

در دورهی جبرخطی (Linear Algebra) بعد از مباحثِ پایهی ماتریسی، بحثهای کاربردیتری مانند SVD و ماتریس همبستگی را مطرح کردیم که به طورِ مستقیم در بسیاری از مسائل واقعی دنیای صنعت و تحقیقات علمی کاربرد دارند. در این درس میخواهیم به یکی از مباحثِ اصلی و پیشرفتهتر در جبر خطی بپردازیم که به آن آنالیز مولفه اصلی (Principal Component Analysis) یا به اختصار PCA میگویند. همچنین کاربرد آن را در مسائلِ حوزهی علومداده (Data Science) مشاهده کنیم.
یکی از کاربردهای اصلیِ PCA در عملیاتِ کاهشِ ویژگی (Dimensionality Reduction) است. PCA همانطور که از نامش پیداست میتواند مولفههای اصلی را شناسایی کند و به ما کمک میکند تا به جای اینکه تمامیِ ویژگیها را مورد بررسی قرار دهیم، یک سری ویژگیهایی را ارزشِ بیشتری دارند، تحلیل کنیم. در واقع PCA آن ویژگیهایی را که ارزش بیشتری فراهم میکنند برای ما استخراج میکند (اگر نمیدانید ویژگی یا بُعد چیست، حتما درس ویژگی چیست را خوانده باشید).
اجازه بدهید با یک مثال شروع کنیم. فرض کنید یک فروشگاه میخواهد ببیند که رفتار مشتریانش در خریدِ یک محصول خاص (مثلا یک کفش خاص) چطور بوده است. این فروشگاه، اطلاعات زیادی از هر فرد دارد (همان ویژگیهای آن فرد). برای مثال این فروشگاه، از هر مشتری ویژگیهای زیر را جمعآوری کرده است:
سن، قد، جنسیت، محل تولد شخص (غرب ایران، شمال ایران، شرق ایران یا جنوب ایران)، میانگین تعداد افراد خانواده، میانگین درآمد، اتومبیل شخصی دارد یا خیر و در نهایت اینکه این شخص بعد از بازدید کفش خریده است یا خیر. ۷ویژگیِ اول ابعاد مسئله ما را میساختند و ویژگیِ آخر هدف (Target) میباشد (در این باره در درس طبقهبندی صحبت کردهایم)
اگر درس ویژگی چیست را خوانده باشید میدانید که ویژگیهای بالا را میتوان برای مجموعهی داده (در اینجا مجموعه مشتریان فروشگاه) در ۷بُعد رسم کرد. حال به PCA بازمیگردیم. PCA میتواند آن مولفههایی را انتخاب کند که نقش مهمتری در خرید دارند. برای مثال، مدیرِ فروش به ما گفته است که به جای اینکه هر ۷بُعد را در تصمیمگیری دخالت دهیم، نیاز به ۳بُعد (۳ویژگی) داریم تا بتوانیم آنها را بر روی یک رابطِ گرافیکی ۳بُعدی به نمایش دربیاوریم. پس در واقع نیاز داریم ۷بُعد را به ۳بُعد کاهش دهیم. به این کار در اصطلاح کاهش ابعاد یا Dimensionality Reduction میگویند. PCA میتواند این کار را برای ما انجام دهد. PCA با توجه دادهها و دامنهی تغییراتِ هر کدام از آنها، میتواند ویژگیهایی را انتخاب کند که تاثیر حداکثری در نتیجه نهایی داشته باشند. در مثال بالا (فروشگاه)، فرض کنید ویژگی قد، تاثیر زیادی در اینکه یک فرد از فروشگاه خرید کند نداشته باشد. PCA این قضیه را متوجه میشود و در الگوریتمِ خود ویژگیِ قد را تا جای ممکن حذف میکند. در واقع در فرآیند تبدیلِ ۷ویژگی به ۳ویژگیِ نهایی (که با توجه به درخواست مدیرِ فروش به دنبال آن هستیم) PCA ویژگیِ قد را کمتر دخالت میدهد. اینگونه است که ویژگیهای مهمتر از نظر PCA وزن بیشتری در تولیدِ ویژگیهای کاهش یافته پیدا میکنند.
