

در دورهی جبرخطی (Linear Algebra) بعد از مباحثِ پایهی ماتریسی، بحثهای کاربردیتری مانند SVD و ماتریس همبستگی را مطرح کردیم که به طورِ مستقیم در بسیاری از مسائل واقعی دنیای صنعت و تحقیقات علمی کاربرد دارند. در این درس میخواهیم به یکی از مباحثِ اصلی و پیشرفتهتر در جبر خطی بپردازیم که به آن آنالیز مولفه اصلی (Principal Component Analysis) یا به اختصار PCA میگویند. همچنین کاربرد آن را در مسائلِ حوزهی علومداده (Data Science) مشاهده کنیم.
یکی از کاربردهای اصلیِ PCA در عملیاتِ کاهشِ ویژگی (Dimensionality Reduction) است. PCA همانطور که از نامش پیداست میتواند مولفههای اصلی را شناسایی کند و به ما کمک میکند تا به جای اینکه تمامیِ ویژگیها را مورد بررسی قرار دهیم، یک سری ویژگیهایی را ارزشِ بیشتری دارند، تحلیل کنیم. در واقع PCA آن ویژگیهایی را که ارزش بیشتری فراهم میکنند برای ما استخراج میکند (اگر نمیدانید ویژگی یا بُعد چیست، حتما درس ویژگی چیست را خوانده باشید).
اجازه بدهید با یک مثال شروع کنیم. فرض کنید یک فروشگاه میخواهد ببیند که رفتار مشتریانش در خریدِ یک محصول خاص (مثلا یک کفش خاص) چطور بوده است. این فروشگاه، اطلاعات زیادی از هر فرد دارد (همان ویژگیهای آن فرد). برای مثال این فروشگاه، از هر مشتری ویژگیهای زیر را جمعآوری کرده است:
سن، قد، جنسیت، محل تولد شخص (غرب ایران، شمال ایران، شرق ایران یا جنوب ایران)، میانگین تعداد افراد خانواده، میانگین درآمد، اتومبیل شخصی دارد یا خیر و در نهایت اینکه این شخص بعد از بازدید کفش خریده است یا خیر. ۷ویژگیِ اول ابعاد مسئله ما را میساختند و ویژگیِ آخر هدف (Target) میباشد (در این باره در درس طبقهبندی صحبت کردهایم)
اگر درس ویژگی چیست را خوانده باشید میدانید که ویژگیهای بالا را میتوان برای مجموعهی داده (در اینجا مجموعه مشتریان فروشگاه) در ۷بُعد رسم کرد. حال به PCA بازمیگردیم. PCA میتواند آن مولفههایی را انتخاب کند که نقش مهمتری در خرید دارند. برای مثال، مدیرِ فروش به ما گفته است که به جای اینکه هر ۷بُعد را در تصمیمگیری دخالت دهیم، نیاز به ۳بُعد (۳ویژگی) داریم تا بتوانیم آنها را بر روی یک رابطِ گرافیکی ۳بُعدی به نمایش دربیاوریم. پس در واقع نیاز داریم ۷بُعد را به ۳بُعد کاهش دهیم. به این کار در اصطلاح کاهش ابعاد یا Dimensionality Reduction میگویند. PCA میتواند این کار را برای ما انجام دهد. PCA با توجه دادهها و دامنهی تغییراتِ هر کدام از آنها، میتواند ویژگیهایی را انتخاب کند که تاثیر حداکثری در نتیجه نهایی داشته باشند. در مثال بالا (فروشگاه)، فرض کنید ویژگی قد، تاثیر زیادی در اینکه یک فرد از فروشگاه خرید کند نداشته باشد. PCA این قضیه را متوجه میشود و در الگوریتمِ خود ویژگیِ قد را تا جای ممکن حذف میکند. در واقع در فرآیند تبدیلِ ۷ویژگی به ۳ویژگیِ نهایی (که با توجه به درخواست مدیرِ فروش به دنبال آن هستیم) PCA ویژگیِ قد را کمتر دخالت میدهد. اینگونه است که ویژگیهای مهمتر از نظر PCA وزن بیشتری در تولیدِ ویژگیهای کاهش یافته پیدا میکنند.
