

KNN شاید سادهترین الگوریتم در بحثِ طبقهبندی باشد. میخواهیم با یک مثال بسیار ساده شروع کنیم. فرض کنید شما یک فروشگاهِ مواد غذایی و دو دسته مشتری دارید، مشتریانِ دسته اول، کسانی هستند که بیشتر از ۱۰۰ هزار تومان در هر بار مراجعه از شما خریداری میکنند و دستهی دوم مشتریانی هستند که در هر مراجعه معمولاً کمتر از ۱۰ هزار تومان خرید میکنند. شما که فروشندهی با تجربهای هستید، به سبب چند سالی که در این مغازه فعالیت دارید میدانید که مشتریان دستهی اول خانمهایی هستند که سن بالای ۴۰ سال دارند و با اتومبیل به فروشگاه شما میآیند (مثلاً در مراجعهی آنها به این الگو دقت کردهاید). و دستهی دوم، یعنی همان مشتریانی که کمتر از ۱۰ هزار تومان از شما خریداری می کنند. معمولاً آقایانی هستند که سن زیر ۲۵ سال دارند و بدون اتومبیل به فروشگاه میآیند. حال فرض کنید، یک مشتری جدید به فروشگاه آمده است. این شخص یک خانم ۴۵ ساله است که با اتومبیلِ خود به فروشگاه آمده. شما این مشتری جدید را در کدام دسته (با توجه به مشتریان قبلی) قرار میدهید؟ انتظار دارید که این شخص چقدر از شما خرید کند؟
قطعاً بدون فکر کردن، دستهی اول را برای پاسخ به سوالِ بالا انتخاب میکنید. دلیل آن بسیار ساده است. این خانم ۴۵ ساله با اتومبیل، بسیار نزدیکتر به مشتریانِ دستهی اول است تا مشتریانِ دستهی دوم (دستهی دوم، آقایانی بودند که زیر ۲۵ سال سن داشتند و بدون اتومبیل به فروشگاه میآمدند). واژه نزدیکتر، در واقع پایهی عملیاتِ طبقهبندیِ K نزدیکترین همسایه میباشد. در این الگوریتم، هر کدام از نمونههای جدید (مثلاً مشتریهای جدید) با تمامی نمونههای قبلی مقایسه میشوند و به هر کدام از نمونههای قبلی که نزدیکتر باشند، به آن دسته از نمونهها تعلق می گیرند. این دقیقاً همان کاری است که در مثال اول توسط فروشندهی با تجربهی فروشگاه مواد غذایی انجام شد.