البته این بدان معنا نیست که در فرآیند کاهش ابعاد، PCA دقیقا همان ویژگی را حذف میکند. بلکه PCA توان این را دارد که به یک سری ویژگی جدید برسد. مثلا این الگوریتم ممکن است به این نتیجه برسد که افرادی که در شمال و غرب ایران زندگی میکنند و سنِ آنها بالای ۴۰سال است، احتمال خرید بالایی دارند در حالی که برعکس این قضیه احتمال خرید را بسیار کمتر میکند. در واقع اینجا PCA به یک ویژگی ترکیبی از محل تولد شخص و سن رسیده است. این دقیقا یکی از قدرتهای الگوریتم PCA در کار بر روی دادهها است.
حال بگذارید کمی ریاضیتر به قضیه نگاه کنیم. برای سادگی فرض کنید دادههای مشتریان ما کلا ۲بُعد دارند. سن و قد. حال (همانطور که در درس ویژگی چیست خواندید) آنها را بر روی محور مختصات نمایش میدهیم. فرض کنید شکلی مانند شکل زیر تشکیل میشود:
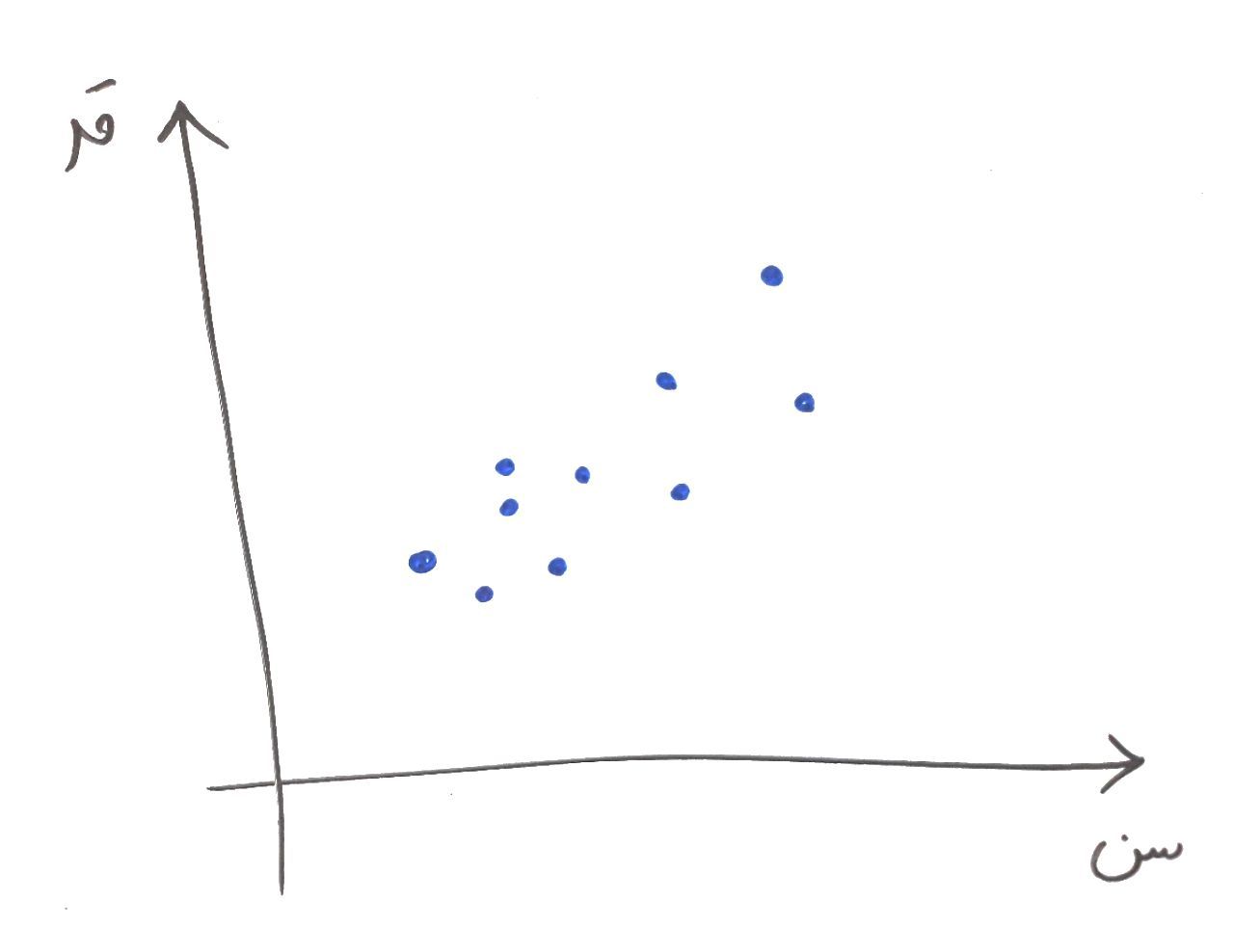
هر کدام از نقاط آبی رنگ، در مثال ما یک مشتری است که با توجه به ویژگی سن (محور افقی) و ویژگی قد (محور عمودی) در صفحه مختصات رسم شده است. همانطور که از درس بردار ویژه (Eigen Vector) به یاد دارید، بردار ویژه میتواند کمک کند تا در میان دادههای ما خطی کشیده شود که بیشترین دامنه تغییرات در امتداد آن خط رخ داده باشد. حال به تصویر زیر نگاه کنید:
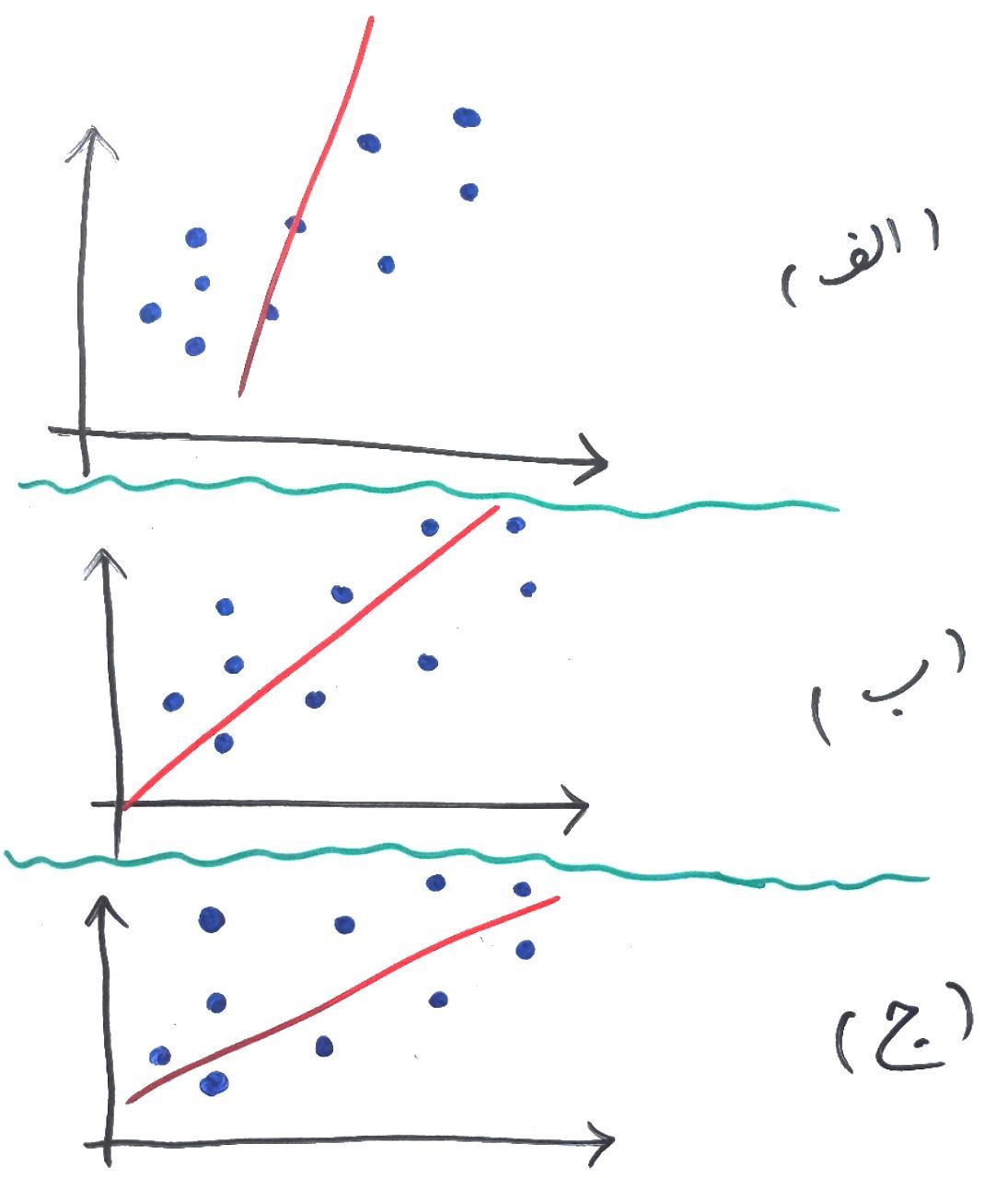
همانطور که گفتیم هر کدام از نقاط آبی رنگ، در مثالِ ما یک مشتری است که با توجه به ویژگی سن (محور افقی) و ویژگی قد (محور عمودی) در صفحه مختصات رسم شده است. فاصله هر نقطه آبی تا خط قرمز را میتوان به عنوان یک خطا (Error) در نظر گرفت و به تبعِ آن مجموعِ خطا برابر است با جمع فاصله تک تکِ نقاط آبی تا خط قرمز. به شکل زیر نگاه کنید، کدام تصویر (الف، ب یا ج) مجموع خطاهای کمتری دارند؟
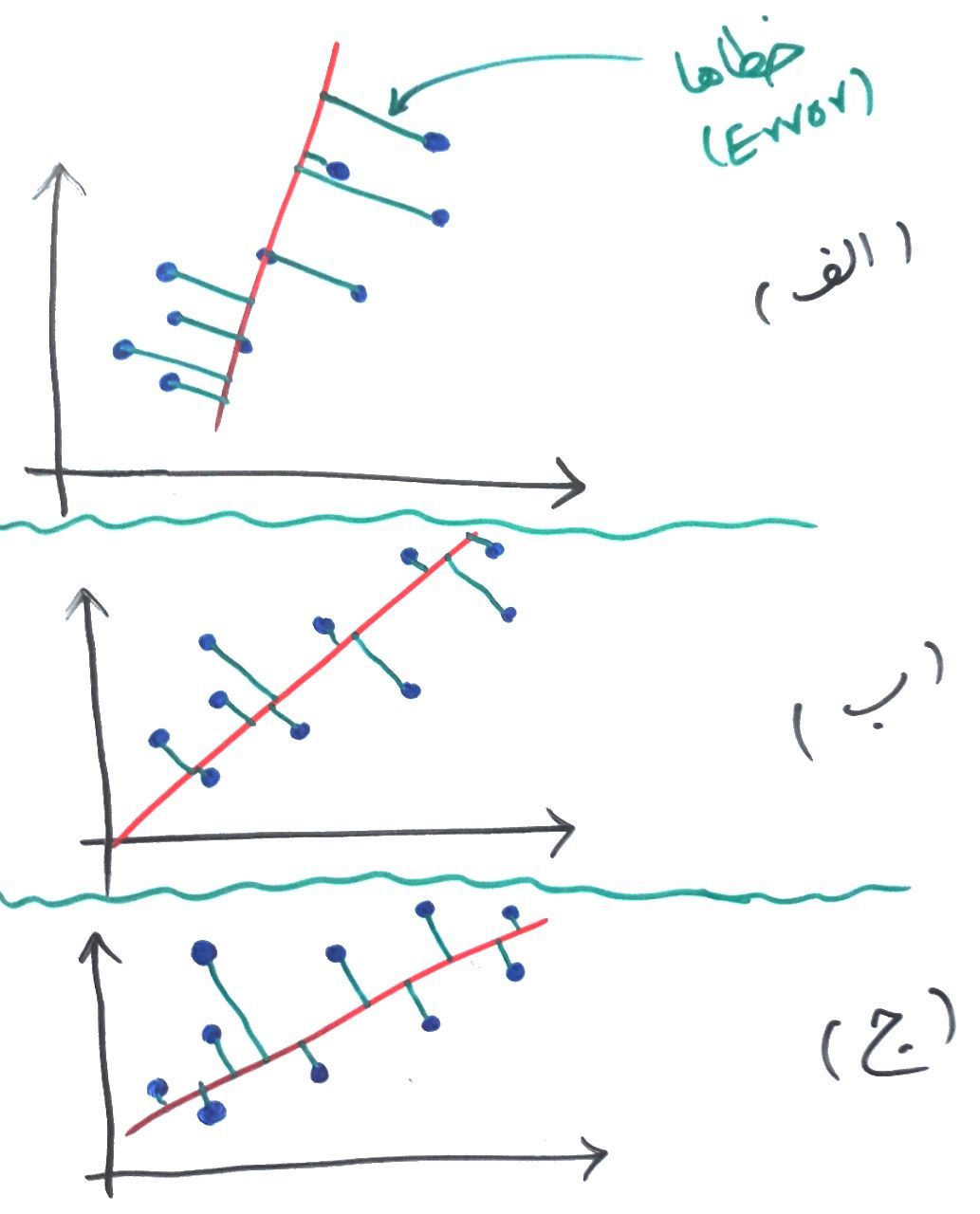
کمی دقت کنید. فاصله نقاط نسبت به خط قرمز با خط با رنگ سبز مشخص شدهاند. اگر جمع این فاصله (خطا – Error) را برای هر نمودار برابر خطای کلی دادهها نسبت به خط قرمز در نظر بگیریم، تصویرِ الف بیشترین میزان خطا را دارد و بعد از آن تصویر ب و در نهایت تصویر ج کمترین خطا را دارد. PCA به دنبال ساختنِ خطی مانند خط ج است (که در واقع همان بردار ویژه ماست) که کمترین خطا (Least Error) را داشته باشد. با اینکار هر کدام از نقاط بر روی خط قرمز نگاشت میشوند و در تصویرِ بالا که ۲بُعدی است میتوان این ۲بُعد را به ۱بُعد (که همان خط قرمز رنگ است) نگاشت کرد. در نهایت میتواند چیزی مانند شکل زیر رخ دهد:

در این مثال آخر ما ۲بُعد را به ۱بُعد کاهش دادیم. البته در مثالهای واقعی ممکن است ۱۰۰۰بُعد را به ۲بُعد کاهش دهند تا بتوان آن را بر روی یک نمودار به نمایش درآورد و این کار با با PCA انجام دهند که هم از سرعتِ معقولی برخوردار است و هم کیفیت قابل قبولی دارد.

- ۱ » عدد (Scalar)، بردار (Vectors)، ماتریس (Matrix) و تنسور (Tensor) چیست؟
- ۲ » ماتریسها و کاربرد آنها در دادهکاوی و یادگیری ماشین
- ۳ » نرم (Norm) بردار یا ماتریس چیست؟
- ۴ » انواع ماتریس و ویژگیهای مختلف آنها
- ۵ » چرا ماتریسها در علوم داده مهم هستند؟
- ۶ » معیارهای فاصله (Distance Measures) در یادگیری ماشین
- ۷ » بردار ویژه (Eigen Vector) و مقدار ویژه (Eigen Value) برای یک ماتریس
- ۸ » Singular Value Decomposition یا همان SVD در ماتریس چیست؟
- ۹ » ماتریس کواریانس (Covariance) و ماتریس همبستگی (Correlation) چیست؟
- ۱۰ » آنالیز مولفه اصلی (Principal Component Analysis) یا همان PCA چیست؟
- ۱۱ » دستگاه معادلات خطی (System of Linear Equations) در ماتریسها
Notice: تابع register_meta به طورنادرست فراخوانی شد. هنگام ثبت یک نوع متای “آرایه” برای نمایش در REST API، شما باید الگو (schema) را برای هر مورد آرایه در “show_in_rest.schema.items” تعیین نمایید. لطفاً برای اطلاعات بیشتر، اشکال زدایی در وردپرس را مشاهده کنید. (این پیام در نگارش ۵.