

KNN شاید سادهترین الگوریتم در بحثِ طبقهبندی باشد. میخواهیم با یک مثال بسیار ساده شروع کنیم. فرض کنید شما یک فروشگاهِ مواد غذایی و دو دسته مشتری دارید، مشتریانِ دسته اول، کسانی هستند که بیشتر از ۱۰۰ هزار تومان در هر بار مراجعه از شما خریداری میکنند و دستهی دوم مشتریانی هستند که در هر مراجعه معمولاً کمتر از ۱۰ هزار تومان خرید میکنند. شما که فروشندهی با تجربهای هستید، به سبب چند سالی که در این مغازه فعالیت دارید میدانید که مشتریان دستهی اول خانمهایی هستند که سن بالای ۴۰ سال دارند و با اتومبیل به فروشگاه شما میآیند (مثلاً در مراجعهی آنها به این الگو دقت کردهاید). و دستهی دوم، یعنی همان مشتریانی که کمتر از ۱۰ هزار تومان از شما خریداری می کنند. معمولاً آقایانی هستند که سن زیر ۲۵ سال دارند و بدون اتومبیل به فروشگاه میآیند. حال فرض کنید، یک مشتری جدید به فروشگاه آمده است. این شخص یک خانم ۴۵ ساله است که با اتومبیلِ خود به فروشگاه آمده. شما این مشتری جدید را در کدام دسته (با توجه به مشتریان قبلی) قرار میدهید؟ انتظار دارید که این شخص چقدر از شما خرید کند؟
قطعاً بدون فکر کردن، دستهی اول را برای پاسخ به سوالِ بالا انتخاب میکنید. دلیل آن بسیار ساده است. این خانم ۴۵ ساله با اتومبیل، بسیار نزدیکتر به مشتریانِ دستهی اول است تا مشتریانِ دستهی دوم (دستهی دوم، آقایانی بودند که زیر ۲۵ سال سن داشتند و بدون اتومبیل به فروشگاه میآمدند). واژه نزدیکتر، در واقع پایهی عملیاتِ طبقهبندیِ K نزدیکترین همسایه میباشد. در این الگوریتم، هر کدام از نمونههای جدید (مثلاً مشتریهای جدید) با تمامی نمونههای قبلی مقایسه میشوند و به هر کدام از نمونههای قبلی که نزدیکتر باشند، به آن دسته از نمونهها تعلق می گیرند. این دقیقاً همان کاری است که در مثال اول توسط فروشندهی با تجربهی فروشگاه مواد غذایی انجام شد.
