

مسابقاتِ کشتی را تماشا کردهاید؟ در مسابقات کشتی هیچگاه یک فرد با وزن ۹۰ کیلوگرم را با فردی با وزن ۱۲۰ کیلوگرم رو در رو نمیکنند. در واقع هر شخص باید در محدودهی وزنِ خود کشتی بگیرد. در دادهها نیز شما نمیتوانید یک مجموعهی داده که مثلاً در بازهی بین ۰ تا ۲۰ متغیر هستند را با مجموعهی دادهای که در بازهی بین ۰ تا ۱۰۰۰۰ قرار دارد، مقایسه کنید. در واقع این دو مجموعهی داده بایستی ابتدا هم وزن شوند تا تاثیرِ یکی بیشتر از دیگر نباشد و به اصطلاح fair و منصف باشند.
اگر با درسِ ابعاد و ویژگیها آشنایی داشته باشید احتمالاً شکل زیر برای شما قابل فهم است. فرض کنید میخواهید مشتریانِ خود را بر اساس ۲ ویژگیْ خوشهبندی کنید (یعنی به دو گروهِ مختلف تقسیم کنید). ویژگیِ اول، سنِ افراد (محور عمودی) و ویژگیِ دوم، حقوقِ ماهیانهی افراد (محور افقی) است:
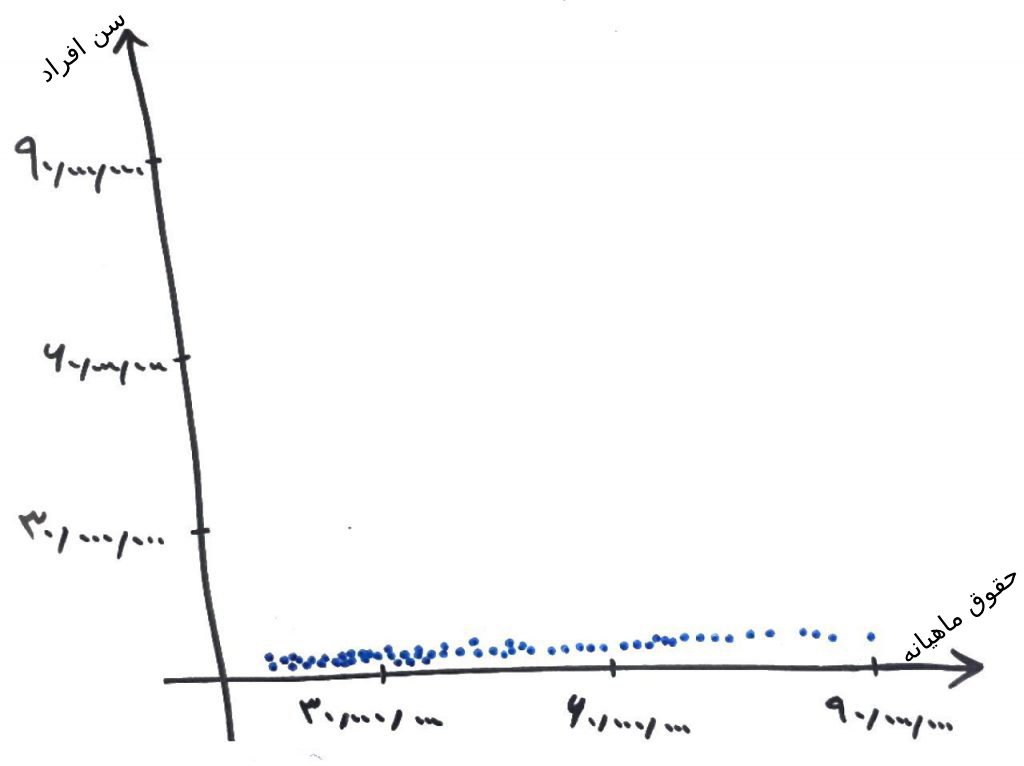
همانطور که مشاهده میکنید، دادهها در ۲ بُعد گسترش یافتهاند. بُعدِ اول (محور عمودی)، سن که معمولاً بین ۲۰ تا ۹۰ سال است و بُعدِ دوم (محور افقی) حقوقِ ماهیانه که معمولاً بین ۹،۰۰۰،۰۰۰ تا ۱۰۰،۰۰۰،۰۰۰ ریال متغیر است. حال اگر بخواهیم با استفاده از الگوریتمهای خوشهبندی، عملیاتِ خوشهبندی را بر روی این دادهها انجام دهیم، ویژگیِ حقوقِ ماهیانه (محورِ افقی)، تاثیر بسیار زیادی بر روی الگوریتم میگذارد (به خاطر اینکه بازهی بزرگتری از اعداد را در بر میگیرد و در اصطلاح scale بیشتری دارد). یعنی تقریباً ویژگیِ سن، تاثیری بر روی الگوریتم ندارد. این یکی از مواقعی است که دادهها در بازهی تغییراتِ متفاوت میتوانند تاثیر غیرِ دلخواهی بر روی همدیگر و به تبعِ آن بر روی الگوریتم، قرار دهند. پس دادهها باید در یک بازهی (range) مساوی نسبت به یکدیگر قرار بگیرند، مثلاً همه در یک بازهای مانند ۰ تا ۱ قرار داشته باشند و به این کار نرمالسازی دادهها یا data Nnormalization گفته میشود.
