

آیا تا به حال شده بخواهید یک وسیلهی سنگین را بلند کنید و یک نفره نتوانید این کار را انجام دهید؟ احتمالاً برای این کار از چند نفر کمک گرفتهاید و با کمکِ آنها، وسیلهی سنگین را بلند کردهاید. در واقع تکتکِ شما قدرتِ این را ندارید که این میز را بلند کنید، بنابراین از ترکیب کردنِ قدرتتان با یکدگیر برای انجامِ این کار استفاده میکنید. طبقهبندهای ترکیبی که به ensemble methods معروف هستند، همین کار را انجام میدهند. در این درس میخواهیم با مفهومِ طبقهبندهای ترکیبی و روشهای موردِ استفاده در آن صحبت کنیم.
طبقهبندهای ترکیبی از ترکیبِ چندین طبقهبند (classifier) استفاده میکنند. در واقع این طبقهبندها، هر کدام مدلِ خود را بر روی دادهها ساخته و این مدل را ذخیره میکنند. در نهایت برای طبقهبندیِ نهایی یک رایگیری در بین این طبقهبندها انجام میشود و آن طبقهای که بیشترین میزانِ رای را بیاورد، طبقهی نهایی محسوب میشود.
همان طور که در دروسِ گذشته دیدیم، هر طبقهبند یک مدل را بر روی دادههای آموزشی میسازد تا به وسیلهی آن بتواند تفاوتها را در طبقههای مختلف درک کند. طبقهبندِ ترکیبی، اما به جای اینکه خود یک مدل بسازد از مدلهای ساخته شده توسطِ بقیهی طبقهبندها استفاده کرده و با یک رایگیری، مشخص میکند که کدام طبقه را برای نمونهی جاری باید برگزیند. شکلِ زیر یک نمونه از طبقهبندِ ترکیبی است:
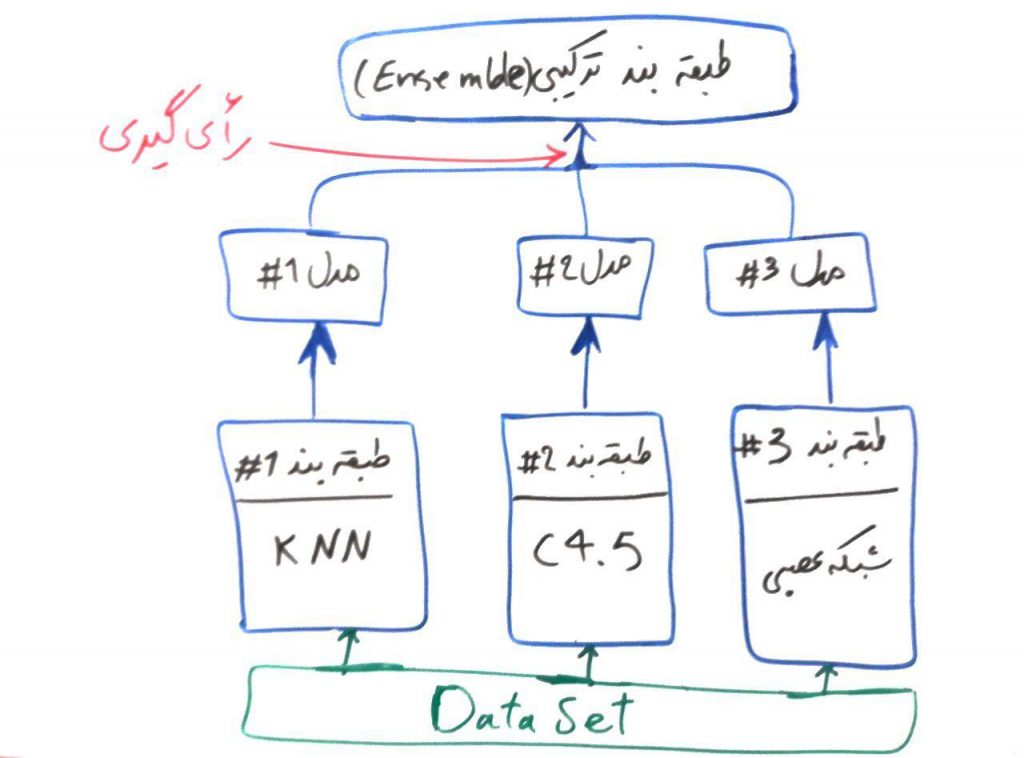
در شکل بالا، از سه الگوریتمِ پایه به نامهای KNN (نزدیک ترین همسایه)، درخت تصمیم C4.5 و شبکههای عصبی استفاده شده است. هر کدام از آنها توسط مجموعهی داده، یادگیری را انجام میدهند و مدلِ خود را میسازند. مثالِ پراید و اتوبوس را از دورهی شبکه عصبی به یاد بیاورید. فرض کنید این مجموعهی دادهی پراید و اتوبوس را به این سه الگوریتم دادهایم و هر کدام از این الگوریتمها، مدلِ خود را بر روی این مجموعهی داده ساختهاند. حال در این مثال یک نمونهی جدید که نمیدانیم پراید است یا اتوبوس به این سه الگوریتم داده میشود. مدلهای شمارهی ۱# و ۲# این نمونه را پراید طبقهبندی میکنند، این در حالی است که مدلِ شمارهی ۳# این نمونه را اتوبوس طبقهبندی میکند. پس الگوریتم ترکیبیِ نهایی، این مدل را بر اساس رایِ اکثریت (در اینجا ۲ به ۱)، در نهایت پراید طبقهبندی میکند.