حال که مثال اول را درک کردید، اجازه بدهید به یک مثال علمیتر بپردازیم. فرض کنید شما مدیریت یک بانک را بر عهده دارید و میخواهید از بینِ کسانی که درخواستِ وام کردهاند، آن هایی را انتخاب کنید که به احتمال زیاد میتوانند وام خود را بازگردانند. فرض کنید برای این کار یک دیتاست (dataset) از مشتریانِ قبلیِ خود که وام گرفتهاند را آماده کردهاید و به هر کدام از این مشتریانْ یک برچسبِ بله (یعنی توانستهاند وام را بازگردانند) و خیر (یعنی نتوانستهاند وام را بازگردانند) نسبت دادهاید. توجه کنید که اینها مشتریانِ قبلی شما هستند که وضعیت برگرداندنِ وام توسط آنها مشخص شده است. هر کدام از مشتریهای شما هم ۲ ویژگی دارد. ویژگی اول: خانه از خود دارد یا خیر (۰ به معنیِ خانه نداشتن و ۱ به معنیِ داشتنِ خانه از خود است)؟ ویژگی دوم: چند سال است که مشتری بانک است (یک عدد بزرگتر از ۰)؟ هر کدام از این ویژگیها برای تمامیِ مشتریان تکرار می شوند. نگاهی به شکل زیر بیندازید (یک دیتاست با ۶ نمونه و ۲ بٌعد و دارای برچسب):
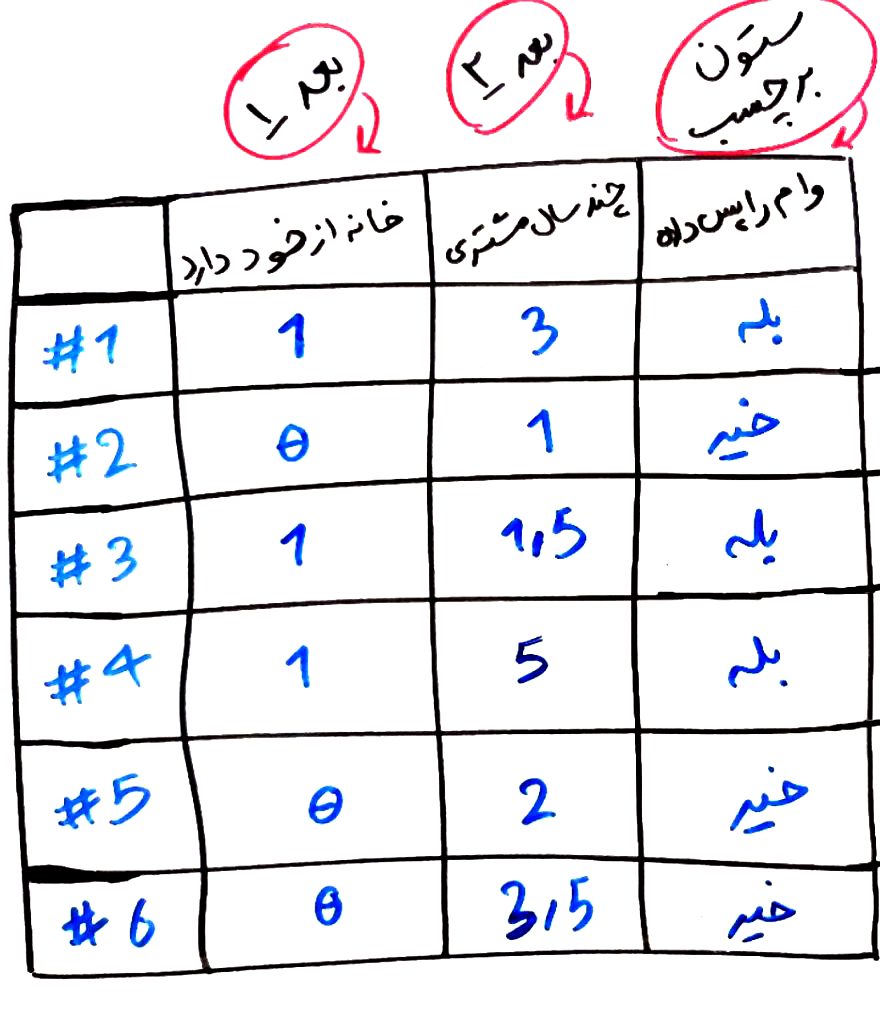
همانطور که میبینید ما ۶ مشتری داریم که هر کدام ویژگیهای خاصِ خود را دارند. مثلا مشتریِ اول خانه از خود دارد و ۳ سال است که مشتریِ بانک بوده و توانسته وام خود را پس بدهد. مشتریِ دوم خانه از خود ندارد، ۱ سال است مشتری بانک است و نتوانسته وام خود را پس دهد و به همین ترتیب برای بقیه مشتریان.