حال که مثال اول را درک کردید، اجازه بدهید به یک مثال علمیتر بپردازیم. فرض کنید شما مدیریت یک بانک را بر عهده دارید و میخواهید از بینِ کسانی که درخواستِ وام کردهاند، آن هایی را انتخاب کنید که به احتمال زیاد میتوانند وام خود را بازگردانند. فرض کنید برای این کار یک دیتاست (dataset) از مشتریانِ قبلیِ خود که وام گرفتهاند را آماده کردهاید و به هر کدام از این مشتریانْ یک برچسبِ بله (یعنی توانستهاند وام را بازگردانند) و خیر (یعنی نتوانستهاند وام را بازگردانند) نسبت دادهاید. توجه کنید که اینها مشتریانِ قبلی شما هستند که وضعیت برگرداندنِ وام توسط آنها مشخص شده است. هر کدام از مشتریهای شما هم ۲ ویژگی دارد. ویژگی اول: خانه از خود دارد یا خیر (۰ به معنیِ خانه نداشتن و ۱ به معنیِ داشتنِ خانه از خود است)؟ ویژگی دوم: چند سال است که مشتری بانک است (یک عدد بزرگتر از ۰)؟ هر کدام از این ویژگیها برای تمامیِ مشتریان تکرار می شوند. نگاهی به شکل زیر بیندازید (یک دیتاست با ۶ نمونه و ۲ بٌعد و دارای برچسب):
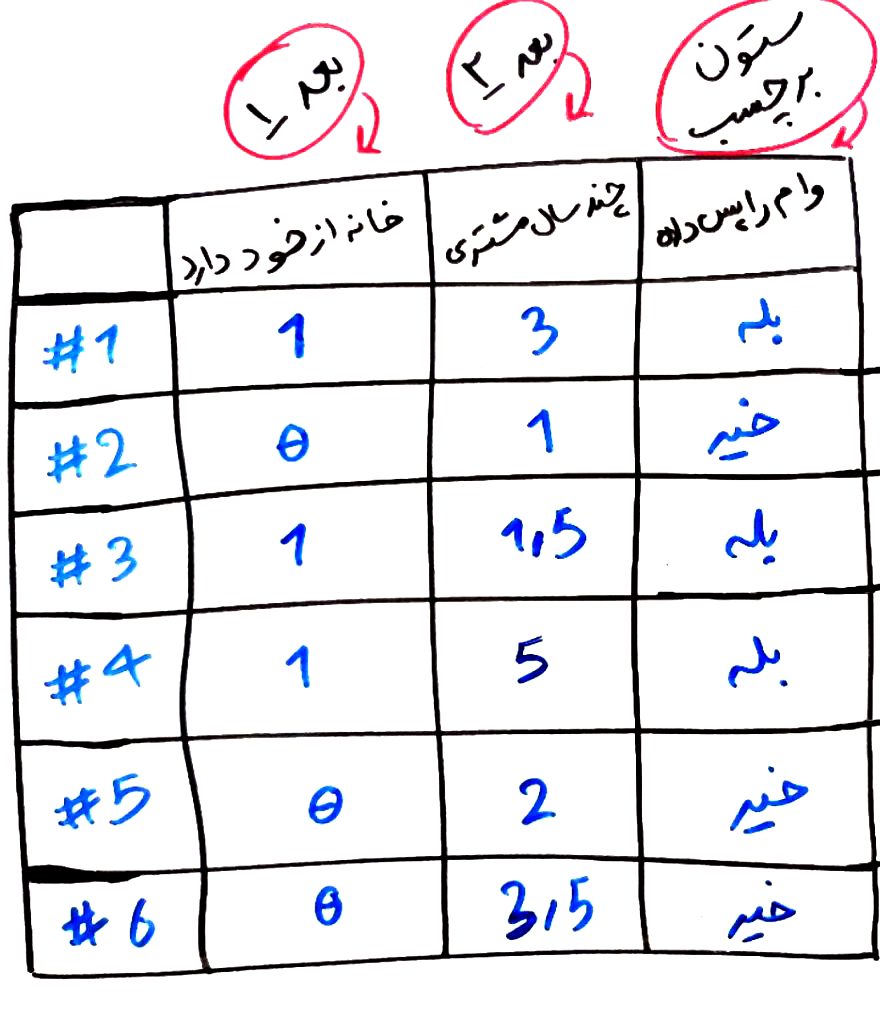
همانطور که میبینید ما ۶ مشتری داریم که هر کدام ویژگیهای خاصِ خود را دارند. مثلا مشتریِ اول خانه از خود دارد و ۳ سال است که مشتریِ بانک بوده و توانسته وام خود را پس بدهد. مشتریِ دوم خانه از خود ندارد، ۱ سال است مشتری بانک است و نتوانسته وام خود را پس دهد و به همین ترتیب برای بقیه مشتریان.