پایهی الگوریتم های طبقهبندی ترکیبی (ensembleها) همان مثالی بود که در بالا گفتیم و اما دو روشِ معروف برای ساخت الگوریتمهای طبقهبندِ ترکیبی وجود دارند. bagging و boosting که در ادامه به آنها خواهیم پرداخت:
روش Bagging یا همان دستهبندی
همانطور که در شکل بالا مشاهده کردید، هر کدام از طبقهبندها، به مجموعهی داده (dataset) دسترسی دارند. در روش bagging یک زیر مجموعه از مجموعه دادهی اصلی به هر کدام از طبقهبندها داده میشود. یعنی هر طبقهبند یک قسمت از مجموعهی داده را مشاهده کرده و باید مدل خود را بر اساس همان قسمت از دادهها که در اختیارش قرار گرفته است، بسازد (یعنی کلِ دیتاست به هر کدام از طبقهبندها داده نمیشود). برای مثال شکل زیر را نگاهی بیندازید:
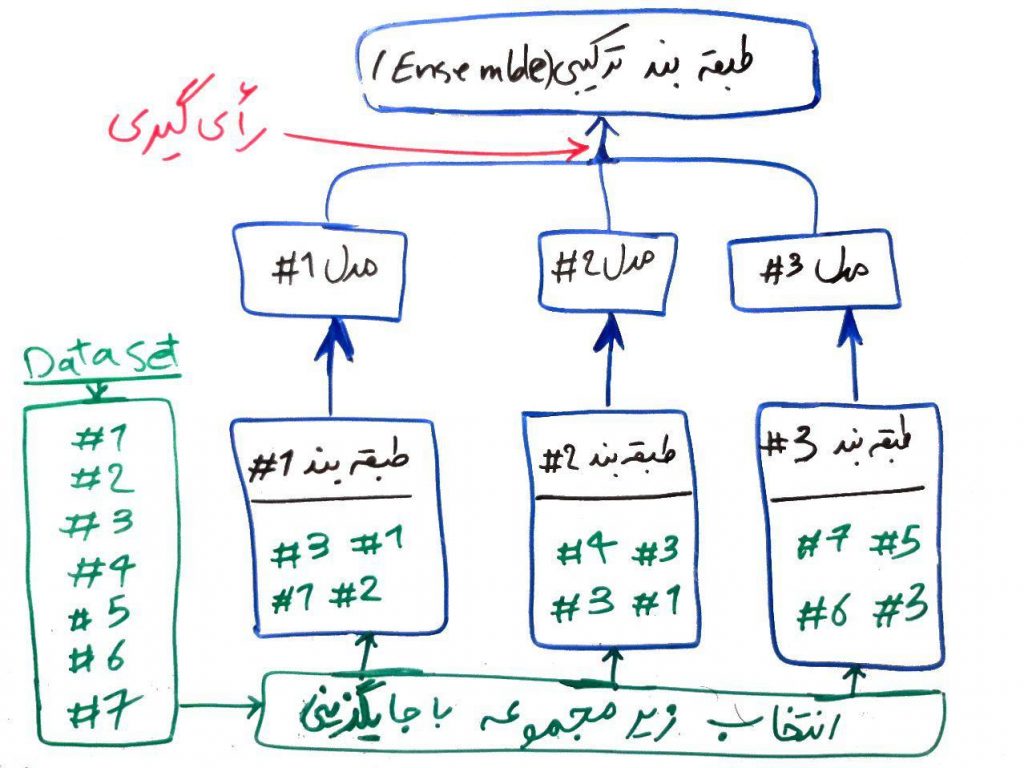
در این شکل، مجموعه دادهی ما دارای ۷ نمونه (مثلاً ۷ اتومبیل) است. برای هر کدام از طبقهبندها، یک زیرمجموعه از دادههای اصلی انتخاب میشود. انتخابِ این زیر مجموعه با جایگزینی خواهد بود. یعنی یک نمونه میتواند چند بار هم انتخاب شود. برای مثال به طبقهبند شماره ۱# نمونههای ۳، ۱، ۱ و ۲ داده شده است. همان طور که میبینید نمونه ۱ دو مرتبه به طبقهبندِ شمارهی ۱# داده شده است. طبق روال، هر طبقهبند با استفاده از دادههایی که در اختیار دارد یک مدل ساخته و بقیهی کار مانند مثالِ قبل انجام میشود. تحقیقات نشان داده است که روشِ bagging برای الگوریتمهایی مانندِ شبکههای عصبی یا درختهای تصمیم که با تغییرِ کمِ نمونهها ممکن است طبقههای مختلفی ایجاد کنند (این الگوریتم ها به الگوریتمهای غیرثابت (unstable) نیز شناخته میشوند) میتواند مفید باشد.
روش Boosting یا تقویت کردن
برای توضیحِ روش boosting (تقویتی) اجازه بدهید یک مثال بیاوریم:
فرض کنید شما یک سری نمونه سوالِ امتحانی دارید. از ابتدا آنها را همراه پاسخِ داده شده میخوانید و یاد میگیرید. در حالِ خواندن آنهایی که برایتان مشکلتر است را علامتگذاری میکنید تا بعداً دوباره مرور کنید.