اجازه بدهید این مشتریان را بر روی یک نمودار رسم کنیم. توجه کنید که در اینجا دو ویژگی داریم، پس دو بُعد وجود دارد. ما محور افقی را خانه داشتن و محور عمودی را مدت زمان مشتریِ بانک بودن به سال، در نظر گرفتیم. هر کدام از نمونهها، اگر توانسته باشند وام خود را پس دهند، با رنگ سبز و اگر نتوانسته باشند وام خود را پس دهند با رنگ قرمز مشخص شدند. پس اگر بخواهیم جدول بالا را بر روی نمودار رسم کنیم مانند شکل زیر است:
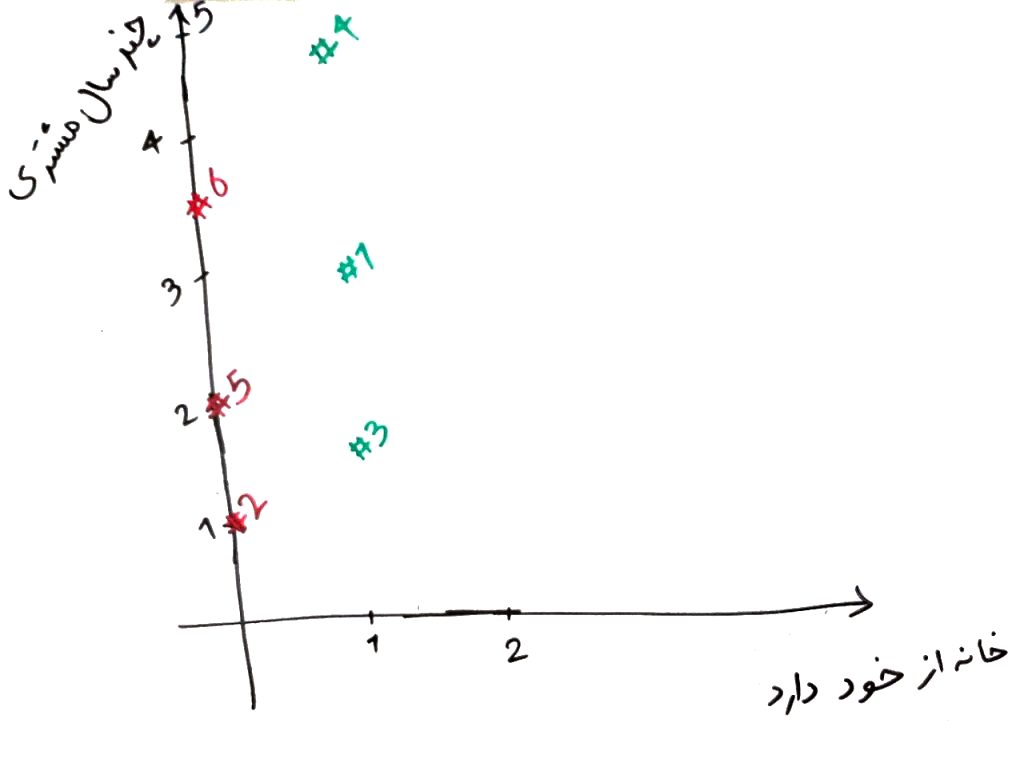
هر نقطه (#) بر روی این نمودار یک مشتری را نمایش میدهد. همان طور که میبینید یک تفکیک خوب بین مشتریانی که توانستهاند وام خود را پس دهند با کسانی که نتوانستهاند وام را پس دهند، وجود دارد. حال فرض کنید دو مشتریِ جدید با ویژگیهایی مطابق با جدول زیر متقاضیِ جدیدِ وام هستند و که میخواهیم تصمیم بگیریم به آن ها وام بدهیم یا خیر
| چند سال مشتری بانک است | خانه از خود دارد | |
| ۲/۵ | ۱ | new_1 |
| ۲ | ۰ | new_2 |
در الگوریتم KNN ابتدا بایستی فاصلهی هر نمونهی جدید را با نمونههای گذشته مقایسه کنیم. اما این مقایسه چگونه باید باشد؟ فرض کنید در شکل بالا میخواهیم مشتری new_1 را با مشتریهای قبلی مقایسه کنیم و فاصلهی این مشتری را با مشتریانِ دیگر به دست آوریم. برای این کار باید هر کدام از ویژگیهای مختلفِ مشتریِ جدید را با همان ویژگیهای موجود در یک مشتریِ قدیمی مقایسه کنیم (و از هم دیگر کم کنیم). سپس حاصلِ این کَمکردنها را با یکدیگر جمع کنیم. بگذارید برای نمونه فاصله مشتری new_1 را با تمامی ۶ مشتری قبلی محاسبه کنیم:
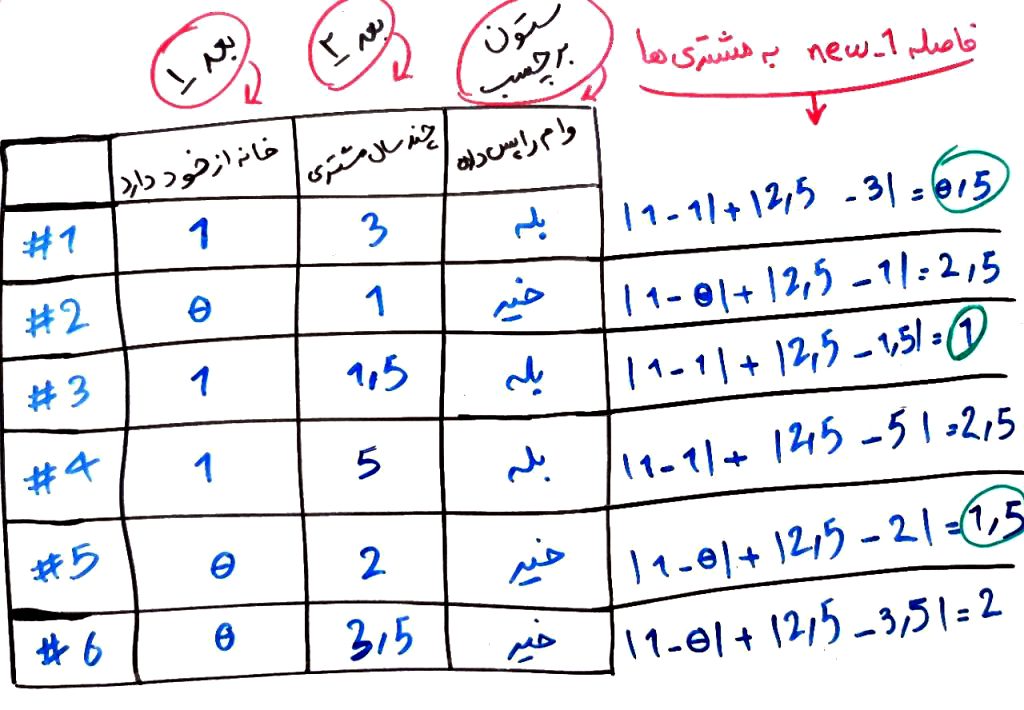
همانطور که مشاهده میکنید، هر کدام از ویژگیها را برای هر مشتریان از هم کم کردهایم. یعنی بُعد ۱ را برای مشتریِ جدید از بعد ۱ برای تکتکِ مشتریان قبلی کم کردیم و بُعد ۲ را نیز به همین ترتیب از بُعد ۲ برای تکتکِ مشتریان قبلی کم میکنیم. برای اینکه عددِ منفی به دست نیاید، قدر مطلق آنها را حساب می کنیم و سپس تمامیِ این کمکردنها را با هم جمع کرده ایم. در واقع بُعدهای مختلف را نظیر به نظیر با هم مقایسه کردهایم. به این کار، یعنی به دست آوردن تفاضل بُعدهای نظیر به نظیر و سپس جمع آنها، محاسبه فاصلهی منهتن میگویند که یکی از معیارهای فاصله برای دادههای چند بعدی، مانند همین مثال ما است. معیارهای فاصله دیگر نیز وجود دارد. مثلاً معیار اقلیدسی و یا معیار مینکوفسکی که فرمولهایی شبیه به هم دارند و در درسی جدا به هر کدام از این معیارها خواهیم پرداخت.