اجازه بدهید این مشتریان را بر روی یک نمودار رسم کنیم. توجه کنید که در اینجا دو ویژگی داریم، پس دو بُعد وجود دارد. ما محور افقی را خانه داشتن و محور عمودی را مدت زمان مشتریِ بانک بودن به سال، در نظر گرفتیم. هر کدام از نمونهها، اگر توانسته باشند وام خود را پس دهند، با رنگ سبز و اگر نتوانسته باشند وام خود را پس دهند با رنگ قرمز مشخص شدند. پس اگر بخواهیم جدول بالا را بر روی نمودار رسم کنیم مانند شکل زیر است:
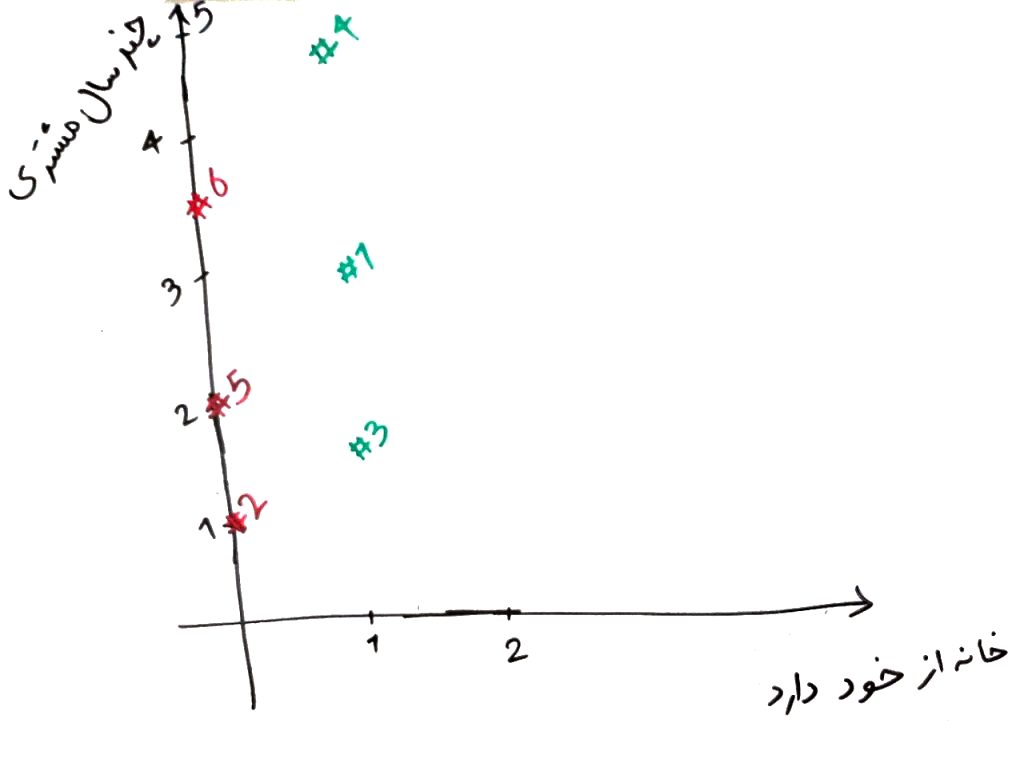
هر نقطه (#) بر روی این نمودار یک مشتری را نمایش میدهد. همان طور که میبینید یک تفکیک خوب بین مشتریانی که توانستهاند وام خود را پس دهند با کسانی که نتوانستهاند وام را پس دهند، وجود دارد. حال فرض کنید دو مشتریِ جدید با ویژگیهایی مطابق با جدول زیر متقاضیِ جدیدِ وام هستند و که میخواهیم تصمیم بگیریم به آن ها وام بدهیم یا خیر
| چند سال مشتری بانک است | خانه از خود دارد | |
| ۲/۵ | ۱ | new_1 |
| ۲ | ۰ | new_2 |
در الگوریتم KNN ابتدا بایستی فاصلهی هر نمونهی جدید را با نمونههای گذشته مقایسه کنیم. اما این مقایسه چگونه باید باشد؟ فرض کنید در شکل بالا میخواهیم مشتری new_1 را با مشتریهای قبلی مقایسه کنیم و فاصلهی این مشتری را با مشتریانِ دیگر به دست آوریم. برای این کار باید هر کدام از ویژگیهای مختلفِ مشتریِ جدید را با همان ویژگیهای موجود در یک مشتریِ قدیمی مقایسه کنیم (و از هم دیگر کم کنیم). سپس حاصلِ این کَمکردنها را با یکدیگر جمع کنیم. بگذارید برای نمونه فاصله مشتری new_1 را با تمامی ۶ مشتری قبلی محاسبه کنیم:
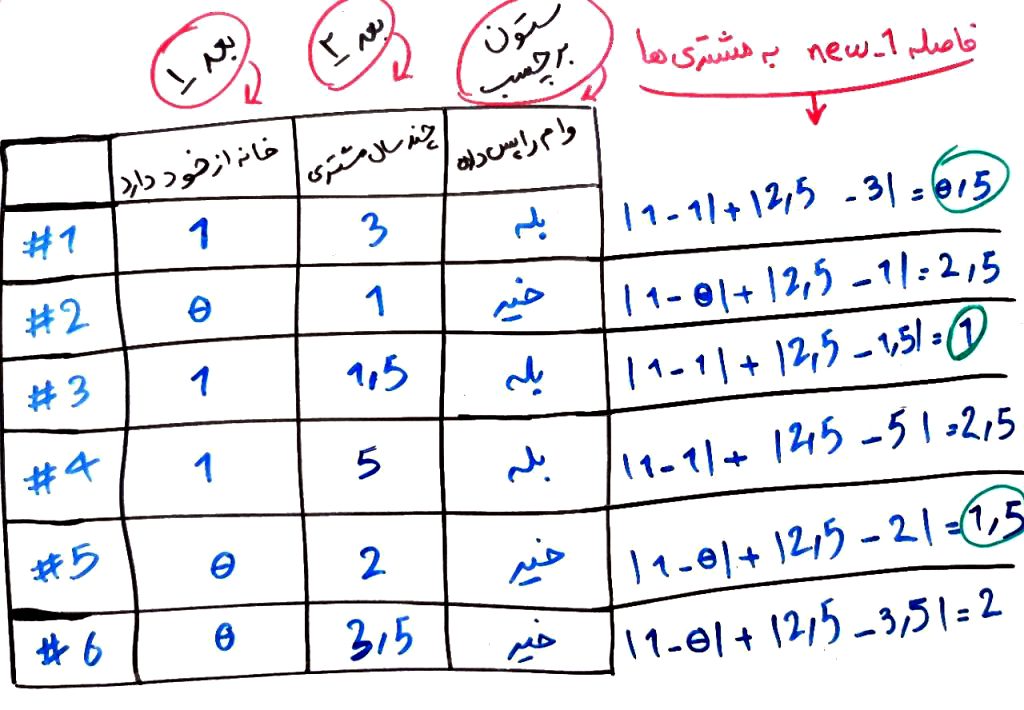
همانطور که مشاهده میکنید، هر کدام از ویژگیها را برای هر مشتریان از هم کم کردهایم. یعنی بُعد ۱ را برای مشتریِ جدید از بعد ۱ برای تکتکِ مشتریان قبلی کم کردیم و بُعد ۲ را نیز به همین ترتیب از بُعد ۲ برای تکتکِ مشتریان قبلی کم