البته این بدان معنا نیست که در فرآیند کاهش ابعاد، PCA دقیقا همان ویژگی را حذف میکند. بلکه PCA توان این را دارد که به یک سری ویژگی جدید برسد. مثلا این الگوریتم ممکن است به این نتیجه برسد که افرادی که در شمال و غرب ایران زندگی میکنند و سنِ آنها بالای ۴۰سال است، احتمال خرید بالایی دارند در حالی که برعکس این قضیه احتمال خرید را بسیار کمتر میکند. در واقع اینجا PCA به یک ویژگی ترکیبی از محل تولد شخص و سن رسیده است. این دقیقا یکی از قدرتهای الگوریتم PCA در کار بر روی دادهها است.
حال بگذارید کمی ریاضیتر به قضیه نگاه کنیم. برای سادگی فرض کنید دادههای مشتریان ما کلا ۲بُعد دارند. سن و قد. حال (همانطور که در درس ویژگی چیست خواندید) آنها را بر روی محور مختصات نمایش میدهیم. فرض کنید شکلی مانند شکل زیر تشکیل میشود:
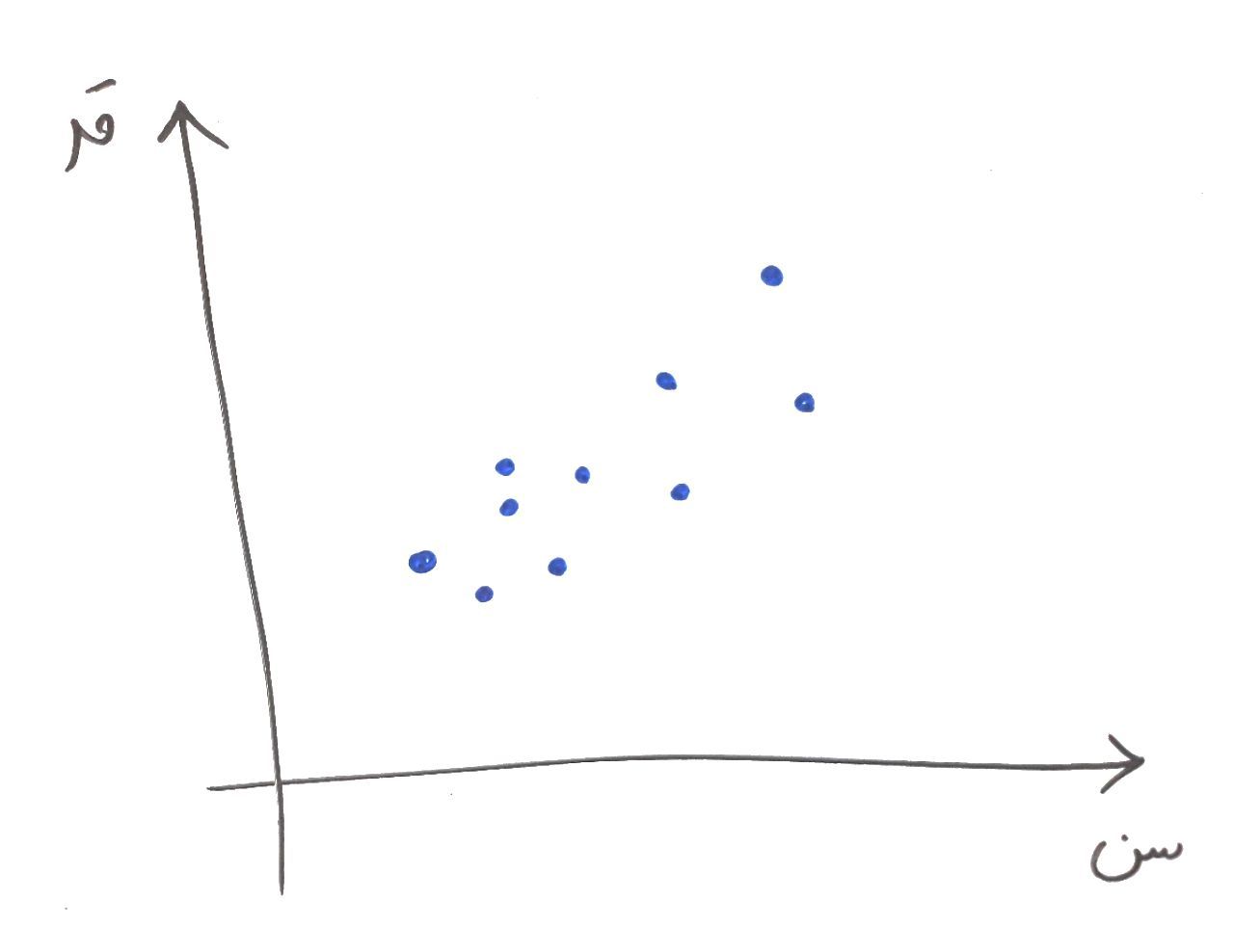
هر کدام از نقاط آبی رنگ، در مثال ما یک مشتری است که با توجه به ویژگی سن (محور افقی) و ویژگی قد (محور عمودی) در صفحه مختصات رسم شده است. همانطور که از درس بردار