همان طور که میبینید فاصله مشتری new_1 برای ۶ مشتری در شکل بالا محاسبه شده است. اگر بخواهیم ۳ مشتریِ نزدیکتر به این مشتریِ جدید، از مشتریان قبلی را انتخاب کنیم، مشتریهای شماره ۱ و ۳ و ۵ هستند (که کمترین فاصله را در بین مشتریان دیگر به این مشتریِ جدید دارند) که دوتای آن ها توانستهاند وام را پس دهند و یکی از آن ها خیر. پس این مشتری نیز احتمالاً میتواند وام خود را پس دهد. این روش همان روش KNN است. در اینجا مقدار K برابر ۳ بود، یعنی ۳ مشتریِ نزدیک به مشتریِ جدید را انتخاب کردهایم و برچسبِ اکثریت این ۳ مشتری را به عنوان برچسب برای مشتریِ جدید نیز درج میکنیم. مثلاً اینجا چون برچسبِ اکثریت، بازگرداندنِ وام بود (۲ تا بلی در مقابل یک خیر) پس این مشتریِ جدید نیز به عنوانِ کسی که میتواند وام را برگرداند برچسب گذاری میشود. در واقع الگوریتمِ KNN با توجه به مشتریانِ قبلی،میتواند یک مشتریِ جدید را (که برچسب واقعی او را نمیداند) پیشبینی کند. اگر بخواهیم بر روی تصویر نیز نمایش دهیم، مشاهده میکنید که مشتری جدید new_1 به مشتری های قبلیِ ۱ و ۳ و ۵ نزدیکتر از بقیه بود.
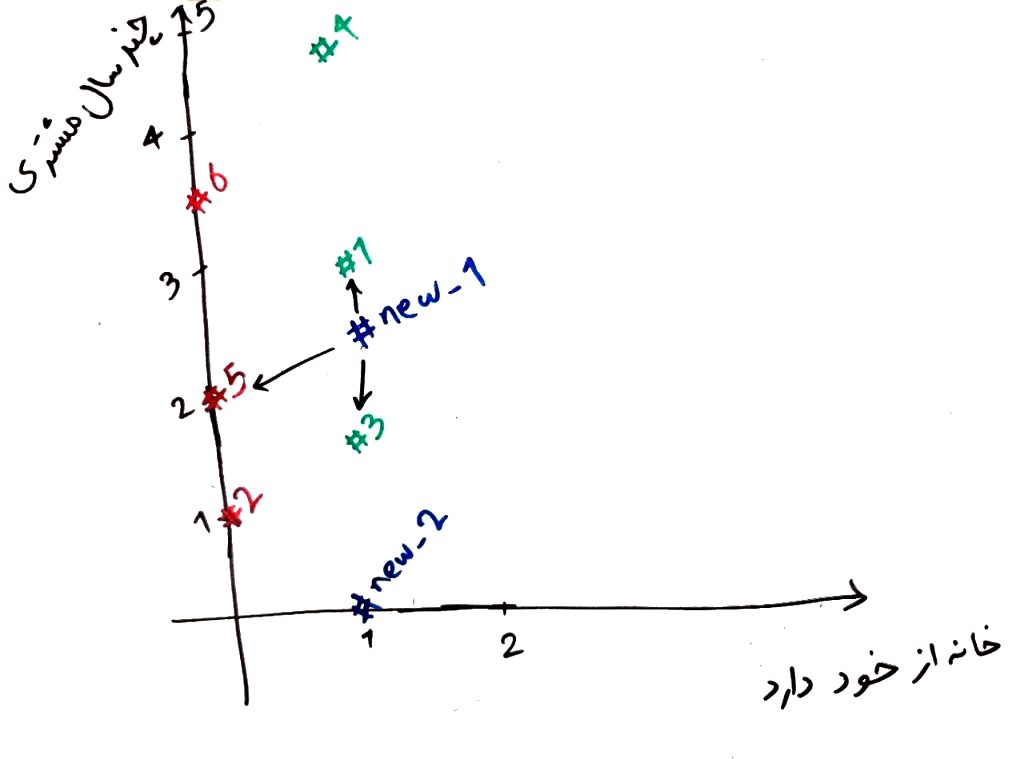
تمرین: فاصله مشتری new_2 را با ۶ مشتری قبلی مقایسه کنید. اگر K را برای الگوریتم KNN برابر ۳ قرار دهیم، آنگاه برچسب مشتری new_2 چه می شود؟ آیا این شخص میتواند وام خود را پس دهد یا خیر؟
همان طور که گفتیم الگوریتمِ KNN یکی از سادهترین الگوریتمهای دادهکاوی و طبقهبندی است. این الگوریتم عملیات طبقهبندی را به صورت ساده انجام داده و نتایجِ قابل اطمینانی به عنوان پیشبینی برمیگرداند. البته در اینجا ما به صورت ساده به دو بعد از یک مثال اشاره کردیم (مشتری خانه دارد یا خیر و اینکه چند سال