

با تجزیهی یک عدد به اعداد اول که آشنا هستید؟ مثلا میگوییم عدد ۱۲ را میخواهیم به اعداد اول تجزیه کنیم. شکل زیر را مشاهده کنید:

این کار (تجزیهی یک عدد به اعداد اول) به ما در درکِ بهترِ ساختارِ یک عدد کمک میکند. همچنین ویژگیها و کاربردهای مختلف دیگری هم دارد. همانطور که میتوانیم یک عدد را به اعداد اول تجزیه کنیم، همینکار را هم میتوانیم برای ماتریسها انجام دهیم. یعنی یک ماتریس را به عواملِ سازندهی آن تجزیه کنیم. یکی از روشهای این تجزیه Singular Value Decomposition یا همان SVD است که خلاصهای از آن را در این درس خواهیم گفت.
فرمول زیر، پایهی SVD را تشکیل میدهد:
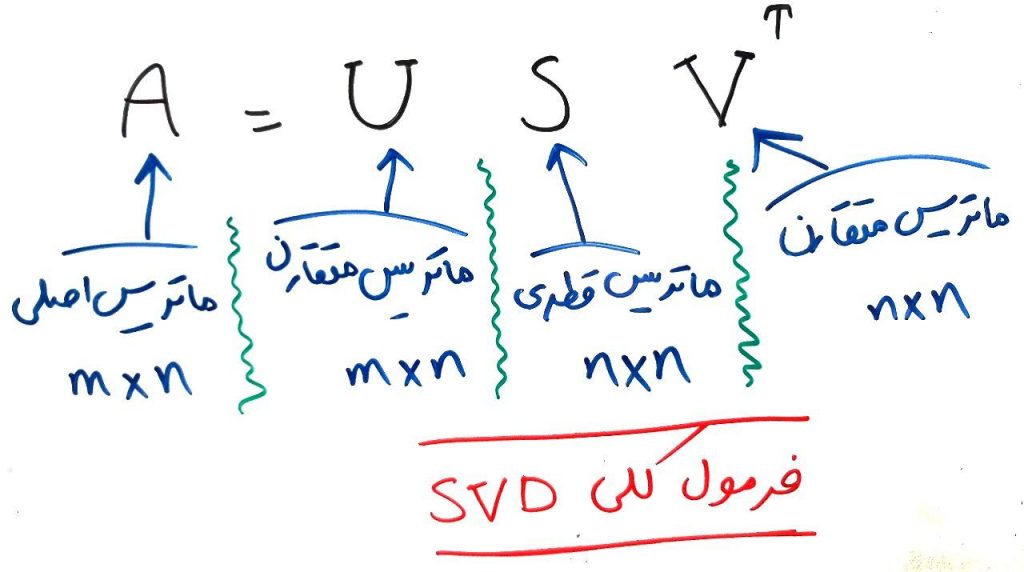
ماتریس ما میتواند به سه ماتریس دیگر شکسته شود. با انواعِ ماتریسها که در این درس آشنا شدید. ماتریسِ A یک ماتریسِ m در n است. یعنی m سطر دارد و n ستون. ماتریس U یک ماتریسِ m در n و متفارن است. ماتریسِ S یک ماتریسِ قُطری (diagonal) به صورت n در n است (یعنی فقط قطرِ اصلیِ آن عدد دارد و بقیه صفر است). ماتریسِ V هم یک ماتریس متفارنِ n در n است. در واقع ماتریسِ اصلی (ماتریس A) تشکیل شده از ضربِ این سه ماتریس U و S و ترانهادهی V است. به این کار در اصلاح تقسیمبندی (Factorization) میگویند و به این معنی است که ماتریسِ A میتواند از سه ماتریسِ U و S و V تشکیل شود. حتماً با ضرب ماتریسها آشنایی دارید و نیازی نیست این دوباره تکرار کنیم.