همین روش هم در boosting به کار گرفته میشود. در این روشِ طبقهبندِ اول که در مثالِ بالا طبقهبندیِ KNN با شماره ۱# بود، یک نمونه از دادهها را (مانند روش bagging) مشاهده میکند و طبقهبند خود را میسازد. سپس از همان نمونههای مجموعهی آموزشی به او داده میشود و این طبقهبند احتمالاً برخی از نمونهها را اشتباه ارزیابی میکند. حال برای انتخابِ زیر مجموعهی دادهها برای طبقهبند دوم (۲#) در روش boosting، آن نمونههایی که طبقهبندِ اول نتوانسته است به درستی طبقهبندی کند، با احتمالِ بیشتری برای طبقهبندِ دوم انتخاب میشود. در واقع نمونههای سختتر، احتمال انتخاب بیشتری نسبت به سادهترها دارند. به همین ترتیب برای ایجاد یک زیر مجموعهی داده برای طبقهبندِ سوم، آنهایی که در طبقهبندهای اول و دوم مشکلتر به نظر میرسیدند، با احتمال بیشتری انتخاب میشوند.
طبقهبندهای ترکیبی عموماً از overfit شدنِ مدلِ یادگرفته شده توسطِ الگوریتم، جلوگیری میکنند و در بسیاری از موارد نتایج بهتری نسبت به الگوریتمهای دیگر تولید میکنند.

- ۱ » الگوریتم K نزدیک ترین همسایه (KNN)
- ۲ » درخت های تصمیم جهت طبقهبندی (Decision Trees)
- ۳ » الگوریتم درخت تصمیم ID3 و ساختار Entropy و Gain
- ۴ » آشنایی با مفهوم Overfitting و Underfitting در طبقهبندی
- ۵ » آشنایی با مفهوم Bias و Variance در طبقهبندی
- ۶ » الگوریتم طبقهبندی درخت تصمیم C4.5
- ۷ » الگوریتم طبقه بند درخت تصمیم CART
- ۸ » طبقه بند ترکیبی (Ensemble Classifier) و مبحث Bagging و Boosting
- ۹ » الگوریتم جنگل تصادفی (Random Forest)
- ۱۰ » رگرسیون لجستیک (Logistic Regression)
- ۱۱ » مسائل طبقهبندی دودویی (binary)، چند کلاسه (Multi Class)، چند برچسبه (Multi Label) و تفاوت آنها
- ۱۲ » روش «یک در مقابل همه (One vs. All)» برای طبقهبندی دادههای چند کلاسه
- ۱۳ » روش «یک در مقابل یک (One vs. One)» در طبقهبندی
- ۱۴ » مدلهای احتمالی در مقابل مدلهای قطعی در طبقهبندی دادهها
- ۱۵ » ماتریس اغتشاش (Confusion Matrix) و معیار دقت (Accuracy)
- ۱۶ » معیار صحت (Precision)، پوشش (Recall) و معیار F
- ۱۷ » معیار کاپا (Kappa) برای ارزیابی طبقهبندیهای چندکلاسه
سلام خسته نباشید استاد
نظر من این هست که تاریخ پست ها رو مشخص کنید.