است که مشتری بانک بوده است). در مسائل دنیای واقعی ممکن است ابعادِ بسیار بیشتری وجود داشته باشد. این مسائل را دیگر نمیتوان روی بردارهای عمودی و افقی به صورت ساده رسم کرد و در واقع مسئلههایی در فضای ۳ بعدی یا بیشتری میشوند. البته تجسم کردن آن از لحاظ فیزیکی قابل شکلسازی نیست ولی در ذهنِ خود به راحتی میتوانید این فضاها را تجسم کنید. مثلاً به جای اینکه در اینجا مشتری دو بُعد داشته باشد میتواند ۱۰ بعد داشته باشد که هر کدام یک ویژگیِ مشتری را نمایش میدهد.

- ۱ » الگوریتم K نزدیک ترین همسایه (KNN)
- ۲ » درخت های تصمیم جهت طبقهبندی (Decision Trees)
- ۳ » الگوریتم درخت تصمیم ID3 و ساختار Entropy و Gain
- ۴ » آشنایی با مفهوم Overfitting و Underfitting در طبقهبندی
- ۵ » آشنایی با مفهوم Bias و Variance در طبقهبندی
- ۶ » الگوریتم طبقهبندی درخت تصمیم C4.5
- ۷ » الگوریتم طبقه بند درخت تصمیم CART
- ۸ » طبقه بند ترکیبی (Ensemble Classifier) و مبحث Bagging و Boosting
- ۹ » الگوریتم جنگل تصادفی (Random Forest)
- ۱۰ » رگرسیون لجستیک (Logistic Regression)
- ۱۱ » مسائل طبقهبندی دودویی (binary)، چند کلاسه (Multi Class)، چند برچسبه (Multi Label) و تفاوت آنها
- ۱۲ » روش «یک در مقابل همه (One vs. All)» برای طبقهبندی دادههای چند کلاسه
- ۱۳ » روش «یک در مقابل یک (One vs. One)» در طبقهبندی
- ۱۴ » مدلهای احتمالی در مقابل مدلهای قطعی در طبقهبندی دادهها
- ۱۵ » ماتریس اغتشاش (Confusion Matrix) و معیار دقت (Accuracy)
- ۱۶ » معیار صحت (Precision)، پوشش (Recall) و معیار F
- ۱۷ » معیار کاپا (Kappa) برای ارزیابی طبقهبندیهای چندکلاسه
عالی بود. مرسی
سلام و عرض ادب و تشکر فراوان از استاد کاویانی .