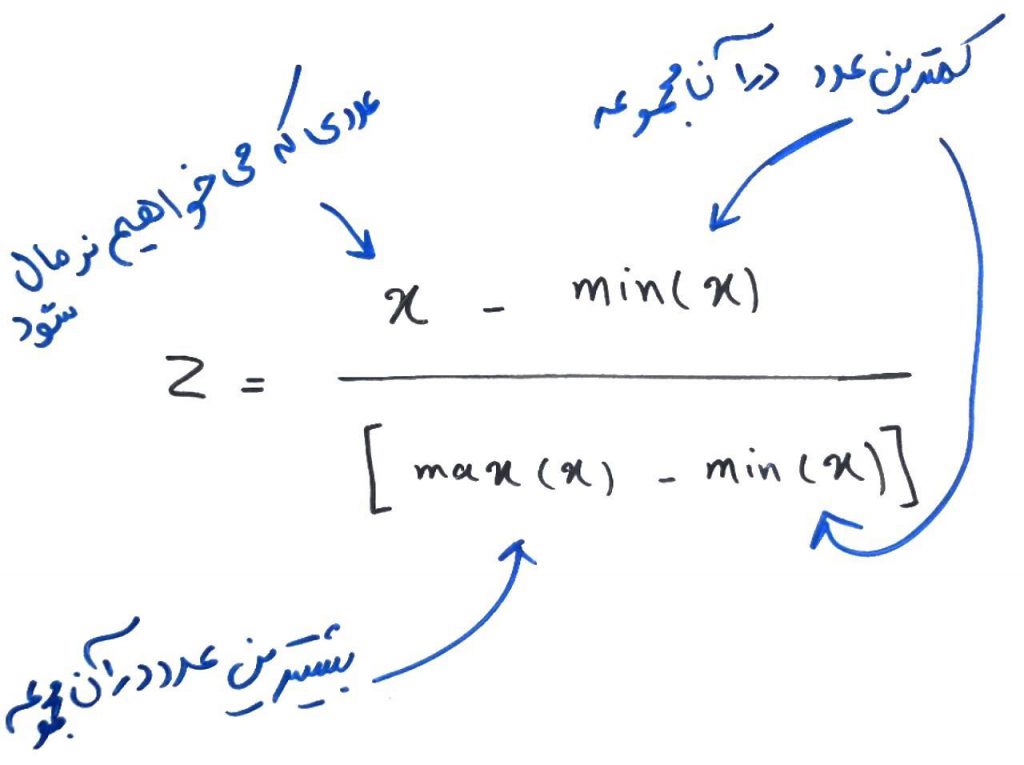
روشهای مختلفی جهتِ نرمالسازی دادهها وجود دارند که سعی داریم در دورهای جدا در مورد هر کدام به تفکیک صحبت کنیم. اما در این درس به یکی از معروفترینِ این روشها خواهیم پرداخت که به MinMaxNormalization معروف است. در این روش هر کدام از دادهها را میتوان به یک بازهی دلخواه تبدیل کرد. فرمول کلی MinMaxNormalization برای تبدیل دادهها به بازهی بین ۰ تا ۱ به صورت زیر است:
برای مثال فرض کنید دادههای سن برای افراد مختلف مانند شکل زیر است و ما میخواهیم سنِ این افراد را در یک بازهی ۰ تا ۱ قرار دهیم. با توجه به فرمول بالا نتیجه به این صورت است:
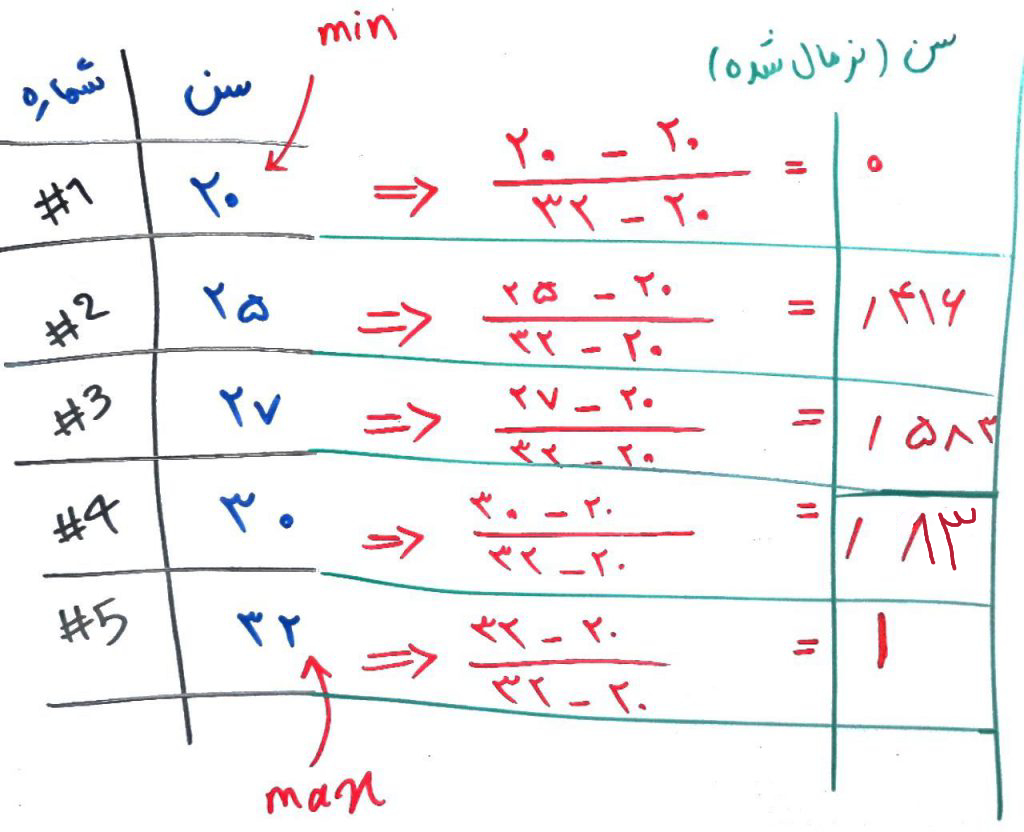