ممنون
سلام و ممنون
بله، در نظر داریم در طراحی جدید این موضوع را هم در صورت امکان در نظر بگیریم
ممنون از توجهتون
با سلام و احترام
خیلی ممنون و متشکرم بخاطر آموزش بسیار عالی تمامی این دروس منسجم با بیانی ساده، روان و فصیح.
البته طبقه بندهای ترکیبی به همین دو نوع محدود نمی شوند و انواع دیگری مانند Stack Generalization نیز وجود دارند
سلام .ممنون از درسنامه خوبتون.ببخشید من یه سوال داشتم.اخیرا مطلبی مطالعه میکردم که از ensemble of regression trees استفاده کرده بود .خواستم بدونم در این مورد هم معنای ensemble همینی هست که در این درسنامه اومده؟؟و ایا میتونین اطلاعاتی درباره ensemble of regression trees در اختیارم بذارین؟
سلام و ممنون از توجهتون
بلی، به احتمال زیاد منظور همین مورد است. ما در دروس آینده به تدریج در حال تکمیل این بخش و الگوریتمهای مختلف هستیم
سلام خیلی ممنون از ارائه مطالب کاملا قابل فهمتون فقط من یک مشکل دارم که هیچ جا پیدا نمیکنم ممنون میشم منو متوجه این مطلب کنید
وزن دار کردن ویژگی یعنی چی؟
داده ها چی میشن که میگن وزن دارشون گردیم؟
سلام.در اینجا شما فرض کنید که ما ۳ مدل داشتیم با ۳ پیش بینی که از طریق مدل هامون بدست آورده ایم.حالا شما فرض کنید که ما میخوایم که از میانگین این پیش بینی ها استفاده کنیم.از طرفی شما میدونید که مثلا یکی از این مدل ها پیش بینی دقیق تری انجام داده است و ۲ تای دیگر برابرند.به خاطر همین ما میایم و به مدلی که دقیق تر پیش بینی کرده وزن بیشتری میدیم چرا که ماشین متوجه بشود که این مدل اهمیت بیشتری نسبت به سایرین دارد.
که اصطلاحا بهش میگن Average Weighted کردن که معمولا در الگوریتم هایی که class weight ندارند مثل MLP استفاده میکنیم
با سلام
در روش bagging برای ساخت الگوریتم ترکیبی، منظور از انتخاب زیرمجموعه با جایگزینی چیست؟ جایگزین شده با چی؟
ممنونم
منظور از جایگزینی( replacement) اینه که یک value از یک سطر، در مدلسازی تکرار بشه. مثلا تصور کنین دیتاست شامل اعداد ۱ تا ۱۰ باشه، تو مدل اول، مثلا ۳ بار عدد ۱ تکرار بشه، همین عدد یک شاید تو مدل بعدی یکبار، شایدم بیشتر و حتی شاید بصورت رندوم اصلا تکرار هم نشه. اینکه یه value چون در یه مدل برای train استفاده شده، بتونه تو مدل بعدی هم استفاده بشه بهش میگن replacement.