۳.۰ افزوده شده است.) in /home2/chistio/domains/chistio.ir/public_html/wp-includes/functions.php on line 4903 Notice: تابع register_meta به طورنادرست فراخوانی شد. هنگام ثبت یک نوع متای “آرایه” برای نمایش در REST API، شما باید الگو (schema) را برای هر مورد آرایه در “show_in_rest.schema.items” تعیین نمایید. لطفاً برای اطلاعات بیشتر، اشکال زدایی در وردپرس را مشاهده کنید. (این پیام در نگارش ۵.۳.۰ افزوده شده است.) in /home2/chistio/domains/chistio.ir/public_html/wp-includes/functions.php on line 4903
سلام…ممنون از اطلاعات خوبتون
میخاستم بدونم روش PLSDA چطوری عمل میکنه و چه تفاوت ها و شباهت هایی با PCA دارد؟
ممنون میشم اگه راهنمایی کنید
با سلام . سوالی دارم درمورد روش PCA
میتونن برام حلش کنید ؟؟
با تشکر
بسیار عالی و شایسته
من پیشنهاد میکنم که برای توضیح بهتر PCA اول تبدیل wittening بعد corrolation و Normalization سپس LDA آموزش بدهید.
PCA چیزی به غیرتبدیل Wittening نیست فقط egeinvetor و egeinvalue رو به جای استخراج از کواریانس ماتریس از حاصل ماتریس Sw-1*Sb=Sb/Sw استخراج میکنند.