میکنیم. برای اینکه عددِ منفی به دست نیاید، قدر مطلق آنها را حساب می کنیم و سپس تمامیِ این کمکردنها را با هم جمع کرده ایم. در واقع بُعدهای مختلف را نظیر به نظیر با هم مقایسه کردهایم. به این کار، یعنی به دست آوردن تفاضل بُعدهای نظیر به نظیر و سپس جمع آنها، محاسبه فاصلهی منهتن میگویند که یکی از معیارهای فاصله برای دادههای چند بعدی، مانند همین مثال ما است. معیارهای فاصله دیگر نیز وجود دارد. مثلاً معیار اقلیدسی و یا معیار مینکوفسکی که فرمولهایی شبیه به هم دارند و در درسی جدا به هر کدام از این معیارها خواهیم پرداخت.
همان طور که میبینید فاصله مشتری new_1 برای ۶ مشتری در شکل بالا محاسبه شده است. اگر بخواهیم ۳ مشتریِ نزدیکتر به این مشتریِ جدید، از مشتریان قبلی را انتخاب کنیم، مشتریهای شماره ۱ و ۳ و ۵ هستند (که کمترین فاصله را در بین مشتریان دیگر به این مشتریِ جدید دارند) که دوتای آن ها توانستهاند وام را پس دهند و یکی از آن ها خیر. پس این مشتری نیز احتمالاً میتواند وام خود را پس دهد. این روش همان روش KNN است. در اینجا مقدار K برابر ۳ بود، یعنی ۳ مشتریِ نزدیک به مشتریِ جدید را انتخاب کردهایم و برچسبِ اکثریت این ۳ مشتری را به عنوان برچسب برای مشتریِ جدید نیز درج میکنیم. مثلاً اینجا چون برچسبِ اکثریت، بازگرداندنِ وام بود (۲ تا بلی در مقابل یک خیر) پس این مشتریِ جدید نیز به عنوانِ کسی که میتواند وام را برگرداند برچسب گذاری میشود. در واقع الگوریتمِ KNN با توجه به مشتریانِ قبلی،میتواند یک مشتریِ جدید را (که برچسب واقعی او را نمیداند) پیشبینی کند. اگر بخواهیم بر روی تصویر نیز نمایش دهیم، مشاهده میکنید که مشتری جدید new_1 به مشتری های قبلیِ ۱ و ۳ و ۵ نزدیکتر از بقیه بود.