در زیر نمونهای از تقسیمبندی (Factorization) ماتریسِ A به سه ماتریس را نشان دادهایم:
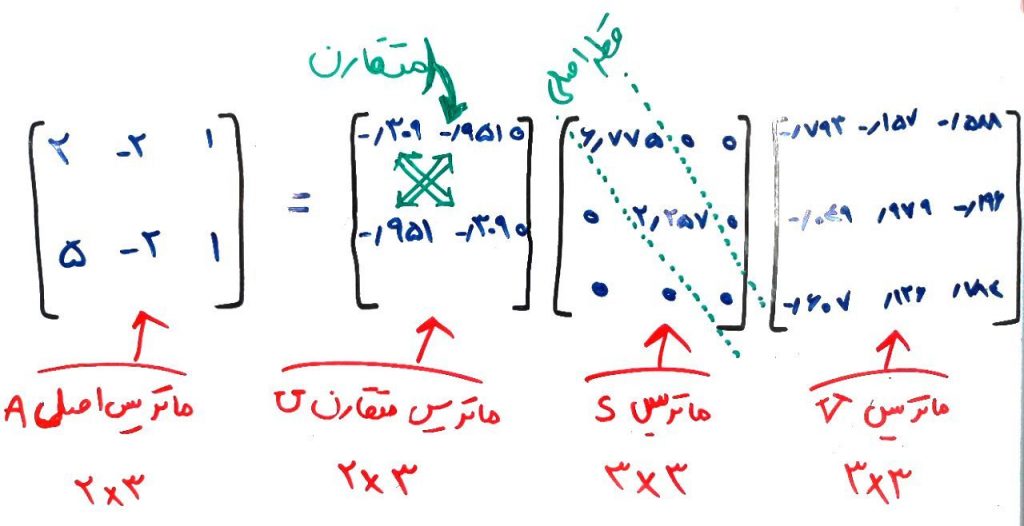
مقادیری که در S وجود دارد در واقع همان مقادیرِ منحصر به فردی (Singular) است که میتواند در عملیاتِ کاهشِ ویژگی به ما کمک کند. (درس ویژگی چیست را خوانده باشید). برای مثال با استفاده از تجزیهی ماتریس به کمک SVD میتوانیم متوجه شویم که کدام یک از ستونهای یک ماتریس، دارای اطلاعات بیشتری هستند.
اگر درسهای قبلیِ این فصل را خوانده باشید، حتماً متوجه شدهاید که ما برای ذخیرهسازی دادهها در دادهکاوی از ماتریس استفاده میکردیم. مثلا شکل زیر را از درسِ «کاربرد ماتریسها در دادهکاوی» به یاد بیاورید:
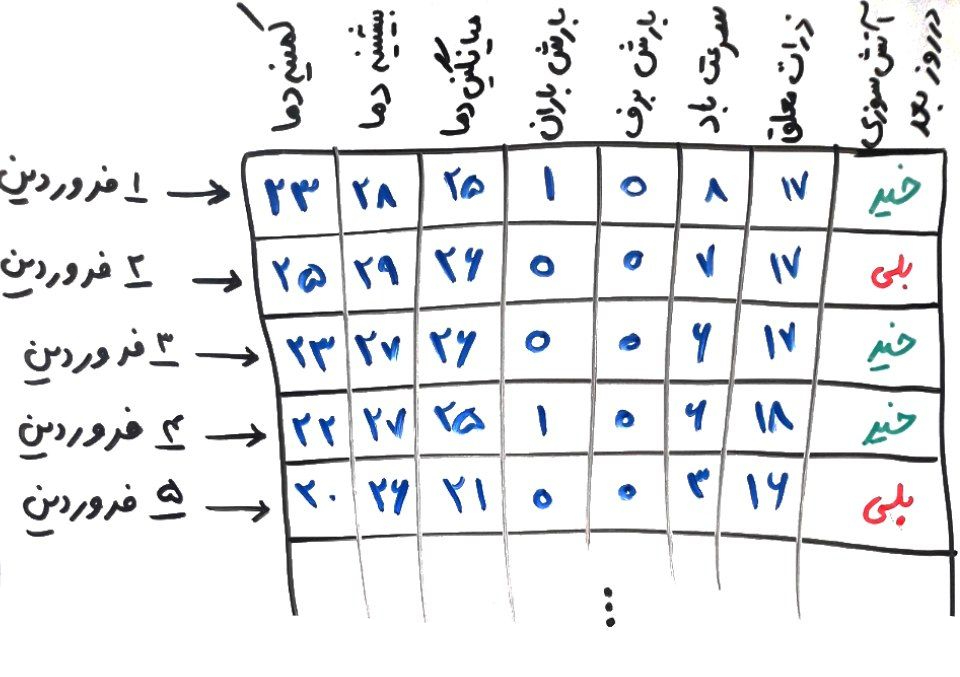
همانطور که میبینید، هر سطر یک روز را نشان میدهد و هر ستون یک ویژگی از آن روز. مثلاً در روز اول فروردین، میانگین دمای هوا ۲۵ درجه بوده است. ما میخواهیم از روی این ویژگیها متوجه شویم که آیا فردای یک روز، جنگل آتش خواهد گرفت یا خیر (که این کار وظیفهی الگوریتم یادگیری ماشین است). حتماً میدانید که هر کدام از این ستونها، برای پیشبینیِ اینکه فردا آتشسوزی خواهیم داشت یا خیر موثر هستند ولی برخی کمتر و برخی بیشتر تاثیر دارند. یکی از روشهایی که میتوانیم بفهمیم که کدام ستون (ویژگی) تاثیر بیشتری دارد (یعنی اطلاعات بیشتری در خود قرار داده است)، همین روش SVD است. در واقع SVD میتواند برای مثال این ۷ ویژگی را به صورت فشرده شده به ۳ ویژگی تبدیل کند و به این صورت، حجم ذخیرهسازی و عملیاتی که الگوریتم باید بر روی آن انجام دهد، به مراتب کمتر میشود. اینکه چگونه این روش انجام میشود را در فصلهای پیشرو خواهیم دید.
البته که محاسبهی SVD برای یک ماتریسْ دارای پیچیدگیِ زمانی خوبی نیست ولی به هر حال این روش یکی از روشهای شناخته شده در کاهشِ ویژگیها در دادهکاوی میباشد و کاربردهای دیگرِ آن نیز در دروس بعد آشنا میشویم. در زبانهای برنامهنویسی مانند Python و R میتوانید کتابخانههای مختلفی را پیدا کنید که این عملیات را به سادگی برای شما انجام میدهند.