با تشکر خیلی خوب بود روش محاسبه این روش رو هم اگه با این زبان ساده توضیح بدین خیلی ممنون میشم
با سلام و تشکر فراوان از سایت خوب و مفیدتون.
در زیر تصویر اول نوشته شده :
“هر کدام از نقاط آبی رنگ، در مثال ما یک مشتری است که با توجه به ویژگی سن (محور افقی) و ویژگی قد (محور عمودی) در صفحه مختصات رسم شده است. همانطور که از درس بردار ویژه (Eigen Vector) به یاد دارید، بردار ویژه میتواند کمک کند تا در میان دادههای ما خطی کشیده شود که “””بیشترین””” دامنه تغییرات در امتداد آن خط رخ داده باشد. حال به تصویر زیر نگاه کنید”
=================================================================
فکر کنم کلمه بیشترین اشتباهه.و این درست باشه که :
“بردار ویژه میتواند کمک کند تا در میان دادههای ما خطی کشیده شود که “””کمترین””” دامنه تغییرات در امتداد آن خط رخ داده باشد.
این مبحث در حوزه ی یادگیری ماشین هست ؟ ببخشید میپرسم چون دارم در تحقیقم استفاده میکنم پرسیدم
سلام
بله، در حوزهی یادگیری ماشین و آمار و احتمالات قرار میگیره
بسیار عالی و خسته نباشید بابت مطالب خوب . سر بلند و پیروز باشید
خواهشمندم سوالمو سریع جواب بدید چون مبهم هست . آیا از روش pca برای مسئله ای که ۲ ویژگی اصلی داره هم میشه استفاده کرد؟ مثلا برای تشخیص بدافزار اندروید که حیاتی ترین ویژگی مجوز ها و api هاست و این دو بعد حرف شدنی نیستن میتونیم از pca استفاده کنیم ؟؟؟؟
بله مشکلی نداره
البته دو بعد که دیگه نیاز خاصی به کاهش بعد نداره
واقعا عالی بود. ممنونم بابت وقتی که میزارید
دمتون گرم
سلام
میشه در مورد ZCA هم توضیح بدین.
سپاس فراوان
با سلام
بله حتما
در مورد این روشها در سرفصلی جداگانه به اسم «کاهش ابعاد» صحبت خواهیم کرد
سپاس فراوان
سلام واحترام
روش pca یک مرحله از محاسبه روش efa میباشد؟ یا هر دوی این دو دو روشی متفاوت هستند؟
با سلام ممنون و سپاسگزارم بابت نحوه بیان عااااالی . موفق باشید همییییشه
سلام
ممنون از دوره خوبتون
ایا دوره جبر خطی ادامه پیدا میکنه؟ چه زمانی به روز میشه در این صورت؟
باسپاس
استاد شما بی نظیرید ازتون خیلی چیزا یاد گرفتم تدریستون دانشتون عالیه…دوره داده کاوی از سون لرن رو دارم باهاتون می گذرونم فوق العادس ممنونم ازتون.
شاید من به اندازه کافی به ریاضی مسلط نیستم. شایدم چون برنامه نویسم و سعی میکردم نکات رو با مسائل واقعی منطبق کنم چیزی نفهمیدم ولی حس کردم توصیحتون افتضاح بود.
.
بیاین فرض کنیم میخوام از روی درامد n ماه گذشته، درامد ماه بعدی یک کسب و کار رو حدس بزنیم.
چند تا مولفه داره.
مثلا فروردین هر سال درامد بالا میره و اردیبهشت هر سال درامد افت میکنه.
سال به سال هم متفاوته. مثلا امسال که تحریم ها شدید تر هست احتمالا افت درامد داریم.
حالا میخوایم ببینیم تاثیر ماه چند درصده؟
تاثیر سال چند درصده؟
حالا اولا که اون ماتریس n*n چی میشه؟ (نمیدونم)
فرض کنیم ما اطلاعات دوماه گذشته رو داریم. ماتریسمون میشه ۲*۲
ولی اون خط الف و ب و ج رو نمیدونم چطوری محاسبه کردین؟
بنظر من خیلی گنگ بود توضیحاتتون
عالی ی ی ی ی ی ی ی ی ی ی ی ی ی ی …
با عرض سلام و خسته نباشید بابت آموزش های عالیتون
فقط یک نکته هست که من فکر میکنم به اشتباه بیان شده
میزان خطا عمود بر خط رگرشن نیست؛ بلکه فاصله عمودی هر نقطه تا خط رگرشن است.
با تشکر از مطالب مفیدتون