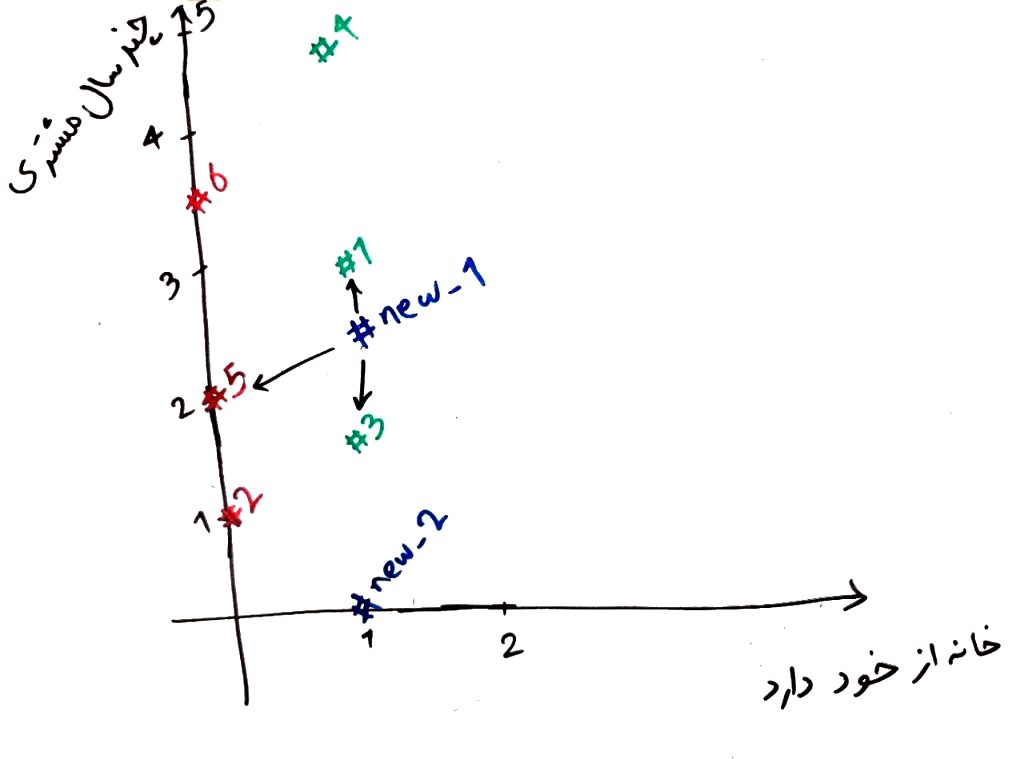
تمرین: فاصله مشتری new_2 را با ۶ مشتری قبلی مقایسه کنید. اگر K را برای الگوریتم KNN برابر ۳ قرار دهیم، آنگاه برچسب مشتری new_2 چه می شود؟ آیا این شخص میتواند وام خود را پس دهد یا خیر؟
همان طور که گفتیم الگوریتمِ KNN یکی از سادهترین الگوریتمهای دادهکاوی و طبقهبندی است. این الگوریتم عملیات طبقهبندی را به صورت ساده انجام داده و نتایجِ قابل اطمینانی به عنوان پیشبینی برمیگرداند. البته در اینجا ما به صورت ساده به دو بعد از یک مثال اشاره کردیم (مشتری خانه دارد یا خیر و اینکه چند سال است که مشتری بانک بوده است). در مسائل دنیای واقعی ممکن است ابعادِ بسیار بیشتری وجود داشته باشد. این مسائل را دیگر نمیتوان روی بردارهای عمودی و افقی به صورت ساده رسم کرد و در واقع مسئلههایی در فضای ۳ بعدی یا بیشتری میشوند. البته تجسم کردن آن از لحاظ فیزیکی قابل شکلسازی نیست ولی در ذهنِ خود به راحتی میتوانید این فضاها را تجسم کنید. مثلاً به جای اینکه در اینجا مشتری دو بُعد داشته باشد میتواند ۱۰ بعد داشته باشد که هر کدام یک ویژگیِ مشتری را نمایش میدهد.