همانطور که میبینید هر کدام از نمونهها با توجه به مقادیرِ کمینه (min) و بیشینه (max) به بازهی ۰ تا ۱ تبدیل شدهاند. همین کار را میتوان برای ستونهای دیگر مانند حقوق انجام داد. شکل اولِ این درس را ببینید. با نرمالسازیِ دادهها در بازهی ۰ تا ۱، نمودار در ۲ بُعدی چیزی شبیه به شکل زیر میشود:
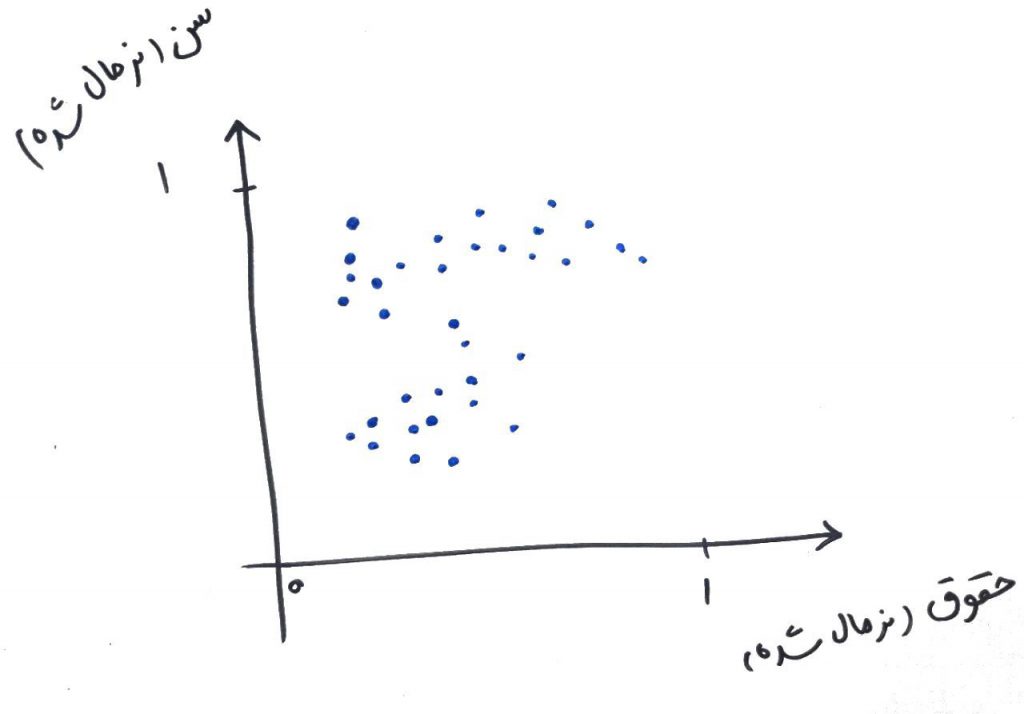
یعنی مقیاسِ هر دو ویژگی در بازهی ۰ تا ۱ قرار گرفته و حالا میتوان الگوریتمهای مختلف خوشهبندی و یا طبقهبندی را بر روی آنها به صورت منصفانه اجرا کرد.
عملیات نرمالسازی قبل از بسیاری از الگوریتمهای دادهکاوی مانند شبکههای عصبی، SVM، KNN و KMeans بایستی انجام بگیرد تا ابعادِ مختلف به صورت عادلانه توسط الگوریتم بررسی شوند و تاثیرِ یکی بیشتر از بقیه نباشد.

- ۱ » پیش پردازش دادهها (Data Preprocessing) چیست؟
- ۲ » بررسی یکپارچگی دادهها (Data Integrity)
- ۳ » نرمال کردن دادهها (Data Normalization) و انواع آن
- ۴ » تبدیل دادهها (Data Transformation) به فُرمت قالب فهم برای الگوریتم دادهکاوی
- ۵ » دادههای گمشده (Missing Values) و راهکارهای مقابله با آنها
- ۶ » تشخیص دادههای پرت و دارای نویز (Noise) و راهکار مقابله با آنها
- ۷ » انتخاب ویژگی (Feature Section) و کاهش ابعاد
- ۸ » انتخاب نمونه (Instance Selection) در پیش پردازش دادهها
ما باید در تمام الگوریتم ها داده ها را در یک بازه قرار بدیم؟
یعنی در الگوریتم های خوشه بندی باید تمام ستون ها در یک بازه قرار بگیرن؟
در روش های نظارت شده چطوری میشه یعنی اصلا لازمه؟
در برخی از الگوریتمها این نیاز هست که دادهها در یک بازهی مشخص قرار بگیرند که این بستگی به ذاتِ الگوریتم دارد. ولی معمولاً برای اینکه خیالمان راحت شود میتوان در ابتدای هر الگوریتمی، دادهها را در بازهی معین قرار داد.