ویژه (Eigen Vector) به یاد دارید، بردار ویژه میتواند کمک کند تا در میان دادههای ما خطی کشیده شود که بیشترین دامنه تغییرات در امتداد آن خط رخ داده باشد. حال به تصویر زیر نگاه کنید:
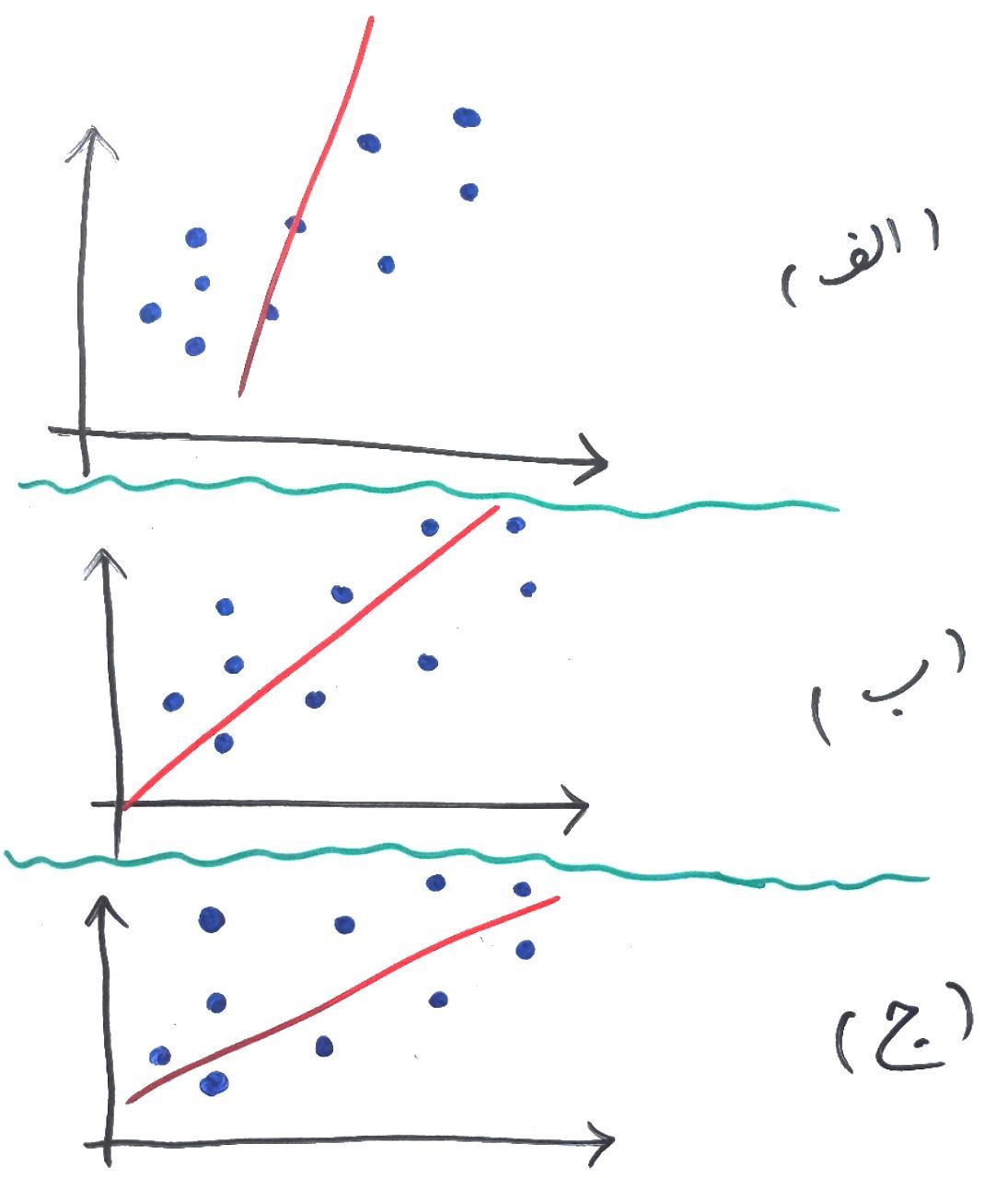
همانطور که گفتیم هر کدام از نقاط آبی رنگ، در مثالِ ما یک مشتری است که با توجه به ویژگی سن (محور افقی) و ویژگی قد (محور عمودی) در صفحه مختصات رسم شده است. فاصله هر نقطه آبی تا خط قرمز را میتوان به عنوان یک خطا (Error) در نظر گرفت و به تبعِ آن مجموعِ خطا برابر است با جمع فاصله تک تکِ نقاط آبی تا خط قرمز. به شکل زیر نگاه کنید، کدام تصویر (الف، ب یا ج) مجموع خطاهای کمتری دارند؟
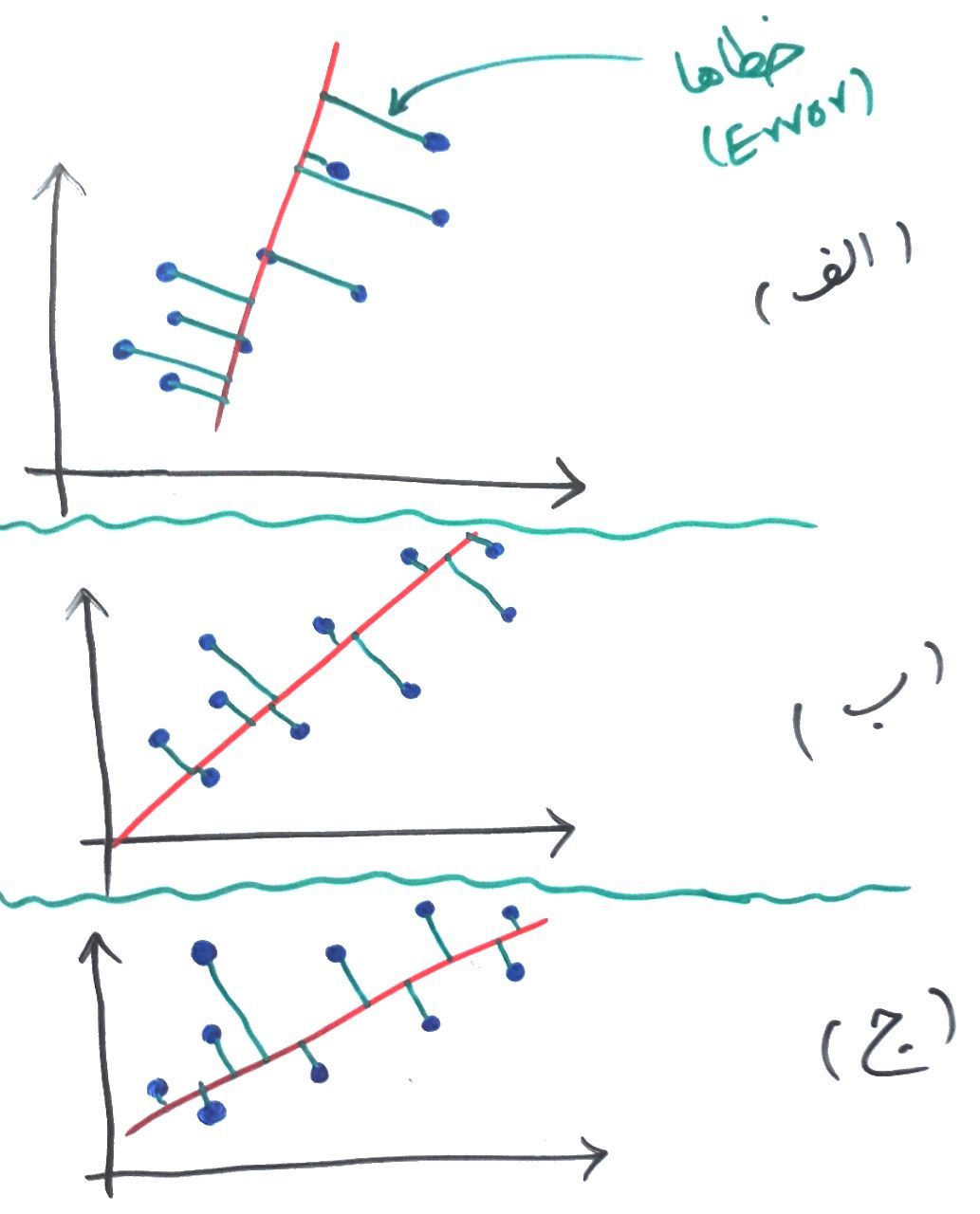
کمی دقت کنید. فاصله نقاط نسبت به خط قرمز با خط با رنگ سبز مشخص شدهاند. اگر جمع این فاصله (خطا – Error) را برای هر نمودار برابر خطای کلی دادهها نسبت به خط قرمز در نظر بگیریم، تصویرِ الف بیشترین میزان خطا را دارد و بعد از آن تصویر ب و در نهایت تصویر ج کمترین خطا را دارد. PCA