الگوریتمها چیست؟
متشکرم
ممنون از مطلب خوبتون.
سوالی که پیش میاد اینه که چرا جواب جنگل تصادفی بهتر از درخت تصمیم هست ؟
آیا دلیلش برمیگرده به این که چون داریم از چند تا درخت استفاده میکنیم ؟ یا توضیح علمی تری هم وجود داره.
متشکرم.
خواهش میکنم
توضیح علمیتر هم وجود دارد که معمولاً در مقالات به آن ارجاع میشود. ولی در کل به دلیل استفاده از روشهای ترکیبی(Ensemble) امید هست که نتایج بهتری گرفته شود. معمولاً این اثباتها را با مقایسه دو الگوریتم(جنگل تصادفی و درخت تصمیم) بر روی دیتاستهای مختلف انجام میدهند.
خیلی عالیه
بسیار زیبااااااااا
تمام مطالب اموزشی این سایت عالی هست
ممنون از شما باز هم مطلب بزارید
قسمت شبکه عصبی رو باز هم ادامه بدید
سلام عرض ادب وقت تون بخیر
اول بابت مطالب تون بسیار سپاسگزارم
یک سوال در مورد random forest feature importance دارم:
در مثال هایی که در این مبحث در سایت های مختلف ذکر شده، یک مجموعه دیتاست، دارای یک تعداد مشخص سطر(نمونه) هست که هر نمونه دارای یک تعدا مشخص ویژگی می باشد. شما هم در بیان مبحث، به همین صورت بیان فرمودین:
“برای مثال اگر دیتاست شما دارای ۱۰۰۰سطر(۱۰۰۰نمونه) و ۵۰ستون(یعنی ۵۰ ویژگی) بود….”
سوال من این است که اگر هر ویژگی، دارای سه بخش باشد، میتوان از این الگوریتم استفاده نمود؟
در مثال شما هر ویژگی، یک بخش می باشد.
در مثالی که برای من سوال هست، دیتاست من، ۱۰۰ نمونه دارد، هر نمونه، ۵۶ ویژگی دارد که هر ویژگی دارای ۳ بخش می باشد. آیا اماکن دارد با الگوریتم random forest feature importance، مشخص کنیم کدام ویژگی دارای تاثیر بیشتری هست؟
سلام
ممنون، لطف دارید
یکی از روشها این است که میتونید هر ویژگی را به سه ویژگی خورد کنید و در نهایت تعداد ۳ برابر ویژگی خواهید داشت و یا اینکه از شبکههای عصبی عمیق کانولوشنی برای این قبیل دادهها استفاده کنید
سلام
ممنون بابت آموزش خوبتون. کاملا شیوا و گوبا. مختصر و مفید.
امیداورم پاینده و سربلند باشید.
سلام خوب هستین؟
روزتون بخیر عرض ادب
اول بابت پاسخ گویی و مطالب تون بسیار سپاسگزارم:)
میخواستم بدونم تعدادِ درختان تصمیم، تاثیری در نتایج دارد یا نه؟
من برای پیاده سازی از matlab استفاده میکنم و از دستورِ TreeBagger استفاده میکنم. در این دستور، اولین پارامتر ورودی، NumTrees، می باشد و ساختار دستور بصورت زیر می باشد:
Mdl = TreeBagger(NumTrees,Tbl,ResponseVarName)، و توضیحات این دستور به شرح زیر است:
returns an ensemble of NumTrees bagged classification trees trained using the sample data in the table Tbl. ResponseVarName is the name of the response variable in Tbl.
آیا پارامتر NumTrees، تعداد درختان رو تعیین میکنه؟
آیا کم یا زیاد کردن این پارامتر، تاثیری در دقت نتایج دارد؟
دیتاست مورد استفاده من، دارای ۱۰۰سطر(۱۰۰نمونه) و ۳۰ ستون(یعنی ۳۰ ویژگی) می باشد.
هدف من از استفاده از random forest، تعیین variable importance ویژگی ها می باشد.
مثلا اگر پارامترِ NumTrees را برابر ۲۰ بگیرم، دقتِ نتایج بیشتر از موقعی است که NumTrees را برابر ۵ بگیرم؟ آیا میتوانم اصلا NumTrees را برابر مقادیر بالا مثلا ۵۰ یا ۱۰۰ بگیرم که منجر به دقت بالاتر شود؟
ممنون مرسی سپاسگزارم
سلام و عرض ادب و خسته نباشید و تشکر فراوان
ای کاش جناب مهندس میتونستید دوره و کلاس حضوری یا آنلاین بگذارید و مباحث رو برای دانشجویانی مثل بنده که میخواهیم کار پژوهشی در این زمینه رو آغاز کنیم خوب توضیح بدید. من برای پذیرش در دوره دکتری خارج از کشور نیاز به مقاله و پژوهش در طبقه بندی دارم و قصد دارم پایان نامه ام هم همین باشه… و دنبال یه منبع خوب و کامل برای شروع هستم. اگر لطف بفرمایید یک منبع خوب مثل خودتون و البته کاملتر… معرفی کنید تا آخر عمر ممنون و دعاگوی شما خواهم بود.
انشاله همیشه سلامت باشید
با سلام و احترام
از مطالب مفیدتون بسیار سپاسگزار. سوالی که داشتم این است که برای پایان نامه ارشد موضوع داده کاوی آموزشی را انتخاب کرده ام و اینم میدونم که درخت تصمیم در داده های آموزشی بهترین الگوریتم شناخته شده. حال به نظر شما الگوریتم جنگل تصادفی با توجه به تعداد ویژگی های نه چندان زیاد میتواند مناسب باشد یا خیر. سپاسگزار
سایت شما محشرررره ….. ممنون از محبتی که دارید
سلام سایتتون خیلی عالیه ممنون
فقط میتونید درمورد one class random forest ها هم توضیح بدید ممنون میشم؟
سلام مطالبتون واقعا عالیه
امکانش هست درمورد الگوریتم های درختان تصمیم ارتقای گرادیانی (XGBoost) هم مطلب بزارید