بله
سلام
چطور میشه در سیسیتم توصیه گر امتیاز کاربر هدف را با در نظر گرفتن context نرمال کرد؟
سلام.بدنبال تعدادی داده نرمال برای انجام ازمونهایt,z در Rهستم.امکانش هست منبعی را معرفی کنسن تا داده جمع اوری کنم؟!
سلام
شاید این منبع به دردتان بخورد
سلام، اگر تعدادی از متغیرها باینری و تعدادی از متغیرها پیوسته باشند، نرمالسازی با استفاده از تابع z به چه صورت انجام میگیرد؟
نرمالسازی معمولاً در سطح فیلد انجام میشود. پس اگر فیلدی باینری باشد نیاز به نرمالسازی ندارد. فیلدهایی که مقادیر پیوسته دارند نیز به صورت عادی نرمالسازی میشوند.
با سلام و احترام
خیلی خوب بود.
اگر داده ها رتبه ای باشند و رتبه ها بیشتر از دو گروه باشند مثلا ۵ طبقه و اعداد ۱ الی ۵ به انها نسبت داده شود و یا کد گذاری گردد چگونه عمل می کنیم.
سلام اقای کاویانی . خدا خیرتون بده خیلی عالی توضیح میدین ما به وجود چنین افرادی در جامعه افتخار می کنیم.خدا قوت.باارزوی موفقیت
سلام برای الگوریتم ژنتیک و درخت تصمیم باید داده ها نرمال شوند؟ من یه جا خوندم که برای الگوریتم ژنتیک نباید نرمال کرد؟
سلام. ممنون از شما.
برای نرمال کردن داده ها بین ۱ و ۱- از چه فرمولی استفاده می کنیم؟
سلام
باید (feature_range=(-1,1 قرار بدید.
سلام
همونطور که میدونید ما نرمالسازی را روی نمونه انجام میدیم. حالا اگر که داده ای به نمونه ما اضافه یا کم بشه مینیمیم و ماکسیمم تغییر میکنه و ما نیاز به نرمالسازی دوباره داریم. ممنون میشم روش های دیگه نرمال کردن داده ها به نحوی که نیاز به نرمالسازی چندباره نداشته باشه مغرفی کنید.
با تشکر
متاسفانه مثال را درست حل نکردهاید چگونه ده تقسیم بر دوازده میشود ۰.۶
سلام
ممنون از تصحیحتون
درست شد
سلام. دیتاستی دارم که داده های boolean هم دارد. من قد، وزن ، درآمد و … رو با zscore نرمال کنم باید متغیرهای بولین هم نرمال کنم یا نیازی نیست؟ یا اگر بخوام داده هام رو استاندارد کنم داده های بولین هم باید استاندارد بشن؟
سلام
فرقی نمیکند، میتوانید آنها را هم نرمالسازی کنید یا نکنید. در نتیجه تفاوتی ندارد
با سلام
چه موقع باید بدانیم از استانداردسازی استفاده کنیم یا نرمال کردن داده؟
سلام
معمولاً تمامیِ دادهها را میتوان قبل از انجام عملیات داده کاوی و یادگیری ماشین، هم استاندارد و هم نرمال میکنند. مثلاً اول نرمال میکنند و سپس نرمال شده را استاندارد میکنند یا بالعکس
سلام
وقتی داده ها به صورت timeseries هستند و ماکزیمم و مینیمم کل مشخص نیست چطور می تونیم نرمال سازی کنیم؟
یکی از راهها استفاده از z-score است که به جای ماکزیمم و مینیمم از انحراف استاندارد و میانگین تخمینی استفاده میکند
سلام من میخواستم برای اعتبار سنجی فیچر هام از روش Anova استفاده کنم. برای استفاده از Anova هم باید داده ها از توزیع نرمال پیروی کنند. داده های من مجموعه ای از ویدئو های فیلم برداری شده از ۴ نوع خودرو از زوایای مختلف هست. ولی از اونجایی که طبق آزمون کولموگروف اسمیرنوف ، داده های من از توزیع نرمال پیروی نمی کنند نتونستم از Anova استفاده کنم. حالا سوال من این هست که اولا راهی هست که داده ها را به حالت توزیع نرمال درآورد و دوما اگر این امکان وجود ندارد آیا استفاده از روش MSE به جای Anova روش مناسبی هست یا خیر؟ با تشکر از سایت خوبتون.