به دنبال ساختنِ خطی مانند خط ج است (که در واقع همان بردار ویژه ماست) که کمترین خطا (Least Error) را داشته باشد. با اینکار هر کدام از نقاط بر روی خط قرمز نگاشت میشوند و در تصویرِ بالا که ۲بُعدی است میتوان این ۲بُعد را به ۱بُعد (که همان خط قرمز رنگ است) نگاشت کرد. در نهایت میتواند چیزی مانند شکل زیر رخ دهد:

در این مثال آخر ما ۲بُعد را به ۱بُعد کاهش دادیم. البته در مثالهای واقعی ممکن است ۱۰۰۰بُعد را به ۲بُعد کاهش دهند تا بتوان آن را بر روی یک نمودار به نمایش درآورد و این کار با با PCA انجام دهند که هم از سرعتِ معقولی برخوردار است و هم کیفیت قابل قبولی دارد.

- ۱ » عدد (Scalar)، بردار (Vectors)، ماتریس (Matrix) و تنسور (Tensor) چیست؟
- ۲ » ماتریسها و کاربرد آنها در دادهکاوی و یادگیری ماشین
- ۳ » نرم (Norm) بردار یا ماتریس چیست؟
- ۴ » انواع ماتریس و ویژگیهای مختلف آنها
- ۵ » چرا ماتریسها در علوم داده مهم هستند؟
- ۶ » معیارهای فاصله (Distance Measures) در یادگیری ماشین