- ۱ » عدد (Scalar)، بردار (Vectors)، ماتریس (Matrix) و تنسور (Tensor) چیست؟
- ۲ » ماتریسها و کاربرد آنها در دادهکاوی و یادگیری ماشین
- ۳ » نرم (Norm) بردار یا ماتریس چیست؟
- ۴ » انواع ماتریس و ویژگیهای مختلف آنها
- ۵ » چرا ماتریسها در علوم داده مهم هستند؟
- ۶ » معیارهای فاصله (Distance Measures) در یادگیری ماشین
- ۷ » بردار ویژه (Eigen Vector) و مقدار ویژه (Eigen Value) برای یک ماتریس
- ۸ » Singular Value Decomposition یا همان SVD در ماتریس چیست؟
- ۹ » ماتریس کواریانس (Covariance) و ماتریس همبستگی (Correlation) چیست؟
- ۱۰ » آنالیز مولفه اصلی (Principal Component Analysis) یا همان PCA چیست؟
- ۱۱ » دستگاه معادلات خطی (System of Linear Equations) در ماتریسها
سلام ممنون
ولی چرا اینقدر پیچیده س 🙁
لطفا کمی کامل تر توضیح دهید
کاربردهای دیگه ش رو کجا توضیح دادید؟ لینکش رو اضافه کنید لطفا
سلام
برای من مفید بود. ممنونم.
حضور انسانهایی مثل شما واقعا نعمته… ممنونم از سایت عالیتون
چگونه از svd برای کاهش ابعاد ماتریس وقوع در متن کاوی استفاده می شود.
از استاد میردهقانی بپرس
با سلام
به نظر همانطور که در مثال توضیح داده شده این تجزیه یه مشکلاتی دارد. u باید ماتریس m در m باشد (در مثال هم همینطوره) s نیز باید n در m باشد و ماتریس v باید n در n باشد و همچنان که در مثال خودتان مشهود است v متقارن نیز نمی باشد بلکه متعامد باید باشد.
A یک ماتریس m×n.
U یک ماتریس متعامد m×m.
S یک ماتریس قطری m×n.
V یک ماتریس متعامد n×n است.
سلام. ماتریس u وقتی m*n است چه جوری میتواند متقارن باشد؟
ممنون.
پاسخ مثال ماتریسی که بالا زدید، اشتباهه.
با کد زیر تو متلب میتونین جواب درست رو ببینین:
A = [2 -2 1;5 -2 1]
svd(A) = [u,s,v]
عالی بود