عالی بود مرد 👍
سلام و خسته نباشید.
موضوع پروژه ی کارشناسی من، داده کاوی هست و میخوام با روشMinMax داده های خودمو که داده های بزرگی هست رو نرمال کنم.آیا زدن کد این روش در sql امکان پذیر هست؟ من هرچی سرچ کردن کدی پیدا نکردم که این روش رو پیاده سازی کنه روی مجموعه ی بزرگی از داده.امکانش هست راهنمایی کنید؟
سلام
https://stackoverflow.com/a/16399912
وقتتون بخیر
آیا نتایج استفاده از روش درصدی یا نرم اقلیدسی در نرمالسازی متفاوت هست؟؟میشه توضیح بدید؟ممنون
سلام جناب دکتر یه سوال وقتی داده ها نرمال باشه تو بازه ۰ و ۱ مقدار d در مدل Arima به چه صورت میشود ممنون میشم لطف کنید جواب دهید
سلام وقت بخیر. به روی دیتاست IDRID که مربوط به تصاویر شبکیه چشم هست مطالعه میکنم و قصد دارم ضایعه اگزودا رو بخشبندی کنم. در مراحل پیشپردازش نیاز به نرمال سازی کانالهای رنگی به صورت جداگانه دارم اما نمیدونم از چه روشی اینکار رو بکنم. و با توجه به اینکه رنگ ضایعه تقریبا زرد هست و شدت روشنایی در کانال قرمز بیشتره، کمی گیج شدم. ممنون میشم من رو راهنمایی کنید.
در رابطه با این پیشپردازش مقالهای هم هست که اگه مایل باشید براتون ارسال میکنم.
سلام و وقت بخیر
آیا همیشه نرمال سازی روی داده ها باعث بهبود نتایج میشه ؟
بنده در حال ظراحی مدل برای کار رگرسیون هستم(با داده های عددی و پیوسته )، آیا حتما باید نرمال سازی انجام بشه ؟
چون من وقتی داد هارو نرمال میکنم دقت کاهش پیدا میکند ، در حالی که بدون نرمالسازی دقت بالاتر است
ممنون
سلام
تضمینی نیست، ولی در بسیاری از مواقع نرمالسازی باعث بهبود میشه
با سلام و احترام در مجموعه ای کار میکنم که چند تا دیتا داریم اعم از تعداد مخاطبین تعداد انتقاد و مقدار ریالی فروش که به عنوان مثال ۱۵ زیر مجموعه داریم و می خواهیم عملکرد این ۱۵ زیر مجموعه را با هم قیاس کنیم که مثلا عملکرد مجموعه ۱ اگر ۱۰۰۰ مخاطب با ۵ انتقاد نسبت به مجموعه ای که ۱۰۰۰۰ مخاطب با ۱۵ انتقاد دارد و به همین ترتیب تا آخر و در نهایت به این نتیجه برسیم که مجموعه با مخاطب کم و انتقاد کم آیا نسبت به مجموعه ای که مخاطب زیاد دارد عملکرد آنها نسبت به هم منظور ۱۵ زیر مجموعه دیگر چگونه است. ما اول تعداد کل مخاطبین ۱۵ مجموعه را جمع بستیم سپس تقسیم بر تعداد کل انتقادات کردیم که عدد n را بدست آوردیم سپس تعداد کل مخاطب مجموعه ۱ را بر تعداد انتقاد آن مجموعه تقسیم کردیم و n 1 را بدست آوردیم سپس n را بر n1 تقسیم کردیم و n3 حاصل شد و به همین ترتیب تا ۱۵ مجموعه محاسبه انجام شد بعد تمام اعداد بدست آمده را با هم قیاس کردیم و اعداد را در جدول بسیار ضعیف تا بسیار عالی تقسیم بندی کردیم . ولی با کمی شبهه خواستیم با نرمال سازی اعداد نیز استفاده کنیم ولی نهایتاً نتوانستیم به ارزیابی عملکرد برسیم و با هم قیاس کنیم ممنون میشم راهنمایی بفرمایید.