- ۷ » بردار ویژه (Eigen Vector) و مقدار ویژه (Eigen Value) برای یک ماتریس
- ۸ » Singular Value Decomposition یا همان SVD در ماتریس چیست؟
- ۹ » ماتریس کواریانس (Covariance) و ماتریس همبستگی (Correlation) چیست؟
- ۱۰ » آنالیز مولفه اصلی (Principal Component Analysis) یا همان PCA چیست؟
- ۱۱ » دستگاه معادلات خطی (System of Linear Equations) در ماتریسها
با تشکر
لطفا روش LDA رو هم بررسی کنین
«تحلیل تشخیصی خطی» (Linear Discriminant Analysis | LDA) و هم تحلیل مولفه اساسی (PCA) از جمله روشهای تبدیل خطی هستند. PCA جهتهایی که واریانس دادهها را بیشینه میکنند (مولفه اساسی) مییابد، در حالیکه هدف LDA پیدا کردن جهتهایی است که جداسازی (یا تمایز) بین دستههای گوناگون را بیشینه میکند و میتواند در مسائل دستهبندی الگو (PCA از برچسب کلاس صرفنظر میکند) مورد استفاده قرار بگیرد. به بیان دیگر، PCA کل مجموعه داده را در یک (زیر)فضای دیگر طرحریزی میکند و LDA تلاش میکند تا یک ویژگی مناسب را به منظور ایجاد تمایز بین الگوهایی که به دستههای مختلف تعلق دارند تعیین کند.