- ۱ » الگوریتم K نزدیک ترین همسایه (KNN)
- ۲ » درخت های تصمیم جهت طبقهبندی (Decision Trees)
- ۳ » الگوریتم درخت تصمیم ID3 و ساختار Entropy و Gain
- ۴ » آشنایی با مفهوم Overfitting و Underfitting در طبقهبندی
- ۵ » آشنایی با مفهوم Bias و Variance در طبقهبندی
- ۶ » الگوریتم طبقهبندی درخت تصمیم C4.5
- ۷ » الگوریتم طبقه بند درخت تصمیم CART
- ۸ » طبقه بند ترکیبی (Ensemble Classifier) و مبحث Bagging و Boosting
- ۹ » الگوریتم جنگل تصادفی (Random Forest)
- ۱۰ » رگرسیون لجستیک (Logistic Regression)
- ۱۱ » مسائل طبقهبندی دودویی (binary)، چند کلاسه (Multi Class)، چند برچسبه (Multi Label) و تفاوت آنها
- ۱۲ » روش «یک در مقابل همه (One vs. All)» برای طبقهبندی دادههای چند کلاسه
- ۱۳ » روش «یک در مقابل یک (One vs. One)» در طبقهبندی
- ۱۴ » مدلهای احتمالی در مقابل مدلهای قطعی در طبقهبندی دادهها
- ۱۵ » ماتریس اغتشاش (Confusion Matrix) و معیار دقت (Accuracy)
- ۱۶ » معیار صحت (Precision)، پوشش (Recall) و معیار F
- ۱۷ » معیار کاپا (Kappa) برای ارزیابی طبقهبندیهای چندکلاسه
سلام جناب مهندس ممنون از نشر مطلب مفیدتون.
سوالی که برام پیش آمد این بود که چطور میشه بدون رسم نمودار تشخیص داد نمونه جدید به کدام یک از نمونه های قدیمی نزدیکتر است ؟
لطفا در صورت امکان یک کپی از پاسختان را به آدرس ایمیلم ارسال کنید .
” قلمتان پایدار “
با سلام
دوست عزیز نیازی به رسم نمودار نیست. نمودار به دلیل روشنتر شدن مبحث رسم شده است. در واقع هر کدام از خانههای آرایه، برای یک نمونه، یک بعد را نشان میدهد که بایستی با بعدهای متناظر خود در نمونههای دیگر مقایسه شود
سلام آقای مهندس
خیلی ممنون!
قدرت توضیح تون خیلی عالیه!
اگه یه کتاب بنویسین خیلی خوشحال میشم🙂
خیلی عالی بود امتحان داشتم و از کتابا هیچی نمی فهمیدم
فرشته نجاتم شدی.ممنونم
سلام در مورد طبقه بند LDA توضیح میدهید خیلی مطالعه کردم ولی کاملا متوجه نشدم بیزحمت توی ورد برام میل میکنید
میتونم ای دی تلگرام داشته باشم
متشکرم
باسلام
LDA جزو الگوریتمهای خوشهبندی(Clustring) مطرح میشود که در درسی جدا به آن خواهیم پرداخت
بسیارعالی
سلام درود بسیار ساده و مفید و به کمال حق مطلب رو ادا کردید. این مباحث رو برای استفاده از طبقه بندها در فناوری میخواستم برای پایان نامه استفاده کنم . با استفاده از درس شما براحتی مفاهیم و واژه های بکار بده شده در مقاله های لاتین را درک و استباط نموده وتوانستم مقالات مورد نظر رو پیدا نمایم. البته با توجه به اینکه من چند روز برای انتخاب موضوع بیشتر فرصت نداشتم با مرور درس شما در چند ساعت موفق شدم . براتون دعا خیر وسلامتی می نمایم
عرض سلام و وقت بخیر
سوال اولم اینکه مقدار k چگونه به الگوریتم داده میشود؟
و سوال دومم اینکه اگر مقدارش زوج باشد و تعداد کلاس های نزدیکترین همسایه هایش یک اندازه باشد چطور؟
سلام و ممنون از توجهتون
معمولاً K را شخصِ برنامهنویس به الگوریتم میدهد.(البته مقدار K را با زیاد و کمکردن میتوان تنظیم نمود و به مقدار بهینهی آن رسید)
در اغلب موارد مقدار K را فرد میدهند و یا اگر زوج باشد یکی از راهها، این است که اگر تعداد کلاسها یک اندازه شد، K را برای آن حالت یکی افزایش میدهند و در واقع یک همسایهی نزدیکِ اضافهتر را مشاهده میکنند و با توجه به آن تصمیم میگیرند.