خیلی خیلی عالی توضیح میدهید فقط لطفا حل مسیله با الگوریتم ها و جایگذاری اعداد و ارقام رو هم اگه امکانش هست توضیح دهید .
مانند محاسبه entropy.
با تشکرفراوان
خیلی عالی بود و ممنون
متاسفانه اصلا توضیحات قابل فهم نبود.
به طور مشخص بخوام بگم که از کجا ابهام پیش اومد …
تا قبل این پاراگراف “در الگوریتم KNN ابتدا بایستی فاصلهی هر نمونهی جدید را با نمونههای گذشته مقایسه کنیم…. ” خیلی توضیحات عالی است ولی بعد از این واضح نیست که چه می شود
در زمان پیاده سازی کار بسیار ساده است. شما یک عدد فرضی برای k در نظر بگیرید، مثلا ۵.(البته بهترین عدد به سادگی قابل محاسبه است.) در نظر گرفتن عدد ۵ به این معنی است که مدلKNN فقط ۵ نمونه ی اطراف سمپل مورد نظر را بررسی می کند و سمپل را در دسته ای قرار می دهد که بالاترین فراوانی را در آن پنج نمونه داشته باشد. توجه کنید که الزاما دادن مقادیر زیاد به k منجر به افزایش کارآیی مدل KNN نمی شود و برعکس در بسیاری موارد Accuracy مدل بسیار پایین می آید. در پکیج سایکیت لرن پایتون مدل KNN وجود دارد و استفاده از آن بسیار آسان است.
سلام آقای کاویانی عزیز
خدا خودش میدونه این مطالب ساده و قابل فهمی که منتشر می کنید چه اجر و ثوابی داره.
خدا خیرتون بده.
با این مثال هایی که می زنید قشنگ درک می کنیم.
انتخاب نامناسب ویژگی به سبب اجبار الگوریتم در محاسبه فاصله میتواند نتیجه را با خطا روبرو کند. خبرگی در موضوع مورد دسته بندی و انتخاب ویژگی منطقی و دانش اولیه نسبت به محتوا و ساخار داده ها بسیار کلیدی است.
سلام، وقت بخیر، خیلی ممنون از مطالب مفیدتون. بنده یه سوالی داشتم از خدمتتون، فرایند محاسبه فاصله منهتن زمانی که مدل توسط الگوریتم ایجاد شده و از مدل سوال پرسیده میشه اتفاق میفته یا در مرحله یاد گیری الگوریتم؟؟؟ دواقع فرایند محاسبه فاصله منهتن در مدل ایجاد شده اتفاق میوفته یا در زمان یادگیری الگوریتم؟
عالی بود
توضیح تون خیلی کامل و عالی بود.
خیلیییییییییییییی خوب و ساده توضیح میدن هیچ استادی به ما با مثال و ساده توضیح نمیده
سلام لطفا در مورد کاهش داده cnn هم توضیح بفرمایید
سلام و عرض ادب استاد عزیز
عالی و خیلی روان و کامل …… درود بر شما و خداقوت
انشاله که دوره های اموزشی کامل bigdata وmachine learning رو قرار بدید تا بتونیم کامل تهیه کنیم و از بیان شیوای شما مستفیض بشیم.
قلمتون پایدار استاد
توضیحات عالی بود، اولین بار بود بلاخره فهمیدم knn چیکار میکنه.
باعرض سلام و احترام خدمت آقای دکتر کاویانی
وقت بخیر
آقای دکتر پایان نامه بنده در زمینه داده کاوی می باشد توضیحات خیلی خوب شمار امطالعه کردم خواستم یک خواهش کنم مقاله به روز در رابطه با knn می خواستم خیلی ممنون می شوم راهنمایی بفرمایید .
بسیار عالی ممنون از توضیحاتتون
واقعا خیلی ساده و قابل فهم بیان میکنید استاد
عالی عالی عالی