

در دروس گذشتهی دورهی جاری به بررسی ماتریسها و کاربردهای مختصر آن در دادهکاوی و یادگیری ماشین پرداختیم. یاد گرفتیم که ماتریسها میتوانند انواع دادهها را به صورت ساختاریافته در خود ذخیره کنند و با سرعت بالایی پردازش نهایی دادهها را انجام دهند. در این درس میخواهیم به برخی از مشهورترین معیارهای فاصله بین نمونهها در یک ماتریس از دادهها بپردازیم.
مجموعهی دادهی زیر که نمایانگر کاربران در یک اپلیکیشن پخش موسیقی (مانند Spotify) است را در نظر بگیرید:
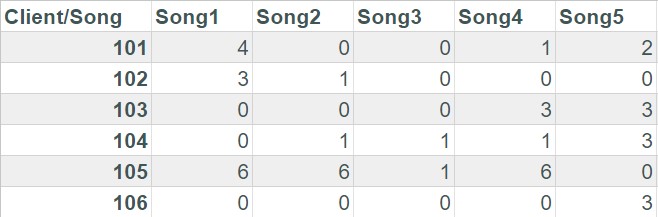
هر سطر از ماتریسِ شکل بالا یک کاربر را نمایش میدهد و هر ستون، نشاندهندهی تعداد دفعاتی است که آن کاربر، یک موسیقی خاص را پخش کرده است. برای مثال کاربر شمارهی ۱۰۱، تعداد ۴ مرتبه موسیقی شماره ۱ را پخش کرده و اصلا موسیقی شمارهی ۲ و ۳ را پخش نکرده است. همین کاربر به ترتیب ۱ مرتبه موسیقی شمارهی ۴ و ۲ مرتبه موسیقی شمارهی ۵ را پخش کرده است و به همین ترتیب برای بقیهی کاربران (سطرها) میتوان مجموعهی دادهی بالا را تفسیر کرد.
حال فرض کنید میخواهیم فاصلهی بین دو نمونه (در اینجا دو کاربر) یعنی دو سطر را اندازه بگیریم. کاربرانی که به یکدیگر نزدیکتر باشند، احتمالا سلیقهی موسیقیایی مشابهی به یکدیگر دارند و میتوان با استفاده از این اطلاعات، موسیقیهایی که کاربران مختلف احتمالاً علاقه دارند را به آنها پیشنهاد داد.
برای محاسبهی فاصلهی بین دو نمونه (هر نمونه را میتوان یک بردار در نظر گرفت) در یک ماتریس، معیارهای فاصلهی متفاوتی وجود دارد که در ادامه به برخی از مشهورترین آنها خواهیم پرداخت.
فاصلهی اقلیدسی (Euclidean Distance)
فاصلهی اقلیدسی بین دو نمونه (دو بردار) به صورت زیر محاسبه میشود:

در شکل بالا مشخص است که هر کدام از ابعاد (ستونها) را برای هر کدام از نمونهها (سطرها) از یکدیگر تفریق کرده و به توان ۲ میرسانیم. سپس حاصل این عبارات را جمع کرده و یک رادیکال از آن میگیریم. برای مثال اگر بخواهیم فاصلهی کاربر ۱۰۱ و ۱۰۳ در مجموعهی دادهی بالا را با توجه به معیار فاصلهی اقلیدسی محاسبه کنیم، به صورت زیر این محاسبه انجام میگیرد:

هر چقدر فاصلهی اقلیدسی بین نمونهها کمتر باشد، یعنی آن دو نمونه به یکدیگر نزدیکتر هستند. فاصلهی اقلیدسی، رابطهی مستقیمی با فاصلهی L2 Norm دارد.
فاصلهی منهتن (Manhattan Distance)
فاصلهی منتهن که به فاصلهی تاکسی (Taxicab) یا فاصلهی بلوکهای شهری (City Block) نیز معروف است شبیه به فاصلهی اقلیدسی عمل میکند با این تفاوت که در فرمول، توانِ ۲ و رادیکال نداشته و فقط قدر مطلقِ اختلافها را محاسبه میکند:
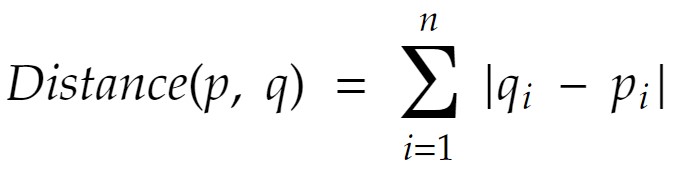
برای مثال اگر بخواهیم فاصلهی کاربر ۱۰۱ و ۱۰۳ در مجموعهی دادهی بالا را با توجه به معیار فاصلهی منهتن محاسبه کنیم، به صورت زیر این محاسبه انجام میشود:

فاصلهی منهتن رابطهی مستقیمی با فرمول L1 Norm نیز میگویند.
به صورت خلاصه در شکل زیر تفاوت بین فاصلهی منهتن و اقلیدسی را برای حالتی که دو نمونه (دو سطر) و دو بُعد (دو ستون) داریم مشاهده میکنید:
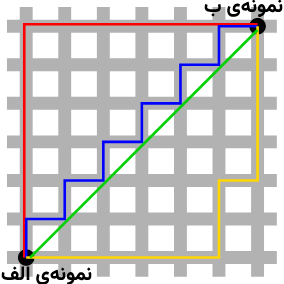
در شکل بالا، خط مستقیم بین دو نمونهی الف و ب (خط سبز رنگ)، فاصلهی اقلیدسی را نشان میدهد و خطوط دیگر (آبی، زرد و قرمز) هر کدام به نوعی نشاندهندهی فاصلهی منهتن هستند.
فاصلهی مینکوفسکی (Minkowski Distance)
فاصلهی میکوفسکی در واقع حالت عمومیِ فاصلهی اقلیدسی و فاصلهی منهتن است. این فاصله با استفاده از یک پارامتر به عنوان مرتبه (order) میتواند فرمول خود را تغییر دهد. فرمول کلی فاصلهی مینکوفسکی به صورت زیر است:
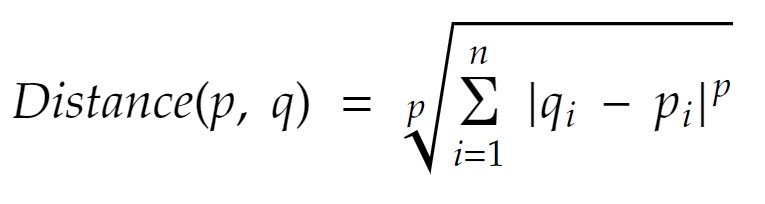
در شکل بالا اگر p برابر ۱ باشد، فرمول شبیه به فاصلهی منهتن شده و اگر p برابر ۲ باشد، فرمول شبیه به فاصلهی اقلیدسی میشود. در کاربردهای مختلف از فاصلهی مینکوفسکی معمولاً با پارامترِ p بین ۱ تا ۴ استفاده میشود.

- ۱ » عدد (Scalar)، بردار (Vectors)، ماتریس (Matrix) و تنسور (Tensor) چیست؟
- ۲ » ماتریسها و کاربرد آنها در دادهکاوی و یادگیری ماشین
- ۳ » نرم (Norm) بردار یا ماتریس چیست؟
- ۴ » انواع ماتریس و ویژگیهای مختلف آنها
- ۵ » چرا ماتریسها در علوم داده مهم هستند؟
- ۶ » معیارهای فاصله (Distance Measures) در یادگیری ماشین
- ۷ » بردار ویژه (Eigen Vector) و مقدار ویژه (Eigen Value) برای یک ماتریس
- ۸ » Singular Value Decomposition یا همان SVD در ماتریس چیست؟
- ۹ » ماتریس کواریانس (Covariance) و ماتریس همبستگی (Correlation) چیست؟
- ۱۰ » آنالیز مولفه اصلی (Principal Component Analysis) یا همان PCA چیست؟
- ۱۱ » دستگاه معادلات خطی (System of Linear Equations) در ماتریسها
سلام وقت بخیر
خوب و عالی و مخصوصا با مثال، توضیح و اموزش دادید
با سپاس فراون