سلام وقت بخیرخسته نباشیدسوالی داشتم ازمحضرتان ، ما،دربوستینگ یک مجموعه دیتاست داریم درابتدایه تعدادی رکوردازاون دیتاستمون انتخاب میکنیم بعدبه اون رکوردهاخودمون وزن میدیم وبراساس الگوریتم مدلمون رومیسازیم ودرمرحله بعدی دوباره میاییم یه تعدادرکوردجدیدازمجموعه دیتاستمون برمیداریم؟؟؟؟یاهمون رکورداولی روداریم وبررواون کارمیکنیم وبراین اساس که وزن های رکوردمون اگرب اشتباه وزن گذاری شده باشن دوباره باالگوریتموون وزن دهیش میکنیم ومدل میسازیم دوباره درسته؟؟؟؟این روال روتاکی ادامه میدیم؟؟؟؟ایادرهرمرحله اگوریتمی که استفاده کردیم یکیه یعنی درهر۴ مرحله svmبکارمیبریم؟یامیتونیم دریک مرحله svm ودرمرحله دیگه درخت تصمیم و…بکارببریم؟؟؟واینکه ازکجاوچجوری تشخیص میده که رکوردامون درست وزن دهی نشدن؟؟؟ممنون میشم راهنماییم کنین
سلام استاد کاویانی
ممنون بابت توضیحات روان و مفیدتون.
من ی سوال داشتم.
این تکنیک های ensemble learning (الگوریتم های طبقه بندی ترکیبی به طور کلی منظورمه) قابل استفاده در نرم افزار های Weks و Rapidminer هم هستن؟
ممنون میشم راهنمایی کنید
سلام
لطف شماست
بله، در اینجا مثالی از RandomForest در رپیدماینر آورده شده است
همچنین در اینجا مثالی از Ensemble Learning در وکا موجود هست
سلام خدمت شما
چطور میشه در وکا چند الگوریتم مختلف رو در bagging و boosting استفاده کرد؟؟؟
چون انگار فقط یک الگوریتم رو میشه انتخاب کرد. در منابع انگلیسی هم چیزی ندیدم
خیلی متشکرم از راهنماییتون
البته لینک دومی باز نمیشه..اگر امکانش هست مجدد زحمت ارسالش رو بکشید..
ممنون
چقدر خوب و عالی توضیح دادید. بسیار ممنون.
سلام استاد کاویانی عزیز، وقتتون بخیر، خیلی متشکرم از آموزش عالیتون.
یه درخواستی داشتم، میشه در مورد روش های طبقه بندی ترکیبی stacking و voting هم آموزش بذارین؟ توی منابع لاتین توضیحشون رو متوجه نمیشم. ممنون میشم اگه آموزششون رو بذارین یا اگه لینکی که ساده توضیحشون داده باشه رو لطف کنید معرفی کنین. بازم ممنون
سلام از آموزشهای ارزشمند شما بسیار متشکرم توضیحات روان و گویا همراه با مثالهایی که در ذهن خواننده ماندگار میشوند. هرگاه در مباحث داده کاوی سوالی دارم همواره مقالات سایت chistio اولین سایتی است که مراجعه میکنم.
خواهشی داشتم اگر امکان دارد لطف کنید درباره پیاده سازی majority voting در Matlab هم راهنمایی بفرمایید بسیار سپاسگزار خواهم بود
باز هم از سایت عالیتون خیلی ممنونم موفق باشید
بسیار عالی ممنون از توضیحات روان و کاملتون .موفق باشید
سلام.ممنون از سایت فوق العاده مفیدتون
یه سوالدارم و اینکه که توی پایتون ‘voting=hard’ از کدوم روش رای گیری داره استفاده میکنه؟!bagging هست یا boosting؟!
سلام
خواهش میکنم
کدوم چهارچوب یا کتابخانه در پایتون مد نظرتون هست؟
لطفا تفاوت بین الگوریتم کیسه گذاری (Bagging) و جنگل تصادفی (Random Forest) را هم بنویسید.
ممنون از مطالب خوبتون
با سلام و تشکر مطالب بسیار خوب و آموزنده بود
با سلام مجدد
در صورت امکان مطالبی در خصوص داده های نامتوازن چند کلاسه در این آموزش اضافه کنید
سپاسگزارم
با سلام و احترام
مطالب آموزشی بسیار خوب و مفیدی بود
لطفا در صورت امکان مطالبی در خصوص داده های نامتوازن چند کلاسه در این آموزش اضافه کنید سپاسگزارم
آیا می توان ۳ الگوریتم C4.5 و نزدیکترین همسایه و شبکه عصبی را ترکیب کرد و در شناسایی حملات آزمایش کرد؟
باید جایزه معلم و استاد نمونه به شما داده بشه از بس خوب مینویسید بزرگوار
خدا خیر دنیا و آخرت بهتون بده،من فردا صبح دفاع دارم و تا حالا انقدر عمیق آدابوست را متوجه نشده بودم
یک دنیا ممنون از توضیح عالیتون.