برگرفته از
https://blog.faradars.org/%D8%AA%D8%AD%D9%84%DB%8C%D9%84-%D9%85%D9%88%D9%84%D9%81%D9%87-%D8%A7%D8%B3%D8%A7%D8%B3%DB%8C-pca-%D8%AF%D8%B1-%D9%BE%D8%A7%DB%8C%D8%AA%D9%88%D9%86/
عالی بود دمتون گرم.
سلام میشه چنتا رفرنس فوی جهت مباحثpcaوsvdمعرفیکنید براب مطالعه دقیق ابن دو مبحث نیاز دادم.
آقای مهندس خیلی روان توضیح میدین. خیلی عالیه مطالبتون من انقدر که از سایت شما چیزی یادگرفتم از دانشگاه یاد نگرفتم… خدا خیرت بده
باسلام وتشکر
به زبان ساده وراحتPCAراتوضیح دادین.
سوال من راجع به PCoA2,PCoA1
وتفاوت آن با PCAچیست؟
سلام .
اگر ممکن هست بفرمایید در چه صورتی دوبردار بدست خواهیم آورد و به چه علت؟
سلام
به ازای هر بُعد یک بردار به دست میآید
چون اینجا دو بُعد داریم، دو بردار هم ساخته میشود
امکانش هست lda هم توضیح دهید
ممنون
زنده باد. چقدر ساده و زیبا توصیح داده اید. ممنونم
ممنون از توضیحات کامل و واضح. ممنون می شم در مورد ایجن ولیو و ایگن وکتور ها هم یک توضیحی بفرمائید . اعداد منفی و مثبت چیست؟ چطور می شود از این اعداد استفاده کرد ؟ آیا میشود اعداد پی سی ای را به مقدار اولیه برگرداند ؟
با تشکر
ممنون از توضیح ساده و زیباتون. لطف میکنید روش به دست
اوردن PCA رو در spss هم توضیح بدید. با تشکر
خسته نباشی
pca چه تفاوتی با اتو انکدر دارد؟
خیلی ساده و روان توضیح دادید . تشکر
با سلام .. یک سوال دارم درمورد روش PCA .. میتونین برام حلش کنید ..
با تشکر
سپاس از توضیحات روان و ساده شما در رابطه با مباحث پیچیده. میشه لطف کنید بفرمایید روش PCA بر روی چه تعداد داده باید آزمون بشه اگر تعداد داده ها کم بود چطور باید تحلیل کرد؟؟
اموزش شما عالي بود
دانشجوي دكتري هستم انشا.. مباحث اماري مربوط به رساله ام را از شما بياموزم
با سلام برای اینکه کدام ویژگی را حذف کند ما باید انتخاب کنیم یا pca خودش انتخاب میکند؟
سلام خدمت شما
بستگی به پیادهسازی دارد. معمولاً PCA گزینههای ضعیف را نمایش میدهد و میتوانید آنها را حذف کنید
با سلام عرض احترام
بسیار سپاسگزار از بیان مطالب تخصصی به صورت متنی ساده و روان
در خصوص Random Projection Tree هم میشه توضیح بدید؟
سلام خسته نباشید
توضیحات بسیار عالی بودند.
برای مقایسه دو مجموعه داده pca کمکی به ما میکند؟ یا برای پیدا کردن dec چکار باید کرد؟
واقعا سابت عالی و مفیدی دارید
مختصر و مفید ، سپاس
بسیار ساده وروان توضیح دادید….
درود بر شما……
سلام خسته نباشید
ببخشید میشه توضیح بدین که وقتی مثلا تعداد متغیر ها ۹ تا باشه بر چه اساسی بفهمیم که کدوم یک از مولفه های به دست آمده (pc 1…..pc 5) را باید در مقادیر متغیر های اصلی باید ضرب کرد که شاخصمون به دست بیاد؟
ممنون میشم راهنمایی م کنین
چه خوب توضیح دادید، ممنون
سلام خسته نباشید
خیلی خوب و ساده توضیح دادید واقعا لذت بردم
ممنونم
سلام من دانشجوی ارشد فیتو شیمی هستم ونیاز ب پرو گرام PCAهستم برای قرار دادن داده های طیف ب وسیله دستگاه FTIRمیشه راهنمایی کنین برای دانلود یا گرفتن پروگرام