غلط املایی در نوشتن کلمه “فاصله منهتن” در متن وجود دارد. متشکرم
ممنون از اینکه اطلاع دادید. درست شد
سلام استاد محترم
اگر امکان داره در مورد راههای پیدا کردن نرخ یادگیری (etha) راهنمایی بفرمایید ممنون
لطفا در مورد knn regressionتوضیحاتی با مثال بدین
بسیار عالی.ممنونم
با عرض سلام و ادب
بسیار زیبا، روان و ساده درس دادید من کتابهای زیادی در مورد این مباحث خواندم ولی به جرات می توانم بگویم هیچ کدام از انها اینقدر کاربردی و قشنگ درس نداده بودند واقعا جا دارد به شما خدا وقت و خسته نباشید بگم و امید وارم راهی که در پیش گرفتید را تا انتها ادامه دهید. این مطالب ارزش صدبار خواندن هم دارد پس اگر این مطالب را در قالب کتاب و مجموعه ای نیز عرضه کرده اید و در سایت بگذارید من یکی از مشتری همیشگی شما خواهم بود.
سلام جناب کاویانی.
ممنون به خاطر توضیحات ساده و روان.چند تا خواهش و سوال داشتم.
اول این که میشه در مورد روش AdaBoost هم توضیح بدید در یک جلسه. من گشتم ولی چیزی پیدا نکردم.
دوم این که آیا بنا دارید دوره آموزشی برای Tensorflow برگذار کنید؟ دوره ای خیلی کامل و جامع. اون دوره کوچیکه برای شروع خوبه ولی اگه جامع تر باشه به نظرم خیلی بهتر میشه.
سوال سوم هم که اصلا ربطی به بحث نداره ولی ممنون میشم جواب بدید.
آخر هر جلسه یه قسمت به نام “ترتیب پیشنهادی خواندن درسهای این مجموعه به صورت زیر است:”. میخواستم بپرسم برای این قسمت از چه افزونه ای استفاده میکنید.
باز هم ممنون. واقعا ساده و روون توضیح میدید.
مرسی.
سلام
بله، الگوریتم Adaboost رو هم توضیح خواهیم داد
در آینده نزدیک هم چند دوره تکنیکی(ویژه) جهت Tensorflow قرار میدهیم
افزونه خاصی نیست. با استفاده از ترتیبهای زمانی خود وردپرس هست
سلام
در حالتی که هر کدوم از بعدها خودشون آرایه (با طول مشخص) باشند از چه روش سوپروایزدی میشه واسه طبقه بندی استفاده کرد
سلام
اگر منظورتان Tensorها هستند، احتمالاً روشهای شبکه عصبی عمیق به درد بخور هستند
البته که با تغییر ویژگیها، میتوان مسئله را با الگوریتمهایی مانند KNN حل کرد
سلام
بسیار مفید و مختصر
ممنونم
سلام مهندس خسته نباشید
اگه امکانش هست در مورد الگوریتم VFDT هم مطلبی بزارین چون واقعا هیچکدوم از سایت ها … مطلبی ندارن
خیلی ممنون میشم ازتون اگه هم مطلبی داشتین و تونستین برام ایمیل کنین.
تشکر
ممنون از توضیح روانتون
من که هرچی جزوه ام خوندم هیچی نفهمیدم
کاش همه استادها مثل شما اینقدر روان و ساده مسائل رو توضیح میدادن
سلام
بسیار مختصر و مفید، ساده و روان
نکته اینکه ظاهرا در تصویر آخر، new_2 اشتباه مشخص شده،
ظبق جدول new_2، خانه از خودش ندارد، ۲ سال مشتری بانک بوده = (۰,۲)
اما در تصویر نقطه (۱,۰) علامت زده شده
درسته؟!
منم همین فکرو میکنم… ۳ داده نزدیک بهش هر سه جزو یک کلاس هستن.
سلام. خیر. ببینید، مشتری new_2 یک مشتری فرضی دیگر است. یعنی نباید در جدول قبلی ما (همان دادههای قبلی ما) حضور داشته باشد. این یک مشتری جدید است که سابقهی حضور در بانک ندارد و فقط یک خانه از خود دارد.
عالی بود توضیحاتتون. معمولا نظری نمینویسم ولی حیفم اومد بی تفاوت از کنار زحمتتون بگذرم. پیروزو بهروز باشید
سلام
وقت بخیر لطفا در رابطه با خوشه بندی با الگوریتم pso منتشر کنید …